
【论文复现】Eyes Tell All_Irregular Pupil Shapes Reveal GAN-generated Faces
最近在做信安赛(AI数字人实时检测),尝试实现真人生物特征检测,找到一篇2022年的文章,尝试复现
论文:Eyes Tell All: Irregular Pupil Shapes Reveal GAN-generated Faces
参考博客:
文章概述
一句话总结全文:从两只眼睛中提取瞳孔并分析它们的形状,可以有效区分GAN生成的人脸和真实的人像照片。
对于一个普遍意义上健全的人来说,瞳孔的形状是近乎圆形的。然而,在GAN生成的眼睛部分,可以观察到明显的伪影和不一致,如瞳孔的边界不是椭圆形的。如下图所示:
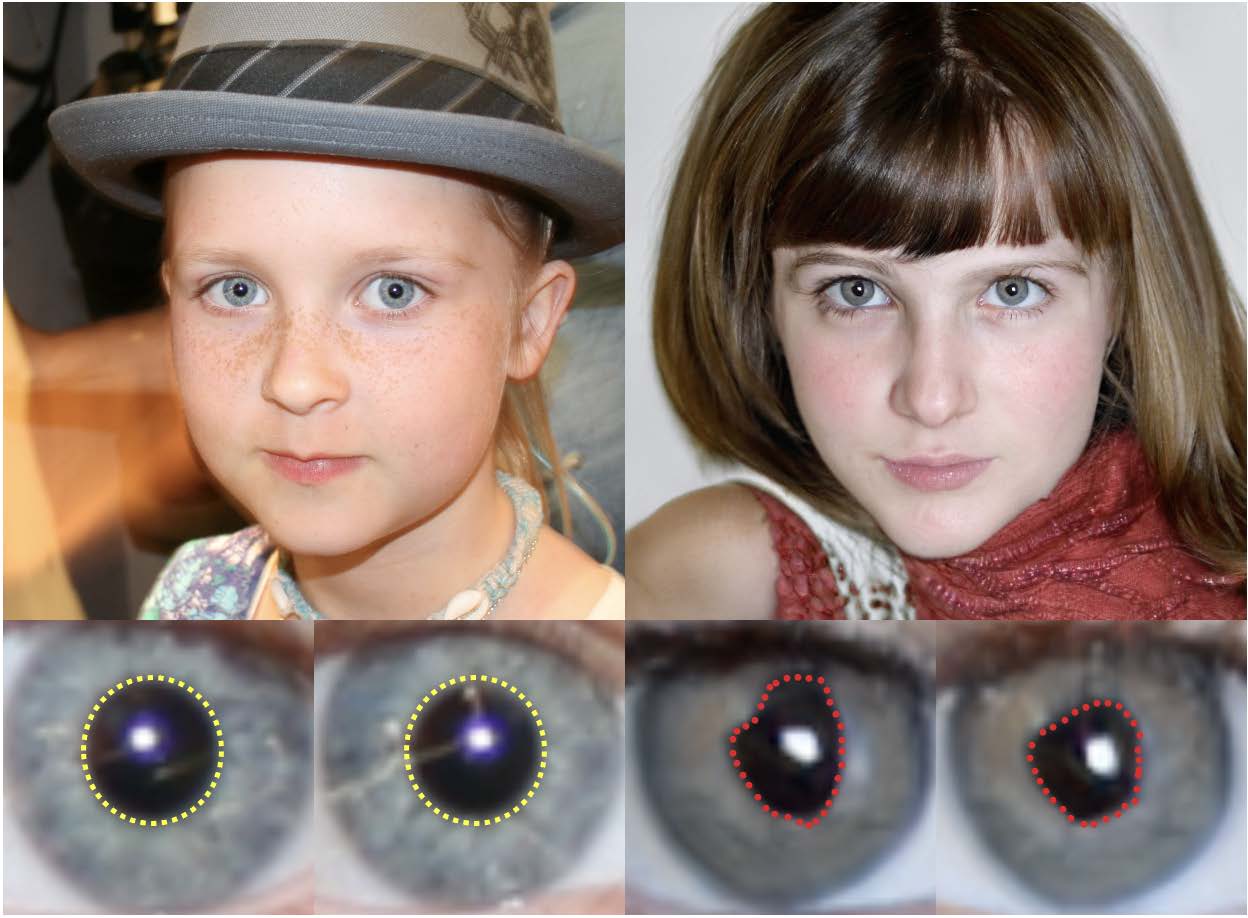
真实的眼睛(左),瞳孔为明显的圆形或椭圆形(黄色);GAN生成的眼睛(右),瞳孔为不规则的形状(红色)。
这种现象普遍存在于GAN生成的人脸上,其中一个根本原因是,目前的GAN模型缺乏对人眼解剖学的理解,特别是瞳孔的几何形状。
方法复现
总结该方法:作者利用模型对两只眼睛的瞳孔进行自动提取,并在之后评估这些瞳孔的形状是否为椭圆形。
1. 瞳孔分割
首先通过人脸检测器来定位人脸,然后用提取器获得人脸的关键点(面部特征点)(如(a)图所示)。我们需要提取瞳孔的ROI区域,故需要根据关键点裁切眼部,对两只眼睛对应的区域进行适当裁剪后可以得到(b)图。
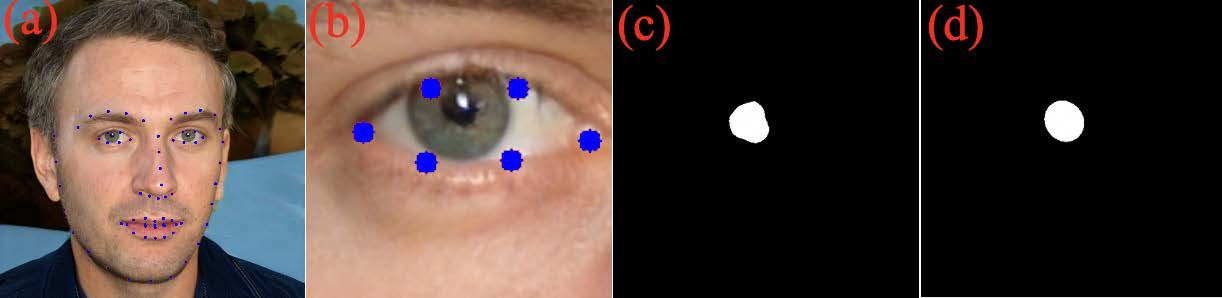
这一步通过多媒体机器学习模型应用框架mediapipe的mediapipe face mesh来实现,该工具可以实时检测和跟踪人脸的 3D 网格关键点
关于MediaPipe Face Mesh
MediaPipe Face Mesh是一种脸部几何解决方案,即使在移动设备上,也可以实时估计468个3D脸部界标(原文提到的dlib方法只能检测出68点)。它采用机器学习(ML)来推断3D表面几何形状,只需要单个摄像机输入,而无需专用的深度传感器。该解决方案利用轻量级的模型架构以及整个管线中的GPU加速,可提供对**实时体验**至关重要的实时性能
mediapipe face mesh的github主页:https://chuoling.github.io/mediapipe/solutions/face_mesh.html可参考博客推荐:
1.1.使用MediaPipe Face Mesh检测跟踪人脸网格关键点的示例代码一
# 调用本机摄像头实时检测 |
1.2.使用MediaPipe Face Mesh检测跟踪人脸网格关键点的示例代码一
# 检测本地视频 |
1.3.根据MediaPipe Face Mesh检测到的关键点裁切出眼部ROI区域
import mediapipe as mp |
结果实例如下,

2.边界检测
获得眼部的ROI后,使用EyeCool提取瞳孔的掩码及其边界。
github源码:https://github.com/neu-eyecool/NIR-ISL2021?tab=readme-ov-file
EyeCool是一个改进的基于U-Net的模型,可以同时对瞳孔和虹膜、内部和外部边界进行分割。其中EfficientNet-B5被用作编码器,并在解码器中添加了一个边界注意块,以提高模型关注物体边界的能力。此外,Dice损失和MSE损失都被用来训练模型,其中Dice损失被用来评估分割部分,MSE被用来计算边界热图的回归损失。
关于EyeCool的一个比赛NIR-ISL-2021:https://sites.google.com/view/nir-isl2021/home、https://github.com/xiamenwcy/NIR-ISL-2021
直接使用EyeCool的开源预训练模型以及
CASIA-Iris-Africa数据集能够将论文中给出的人脸(a)的瞳孔掩码(c)检测出,但是更换人脸后效果不佳开源预训练模型下载(提取码:x3zm):https://pan.baidu.com/share/init?surl=1zHhHryzhOhfJJ8NEPlv-g
2.1.示例代码
实例代码见github仓库neu-eyecool,测试模型文件位于example/model_performance.py中。结果如下
另附命令:
python example/model_performance.py --dataset CASIA-Iris-Africa --ckpath yourPathToPTHFile |
3.椭圆拟合瞳孔
原文中提到椭圆拟合的瞳孔时利用基于最小平方的椭圆拟合方法可用于预测瞳孔掩码的外部边界,以估计椭圆拟合的瞳孔边界。
$u$为预测的瞳孔掩码的外边界上的点的坐标,利用最小二乘法找到一组参数$θ$,使数据点和椭圆之间的距离测量最小:
$$
F(u; \theta) = \theta \cdot u = ax^2 + bxy + cy^2 + dx + ey + f = 0
$$
并通过最小化N个数据点上的代数距离平方之和来确定椭圆的大小:
$$
\mathcal{D}(\theta) = \sum_{i=1}^{N} F(u_i; \theta_i)^2, \ \text{subject to} \ |\theta|^2 = 1 \quad (1)
$$
但是阅读EyeCool的源码后发现:执行example/model_performance.py代码时,EyeCool提取瞳孔的掩码后会调用location/post_process.py文件从预测的瞳孔/虹膜掩码(mask)中提取椭圆边界,故最小平方拟合好像可以重新不用手写新的代码?
4.估算瞳孔形状的不规则性
本文作者使用BIoU来评估距离瞳孔外边界d像素范围内的瞳孔掩码像素。
Boundary IoU(BIoU)可以用来对边界质量敏感的图像分割。相比于平等对待所有像素的Mask IoU,BIoU计算的是预测和基准真相之间的边界轮廓在一定距离内掩码像素的IoU。
借用知乎的图,其中P表示预测的瞳孔掩码,F表示椭圆的瞳孔掩码,参数d是距离边界的距离,控制测量对边界的敏感性。
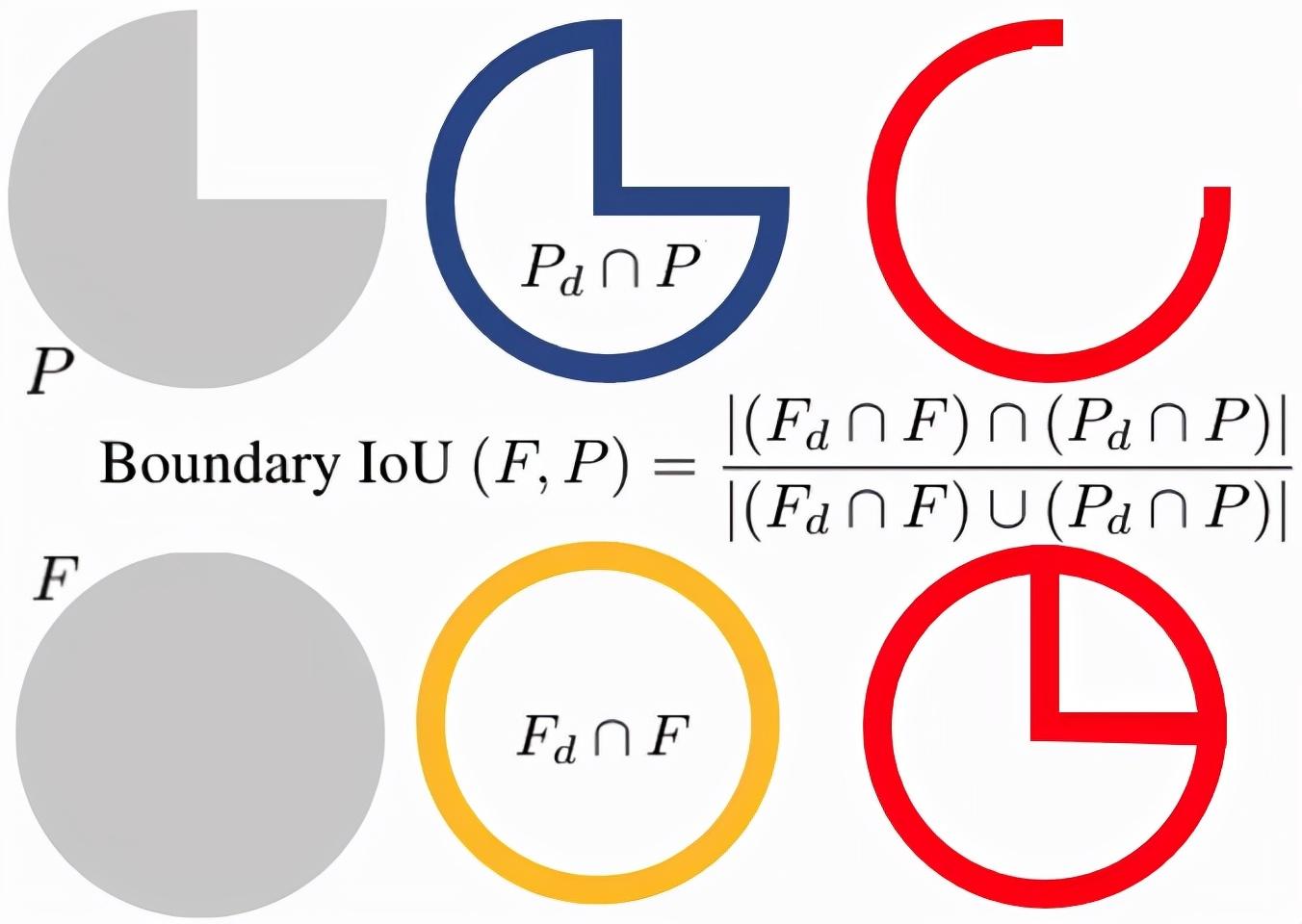
- 左:预测的瞳孔掩码P和椭圆的瞳孔掩码F;
- 中:Pd和Fd是距离边界d以内的掩码像素(蓝色和黄色);
- 右:预测的瞳孔掩码和椭圆修正的瞳孔掩码的距离参数d之间的边界IoU计算。
此外,当把d放大到足以包括掩码内的所有像素时,BIoU就等于掩码IoU。为了使BIoU对边界质量更加敏感,可以减少参数d以忽略掩码内部像素。预测的瞳孔掩码和椭圆的瞳孔掩码之间的BIoU得分的范围是[0, 1],较大的值表明瞳孔的边界与椭圆的形状更相似,那么人脸也更可能是真实的;否则就是用GAN模型生成的。
4.1.BIoU基础知识
BIoU原文:Boundary IoU: Improving Object-Centric Image Segmentation Evaluation
参考中文博客:
https://blog.csdn.net/weixin_50476352/article/details/116615065
https://zhuanlan.zhihu.com/p/395498780
BIoU开源code:
4.2.开源代码部分
# General util function to get the boundary of a binary mask. |
5.完整整合上述分布代码
代码如下,
import os |
最后得到的BIoU值存在test_result/pupil_biou_results.xlsx内。
优化方向
该论文的方法和已有开源模型好像只在论文给出的图片中效果较好,在自己尝试的图片和视频中效果欠佳,需要优化。
- 重新训练EyeCool模型?(😭好像不现实)
- 再找别的真人生物特征检测开源代码








