作业题目
实验1:域名信息收集工具
时间:第2周
地点及方式:教室
人员:全体学生
实验内容:本次实验主要考察大家的编程能力及子域名的信息收集方法,在文件夹“Lab1_code”提供了使用Bing搜索引擎的域名收集功能。请对该代码进行扩展,使其可支持百度搜索引擎的域名收集功能。需要实现如下功能:
**实验报告:**需要提交一份详细的实验报告和截图,来描述做了什么和观察到了什么。还需要对有趣或令人惊讶的观察结果进行解释。还请列出重要的代码片段,然后进行解释。仅附加代码而不作任何解释将不得分。
评分要点:
a) 功能完成情况:60%;
b) 代码规范性:20%;
c) 报告质量:20%
提交方式:
请在学习通作业模块提交,选择对应的作业编号进行提交,请注意:
实验步骤及结果
原始代码使用bing搜索引擎的输出结果如下(原始代码的输出),
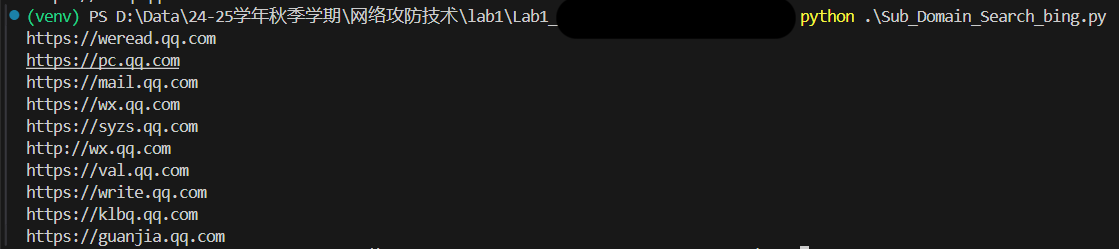
下面介绍拓展的代码部分。
import requests
from bs4 import BeautifulSoup
from urllib.parse import urlparse
def baidu_search():
Subdomain = []
hearders = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/128.0.0.0 Safari/537.36',
'accept': '*/*',
'referer': 'https://www.baidu.com/s?ie=utf-8&f=8&rsv_bp=1&rsv_idx=1&tn=88093251_127_hao_pg&wd=domain%3Aqq.com&fenlei=256&rsv_pq=0xb0ebef1b003e0b45&rsv_t=d009FrprT0AQBXEwtq7%2BuwLwPJN20YC0pdaQfo%2FkzU11n0FQHpr2B30OiGht&rqlang=en&rsv_enter=0&rsv_dl=tb&rsv_n=2&rsv_sug3=1&rsv_btype=i&inputT=2684&rsv_sug4=2685',
'cookie': 'BIDUPSID=BF430F96E98BBB72838AA2BE75F2E4AB'
}
url = "https://www.baidu.com/s?wd=domain%3Aqq.com&rsv_spt=1&rsv_iqid=0xeb03ce41011d24b6&issp=1&f=8&rsv_bp=1&rsv_idx=2&ie=utf-8&rqlang=cn&tn=baiduhome_pg&rsv_enter=1&rsv_dl=tb&oq=domain%253Aqq.com&rsv_btype=t&inputT=2766&rsv_t=22aeYjLLjiQ%2BLdr1%2FTZRucxkBo8gYnEgOvRpHAvCgn1YTTMy2SYkC5XbeSxnJ%2F8x1FNx&rsv_pq=dee5f54704fc63ba&rsv_sug3=15&rsv_n=2&rsv_sug2=0&rsv_sug4=2766"
resp = requests.get(url, headers=hearders)
soup = BeautifulSoup(resp.content,
'html.parser')
job_bt = soup.find_all('div', class_='result c-container xpath-log new-pmd')
for i in job_bt:
link = i.get('mu')
name = i.find('h3').find('a').getText()
domain = str(urlparse(link).scheme + "://" + urlparse(link).netloc)
if ".qq.com" not in domain:
continue
if domain in Subdomain:
pass
else:
Subdomain.append(domain)
print(domain + '\t' + name)
baidu_search()
|
step1
首先需要导入必要的包,代码如下。

step2
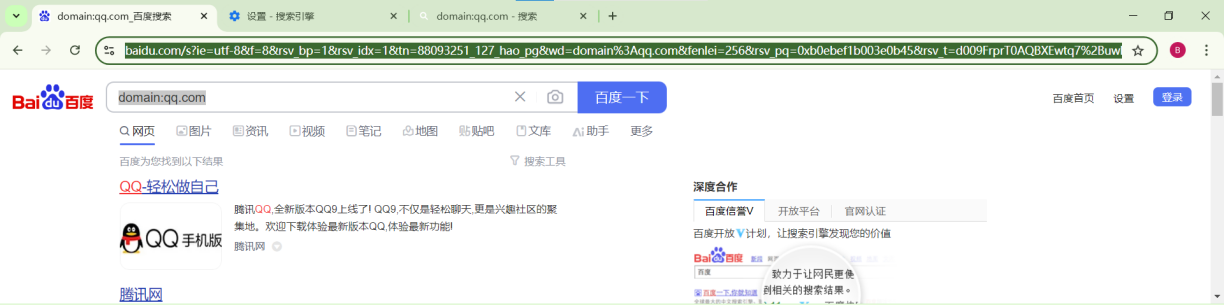
下一步,使用百度搜索引擎,在输入框内输入domain:qq.com,观察网络请求和响应的具体情况,结果如下所示。
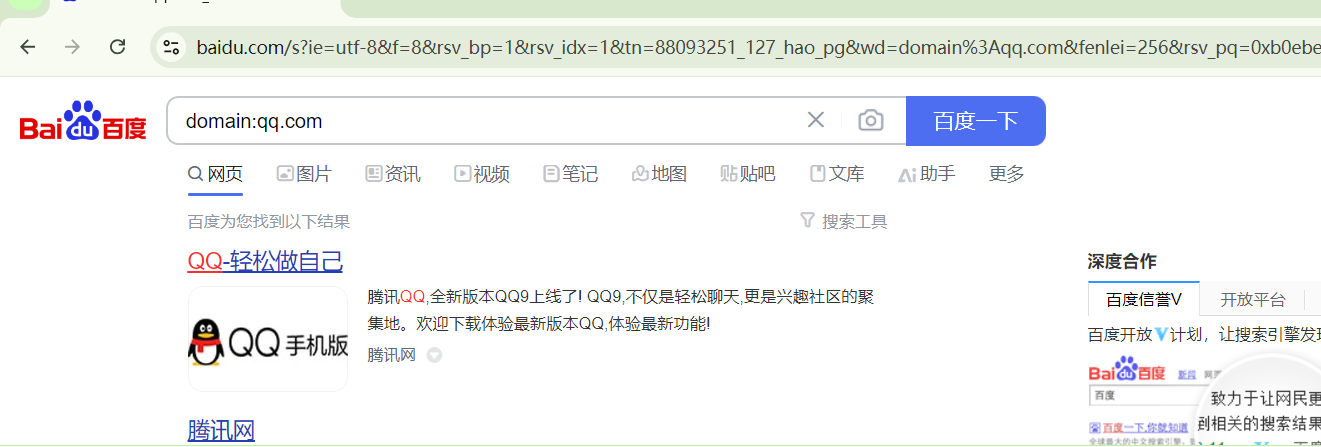
step3
百度服务器会通过对请求头的分析来判断是否为爬虫程序,因此需要伪造请求头;此外还要加入user-agent,accept,referer,cookie字段,这些可以从自己的浏览器获取。
进入浏览器,配置搜索引擎为百度,然后按下f12,查看网络数据,根据网络包的请求头修改headers和url,

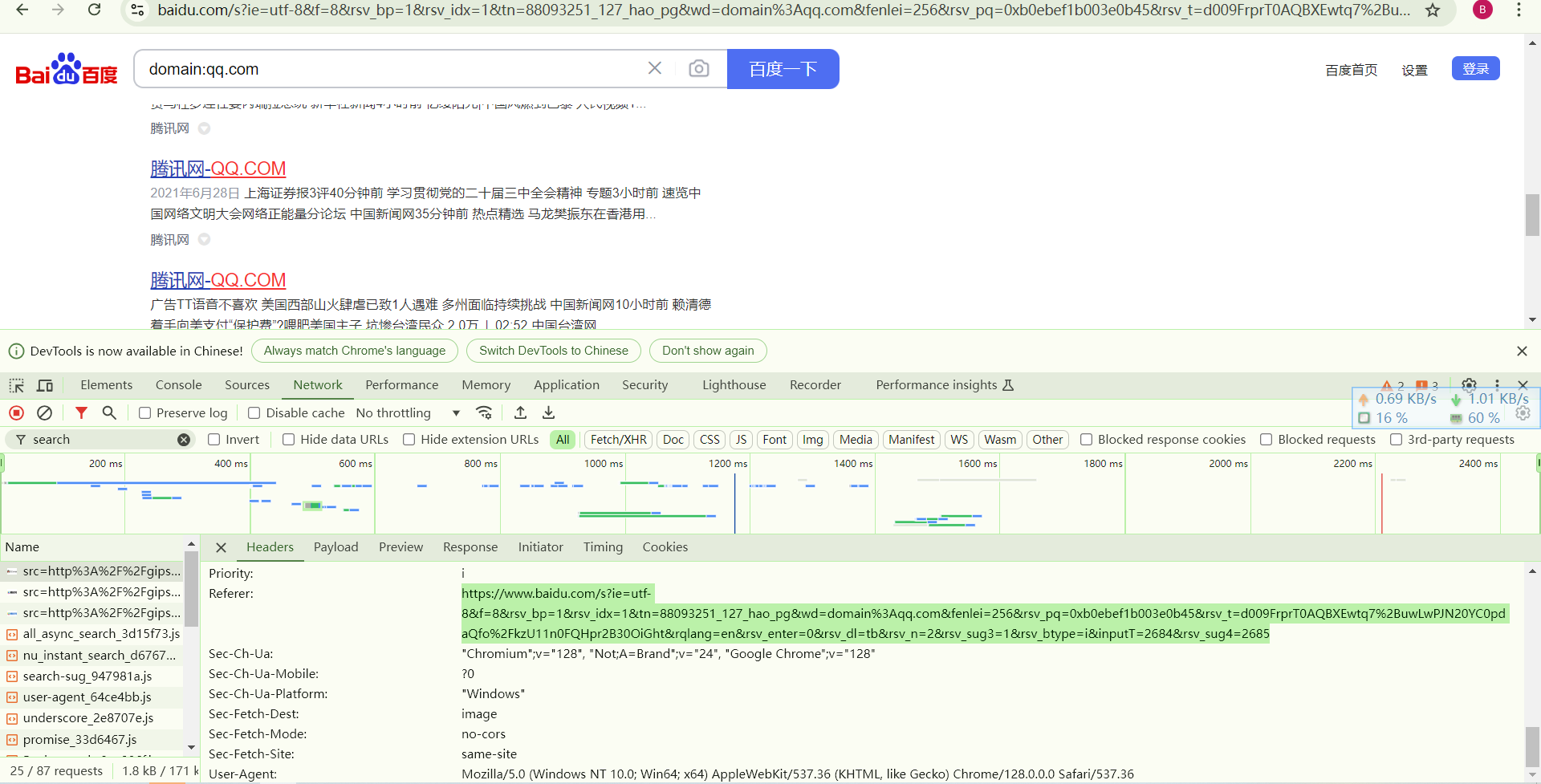
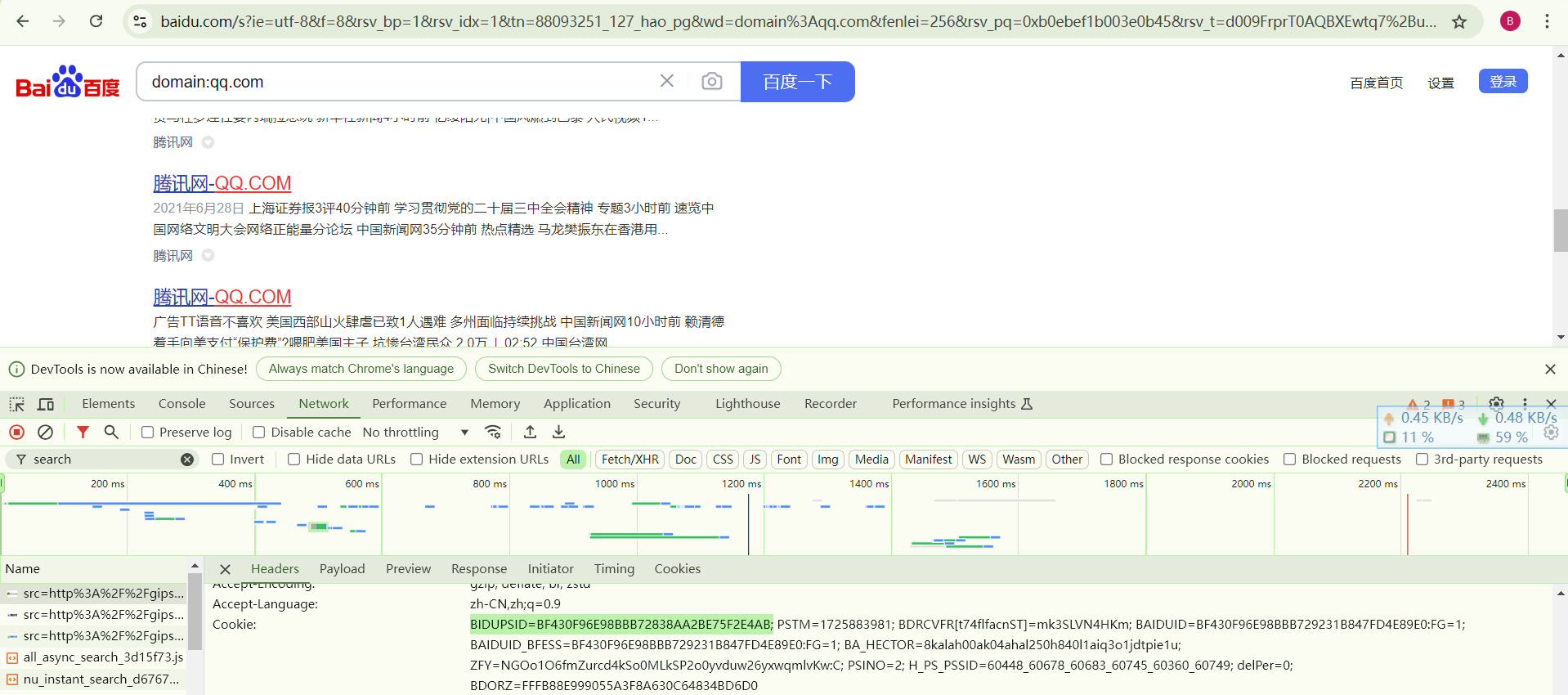


step4
下述代码使用requests库和BeautifulSoup库来抓取网页内容并解析,
第一行使用requests.get方法发送一个GET请求到指定的URL;headers参数用于传递之前定义的请求头,避免被网站的反爬虫机制拦截。
下一行BeautifulSoup库来解析服务器响应的内容(即网页源码);html.parser是指定的HTML解析器,用于解析HTML文档。

step5
通过f12查看网页源码,然后可以在页面中选择元素进行审查,然后通过选择来定位域名url的具体位置。
需要注意的是下面带有href标签的代码是百度的域名跳转链接,而上面的 div class=”result c-container xpath-log new-pmd”标签下的 mu 内容才是真正的 url。
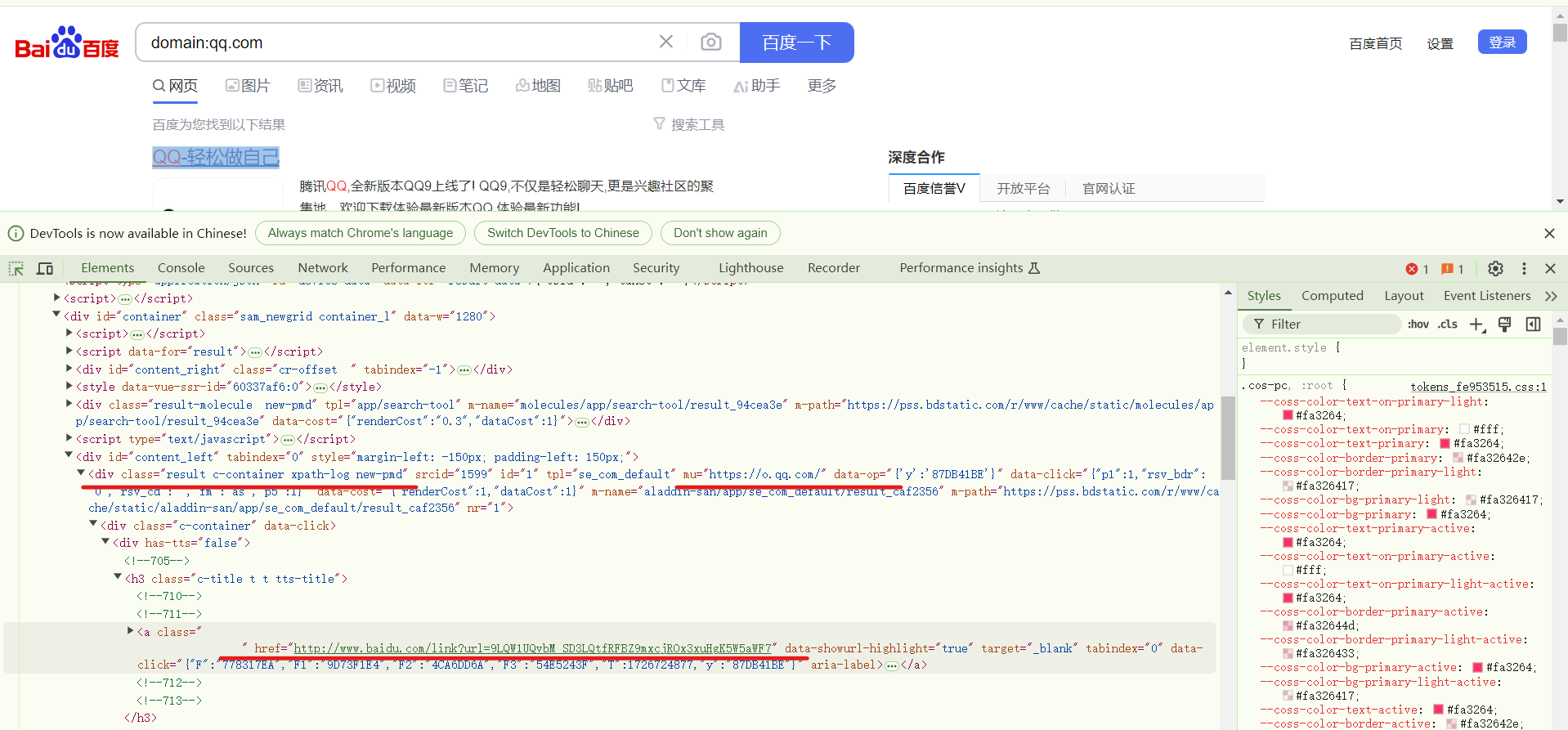
可以发现使用百度搜索引擎搜索domain:qq.com时的源代码和在bing搜索domain:qq.com时的代码存在不同,需要在原有的bing_search()函数的基础上,修改某些参数换成百度搜索引擎中的,即把h2换成h3。然后就可以定位域名url的位置(如上图红色下划线所示),从格式化数据中搜索获取url和title。
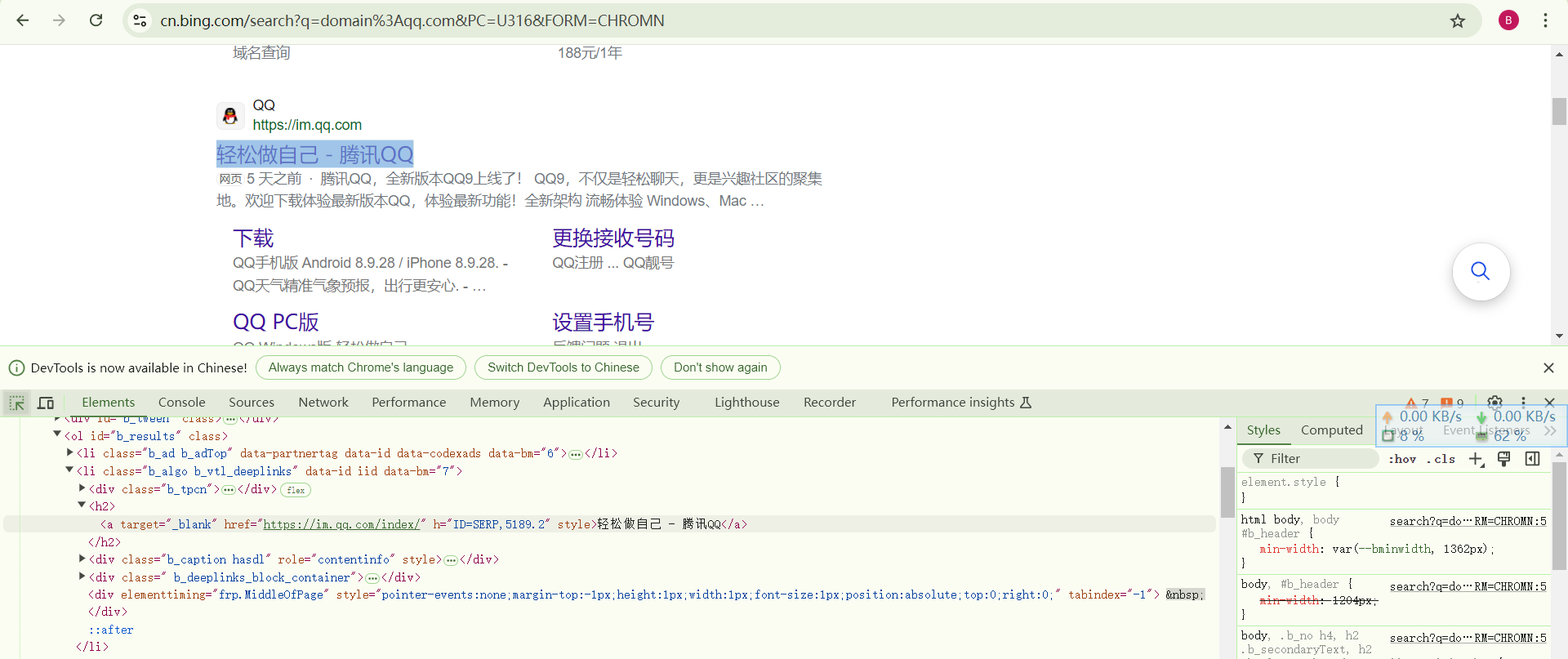
另附下图,下图为使用bing搜索引擎的结果,标签是h2与百度不同。
step6
然后为了实现功能要求中的显示域名所在的标题等信息功能,在bing_search函数的基础上修改代码,结果如下,
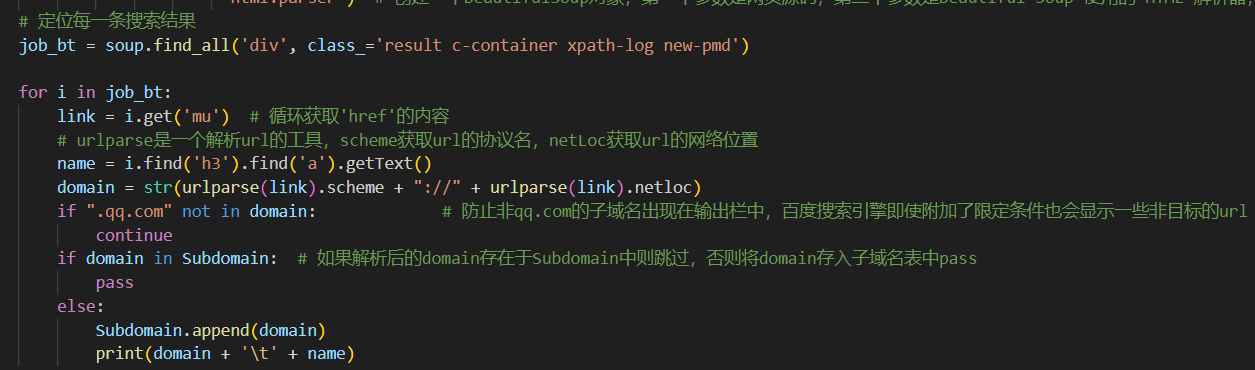
首先修改 soup 方法里的参数,这一行代码使用BeautifulSoup库的find_all方法来查找所有具有result c-container xpath-log new-pmd类名(从上方百度搜索引擎的源代码标签内得知)的div元素,然后存储在变量job_bt中。注意这里的 class 后面要加下划线“_“,否则会出现问题。
for循环语句内的第一行代码尝试从当前遍历的div元素中获取一个名为mu的属性值,这个值被用于获取URL。
接下来继续扩充增加域名标题的功能,检查源代码,发现网页标题在<h3>标签下的<a>标签中,如下图所示。而获取标签中的内容可以用 getText()方法。下一行代码查找当前div元素下的h3标签,然后在这个h3标签下查找a标签,并获取a标签的文本内容,这个文本内容是网站的标题。
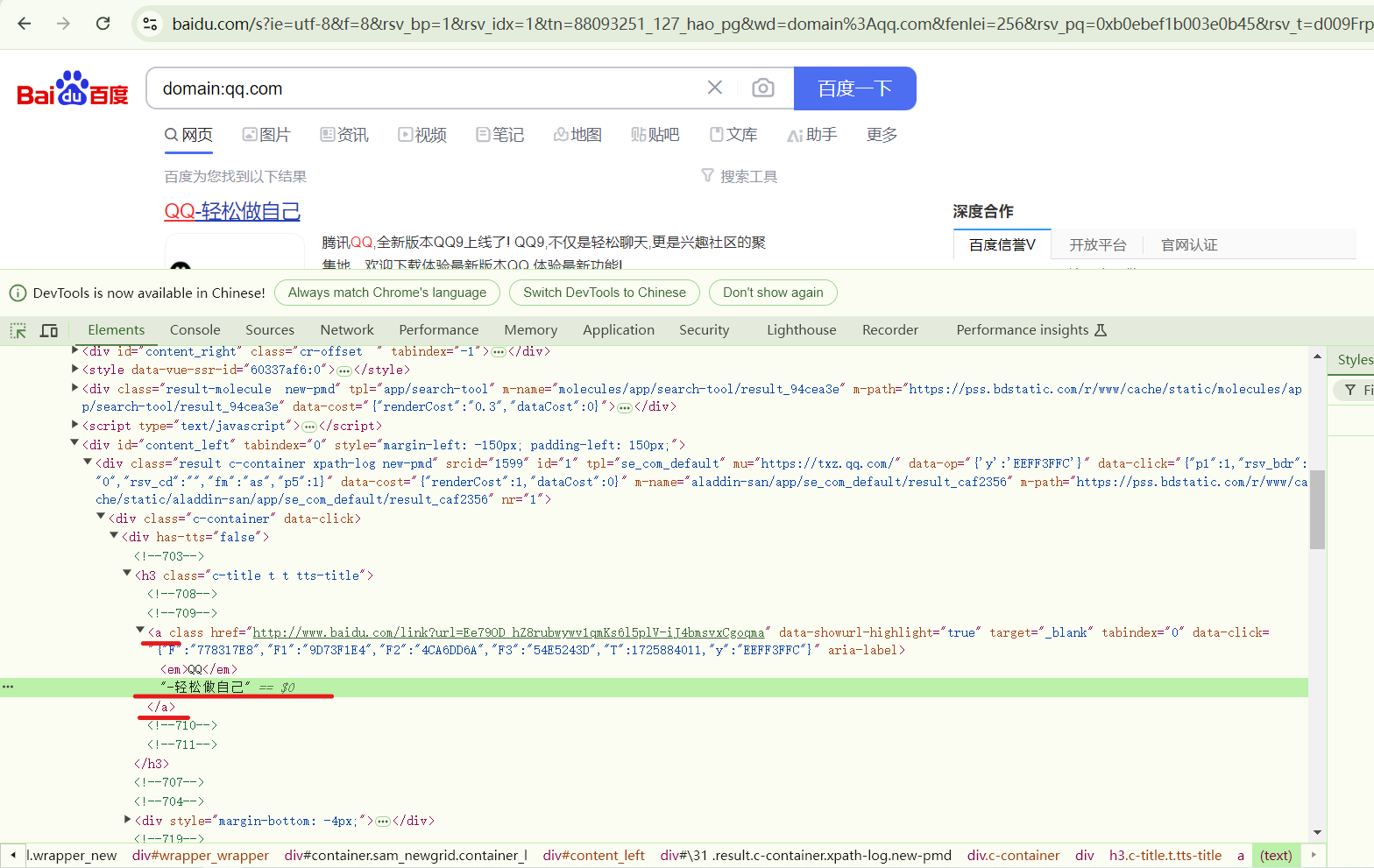
接下来的代码使用urlparse函数来解析link变量中的URL,提取出协议(scheme)和网络位置(netloc),并组合成完整的域名。
下一个判断语句目的是防止非qq.com的子域名出现在输出栏中,百度搜索引擎即使附加了限定条件也会显示一些非目标的url,因此需要筛选出不符合要求的域名。(仅使用qq.com的筛选条件的话可能仍然会把一些非要求域名显示出来,例如imqq.com,所以筛选条件要设置为.qq.com)
我们还需要判断这个域名是否为未曾出现的子域名,若是则加入列表内,然后输出。
step7
输出结果如下所示,

另外附上浏览器页面,(一些非qq.com的域名都被筛选出去了并未显示在输出框内)

功能拓展-翻页
代码详见压缩包内的Sub_Domain_Search_baidu2.py文件
import requests
from bs4 import BeautifulSoup
from urllib.parse import urlparse
import urllib
import urllib.error
import re
import time
def baidu_search():
Subdomain = []
hearders = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/128.0.0.0 Safari/537.36',
'accept': '*/*',
'referer': 'https://www.baidu.com/s?ie=utf-8&f=8&rsv_bp=1&rsv_idx=1&tn=88093251_127_hao_pg&wd=domain%3Aqq.com&fenlei=256&rsv_pq=0xb0ebef1b003e0b45&rsv_t=d009FrprT0AQBXEwtq7%2BuwLwPJN20YC0pdaQfo%2FkzU11n0FQHpr2B30OiGht&rqlang=en&rsv_enter=0&rsv_dl=tb&rsv_n=2&rsv_sug3=1&rsv_btype=i&inputT=2684&rsv_sug4=2685',
'cookie': 'BIDUPSID=BF430F96E98BBB72838AA2BE75F2E4AB'
}
for j in range(0,5):
j = str(j)
url = "https://www.baidu.com/s?wd=domain%3Aqq.com&pn=" + j + "0&rsv_spt=1&rsv_iqid=0xeb03ce41011d24b6&issp=1&f=8&rsv_bp=1&rsv_idx=2&ie=utf-8&rqlang=cn&tn=baiduhome_pg&rsv_enter=1&rsv_dl=tb&oq=domain%253Aqq.com&rsv_btype=t&inputT=2766&rsv_t=22aeYjLLjiQ%2BLdr1%2FTZRucxkBo8gYnEgOvRpHAvCgn1YTTMy2SYkC5XbeSxnJ%2F8x1FNx&rsv_pq=dee5f54704fc63ba&rsv_sug3=15&rsv_n=2&rsv_sug2=0&rsv_sug4=2766"
resp = requests.get(url,headers=hearders)
soup = BeautifulSoup(resp.content,'html.parser')
job_bt = soup.find_all('div', class_='result c-container xpath-log new-pmd')
for i in job_bt:
try:
link = i.get('mu')
name = i.find('h3').find('a').getText()
domain = str(urlparse(link).scheme + "://" + urlparse(link).netloc)
if ".qq.com" not in domain:
continue
if domain in Subdomain:
pass
else:
Subdomain.append(domain)
print(domain + '\t' + name)
except urllib.error.HTTPError as e:
if e.code == 500:
pass
else:
print('HTTPError:', e.code)
pass
except urllib.error.URLError as e:
print('URLError:', e.reason)
pass
except Exception as e:
print('Error:', str(e))
pass
time.sleep(2)
print("-------------------------------------------------------已爬取页数:" + str(j))
baidu_search()
|
代码如下,
<img src="https://raw.githubusercontent.com/Hozenghan/blogResources/master/scu_images/image-20240919195128212.png" alt="image-20240919195128212" style="zoom:67%;" />
- ```j```的```for```循环通过变量```j```来构建用于搜索的URL,其中 `pn` 参数控制搜索结果的偏移量。```pn=00```表示第一页,```pn=10```则表示第二页,其中```pn=00```往往省略不写,其他变量```resp```、```soup```、```job_bt```保持不变,
<img src="https://raw.githubusercontent.com/Hozenghan/blogResources/master/scu_images/image-20240919195528376.png" alt="image-20240919195528376" style="zoom:67%;" />
<img src="https://raw.githubusercontent.com/Hozenghan/blogResources/master/scu_images/image-20240919195537501.png" alt="image-20240919195537501" style="zoom:70%;" />
- 有些网站因为停止维护或网络问题无法访问,为了不让程序停止运行,使用抛出异常机制进行处理。上述代码使用 `try-except` 块来捕获并处理可能发生的异常,逻辑大体如下所示,
```python
try:
# 尝试执行的代码块
except urllib.error.HTTPError as e:
# 处理HTTP错误
except urllib.error.URLError as e:
# 处理URL错误
except Exception as e:
# 处理其他异常
|

结果如下所示,通过设置j的循环数可以实现爬取多个页面的效果,
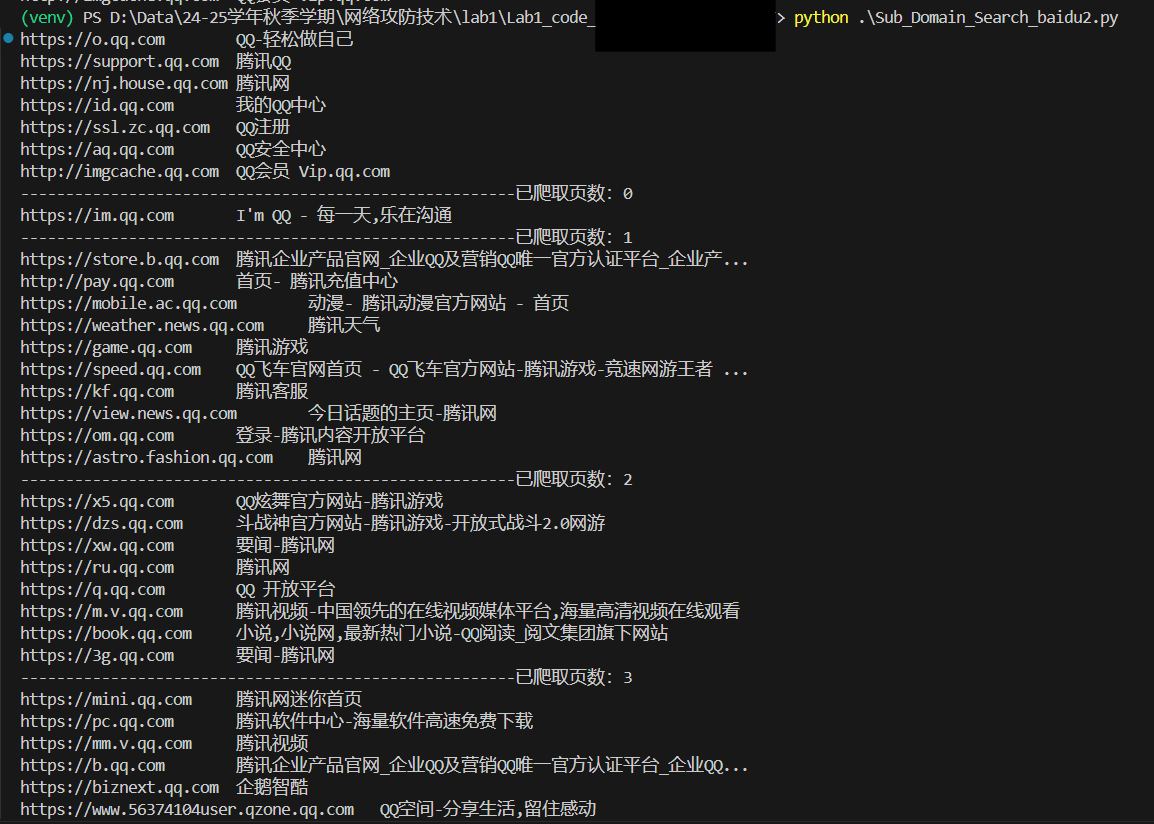
发现
一、显然,修改url变量的值会导致输出结果的不同,这是因为url的不同会使请求不同。而且不同搜索引擎的结果会不同,这应该涉及每个搜索引擎的查找算法,不同的算法导致不同的结果。
二、原始代码仅能爬取单一页面的域名(无法翻页),而且不能指定主域名,需要修改源代码才能更换要爬取的子域名。
三、百度搜索引擎在搜索子域名的时候也会把一些无关的网页选出并展示(即domain的限定条件有时候会失效,需要加以限制否则会出现错误),所以需要附加限定条件。
四、当爬取多页的时候,可以在爬取的时候设置一定的睡眠时间,例如time.sleep(2),否则较快的访问请求会增大被服务器拒绝的风险,触发防爬机制。
参考资料
Python中BeautifulSoup库的用法-CSDN博客
Python requests 模块 | 菜鸟教程 (runoob.com)
网络爬虫与反爬 - Tate & Snow (tate-young.github.io)
https://sec-wiki.com/news/search?wd=%E4%BF%A1%E6%81%AF%E6%94%B6%E9%9B%86
https://blog.csdn.net/qq_25834767/article/details/104532493
https://mp.weixin.qq.com/s/votEOvJafPjCka7gIB8DEA
浏览器–常用的搜索操作符大全–使用/实例-CSDN博客
可能是最全的 Python 反爬虫及应对方案了-CSDN博客










